CubeFS
CubeFS | A Cloud Native Distributed Storage System
简介
CubeFS是新一代云原生存储产品,目前是CNCF托管的孵化阶段开源项目,兼容S3,POSIX、HDFS等多种访问协议,支持多副本与纠删码为用户提供多租户、 多AZ部署以及跨区域复制等多种特性,广泛应用于大数据、AI、容器平台、数据库、中间件存算分离、数据共享以及数据保护等场景。
多协议
兼容S3、POSIX、HDFS等多种访问协议,协议间访问可互通
- POSIX兼容:兼容POSIX接口,让上层应用的开发变得极其简单,就跟使用本地文件系统一样便捷。此外,CubeFS在实现时放松了对POSIX语义的一致性要求来兼顾文件和元文件操作的性能。
- 对象存储兼容:兼容AWS的S3对象存储协议,用户可以使用原生的Amazon S3 SDK管理CubeFS中的资源。
- Hadoop协议兼容:兼容Hadoop FileSystem接口协议,用户可以使用CubeFS来替换Hadoop 文件系统( HDFS ),做到上层业务无感。
双引擎
支持多副本及纠删码两种引擎,用户可以根据业务场景灵活选择
- 多副本存储引擎:副本之间的数据为镜像关系,通过强一致的复制协议来保证副本之间的数据一致性,用户可以根据应用场景灵活的配置不同副本数。
- 纠删码存储引擎:纠删码引擎具备高可靠、高可用、低成本、支持超大规模(EB)的特性,根据不同AZ模型可以灵活选择纠删码模式。
多租户
支持多租户管理,提供细粒度租户隔离策略
可扩展
可轻松构建PB或EB规模的分布式存储服务,各模块可水平扩展
高性能
支持多级缓存,针对小文件特定优化,支持多种高性能复制协议
- 元数据管理:元数据集群为内存元数据存储,在设计上使用两个B-Tree(inodeBTree与dentryBTree)来管理索引,进而提升元数据访问性能;
- 强一致副本协议 :CubeFS根据文件写入方式的不同采用不同的复制协议来保证副本间的数据一致性。(如果文件按照顺序写入,则会使用主备复制协议来优化IO吞吐量;如果是随机写入覆盖现有文件内容时,则是采用一种基于Multi-Raft的复制协议,来确保数据的强一致性);
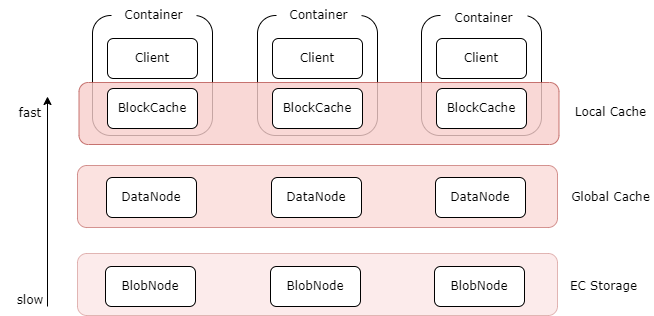
- 多级缓存
:纠删码卷支持多级缓存加速能力,针对热点数据,提供更高数据访问性能:
- 本地缓存:可以在Client机器上同机部署BlockCache组件,将本地磁盘作为本地缓存. 可以不经过网络直接读取本地Cache, 但容量受本地磁盘限制;
- 全局缓存:使用副本组件DataNode搭建的分布式全局Cache, 比如可以通过部署客户端同机房的SSD磁盘的DataNode作为全局cache, 相对于本地cache, 需要经过网络, 但是容量更大, 可动态扩缩容,副本数可调。
技术架构
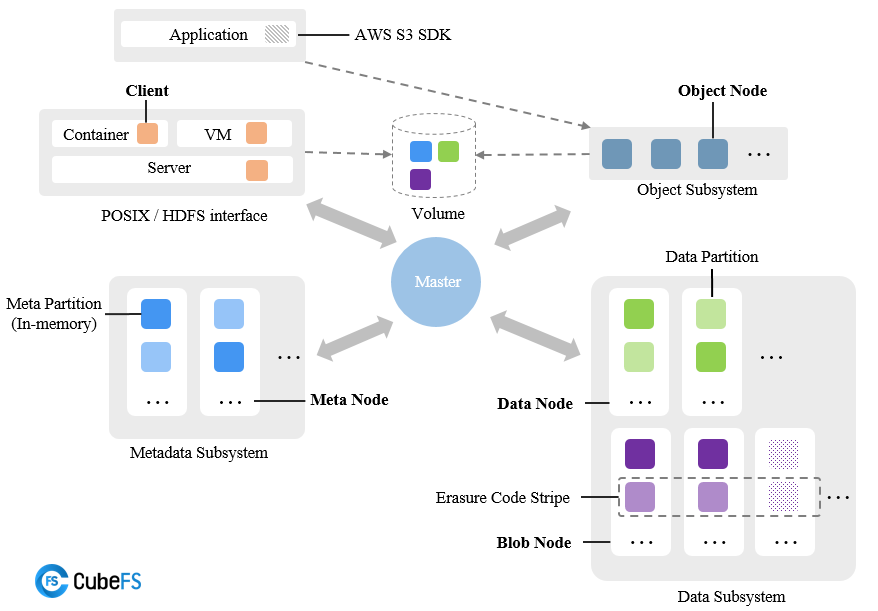
CubeFS由 元数据子系统(Metadata Subsystem) ,数据子系统(Data Subsystem) 和 资源管理节点(Master) 以及 对象网关(Object Subsystem) 组成,可以通过POSIX/HDFS/S3接口访问存储数据。
- 资源管理节点:有多个Master节点组成,负责异步处理不同类型的任务,如管理数据分片与元数据分片(包括创建、删除、更新一级一致性检查等),检查数据节点或者元数据节点的健康状态,维护管理卷信息等(Master节点可以有多个,节点之间通过Raft算法保证元数据的一致性,并且持久化到RocksDB中。)
- 元数据子系统:由多个Meta Node节点组成,多个元数据分片(Meta Partition)和Raft实例(基于Multi-Raft复制协议)组成, 每个元数据分片表示一个Inode范围元数据,其中包含俩颗内存B-Tree数:inode BTree与dentry BTree。(元数据实例最少三个,支持水平扩容)
数据子系统:分别为副本子系统和纠删码子系统,俩种子系统可以同时存在,也都可单独存在:(数据节点支持水平扩容)
- 副本子系统由dataNode组成,每个节点管理一组数据分片,多个节点的数据分片构成一个副本组;
- 纠删码子系统(Blobstore)主要由BlobNode模块组成,每个节点管理一组数据块,多个节点的数据块构成一个
- 对象子系统:由对象节点(Object Node)组成,提供了兼容标准S3语义的访问协议,可以通过Amazon S3 SDK或者是s3cmd等工具访问存储资源。
- 卷:逻辑上的概念,由多个元数据和数据分片组成,从客户端的角度看,卷可以被看做是容器访问的文件系统实例。从对象存储的角度来看,一个卷对应着一个bucket。一个卷可以在多个容器中挂载,使得文件可以被不同客户端同时访问。