操作系统文件协议
POSIX

POSIX:PotableOperating SystemInterface of Unix(可移植操作系统接口),是IEEE为要在各种Unix操作系统上运行软件而定义API的一系列互相关联的标准总称,其正式称呼为IEEE Std 1003,而国际标准名称为ISO/IEC 9945。
POSIX标准定义了UNIX操作系统为应用程序提供的接口标准,是为了提升应用程序在不同UNIX操作系统之间的代码可移植性。POSIX之定义接口,不定义具体实现,即定义了头文件*.h而源文件*.c或哭文件由各个提供商提供
POSIX是标准C的超集,意味着标准C的函数都属于POSIX,可以直接使用这些函数,比如stdio.h中的printf、scanf,pthread.h中的pthread_create等
其他协议
| 协议 | 概述 | 典型应用场景 | 访问方式 | 优缺点 |
|---|---|---|---|---|
| POSIX | 可移植操作系统接口POSIX(Portable Operating System Interface),定义了操作系统应该为应用程序提供的接口标准,是IEEE为要在各种UNIX操作系统上运行的软件而定义的一系列API标准的总称。 | 将客户端程序文件迁移到存储系统,可直接运行。 | 通过POSIX协议共享,可以授权对应的主机端访问共享存储。无需挂载,开启后可直接访问。 | |
| NFS | 网络文件系统NFS(Network File System),是 FreeBSD 支持的一种分布式文件系统协议。 | 主要应用在 Linux、UNIX环境中。 | 将服务端的共享文件挂载到客户端,在客户端像访问本地文件一样访问即可。 | 优点:内核直接支持,部署简单、运行稳定,协议简单、传输效率高。<br/>缺点:没有加密授权等功能,仅依靠 IP 地址或主机名来决定用户能否挂载共享目录,对具体目录和文件无法进行 ACL 控制。 |
| CIFS | 通用Internet文件系统CIFS(Common Internet File System)是公开或开放的SMB协议版本,是由微软开发主要用于连接 Windows 客户端与服务器的文件共享协议。该协议允许客户端对文件进行操作,就好像在本地计算机上,例如读、写、创建、删除、重命名等操作。 | 用主要应用于连接 Windows 客户端与服务器。 | windows:通过配置映射的网络文件夹实现共享。<br/>Linux:将服务端的共享文件挂载到客户端,在客户端像访问本地文件一样访问即可。 | 优点:支持多入口、多出口技术环境以及有多个节点和路径集合的网络。同时,它可以在不同客户端和服务器之间进行数据共享,支持跨防火墙的数据传输和连接,能够将不同的操作系统的文件或数据封装在一起。<br/>CIFS具有良好的文件共享和权限控制功能,适用于多用户同时存取和修改文件的环境,可以有效的提高文件访问的安全性,也能够支持高效的文件服务。<br/>缺点:CIFS 面向网络连接的共享协议,对网络传输的可靠性要求高;受故障影响大,无法自行恢复交互过程 |
| FTP | 文件传输协议FTP(File Transfer Protocol)是一种在不同操作系统之间传输和共享文件的网络协议。FTP的传输过程就是一个上传和下载的过程,并不适用于服务器上文件修改。因为 FTP 通常需要先获取远程文件的副本,然后对副本修改,最后再将修改后的文件副本上传服务器。 | 使用 “FTP://服务器IP地址”来直接访问站点下载资料。 | 在FTP(S)客户端中输入正确的用户名和密码登录成功后,即可根据该用户具有的 FTP 共享权限在共享目录中执行相应的操作,如查看文件列表、创建文件夹、上传文件、下载文件、删除文件和重命名等。 | 优点:跨平台、简单易用<br/>缺点:数据传输和工作方式不合理,安全认证不完善,传输效率低下 |
| HTTP | 超文本传输协议HTTP(Hypertext Transfer Protocol)是一个属于应用层的面向对象的协议,用户通过HTTP协议进行文件的下载和浏览操作。 | 使用 “http://服务器IP地址”来直接访问站点下载或查看文件。 | 在浏览器中访问http://共享IP:端口/共享目录/,即可查看和下载共享的文件。 | 优点:跨平台、简单易用、灵活性高<br/>缺点:安全性差、无状态 |
纠删码ErasureCode
纠删码(erasure code)介绍 - 知乎 (zhihu.com)
纠删码(Erasure Code)及其演进LRC(Locally Repairable Codes)原理讲解_lrc纠删码-CSDN博客
简介
纠删码是一种错误纠正技术(Fower Error Correction,FEC)主要应用在网络传输中避免包的丢失,存储系统利用它来提高存储可靠性。相比多副本复制而言,纠删码 能够以更小的数据冗余获得更高的数据可靠性,但是编码方式比较复杂需要大量计算。纠删码只能容忍数据丢失,无法容忍数据篡改,纠删码正式得名于此。
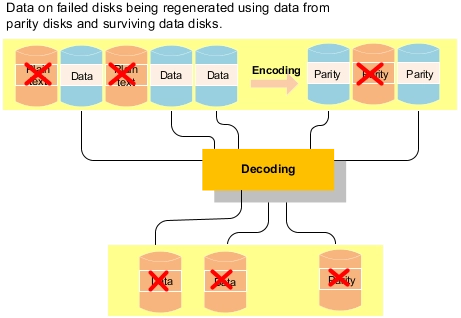
原理
总数据块=原始数据块+校验块
n=k+m
允许故障:任意m个块,包括原始数据和校验块
从K个原始数据中计算出m个校验块。
将这k+m个数据块分别存放在k+m个硬盘上,就能容忍m个硬盘故障。
n=k+m
k值影响数据恢复代价。K值越小,数据分散度越小,故障影响面越大,重建代价也就越大;k值越大,多路数据拷贝的网络和磁盘负载越大,重建代价也越大。
m值影响可靠性与存储成本。取值大,故障容忍度越高;m取值小,数据冗余低。再俩者之间权衡。
k取值有时候也和数据块对其,k/m按照磁盘故障率来选择。
Read-Solomon(RS)码
纠删码技术(Erasure coding)简称EC,是一种编码容错技术。最早用于通信行业,数据传输中的数据恢复。它通过对数据进行分块,然后计算出校验数据,使得各个部分的数据产生关联性。当一部分数据丢失时,可以通过剩余的数据块和校验块计算出丢失的数据块
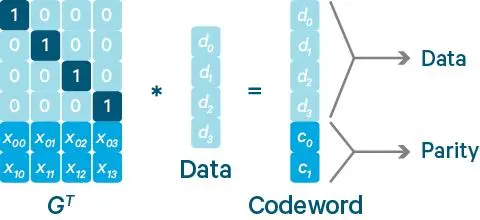
里德-所罗门码 Reed-Solomon(RS)码是存储系统较为常用的纠删码,它有俩个参数k和m,记为RS(k,m)。如下图所示,k个数据块组成一个向量被乘上一个生矩阵(Generator Matrix)GT从而得到一个码字(codeword)向量,该向量由k个数据块和m个校验块构成。如果一个数据块丢失,可以用(GT)-1乘以码字向量来恢复丢失的数据块。RS(k,m)最多可容忍m个块(包括数据块和校验块)丢失。
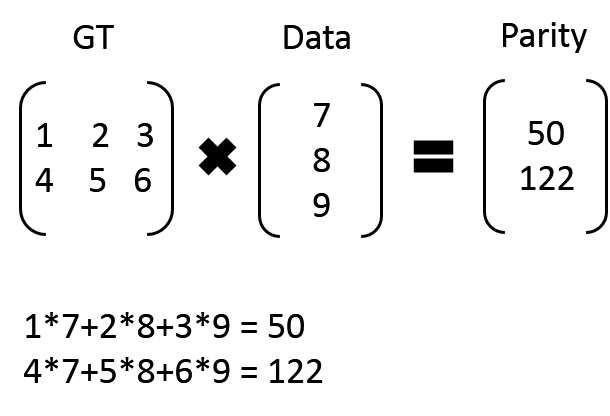
比如:我们有7、8、9三个原始数据,通过矩阵乘法,计算出来俩个校验数据50、122。这时候原始数据加上校验数据,一共五条数据7、8、9、50、122,可以任意丢弃俩个然后通过计算进行回复。
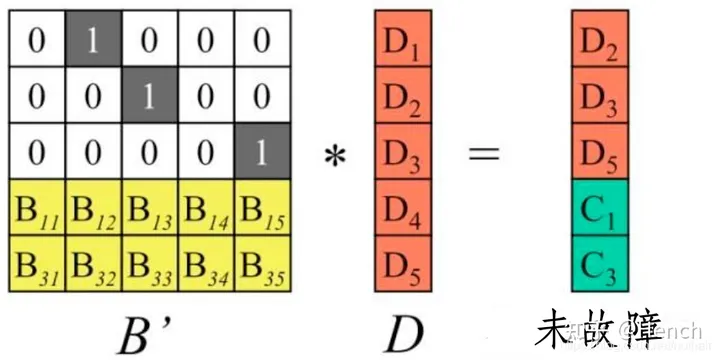
以冗余级别为5+3的纠删码为例说明。将n个源数据块D1~Dn按列排成向量D,再构造一个(n+m)n矩阵B,B称为分布矩阵。对矩阵B有一个要求:它的任意n个行向量都是相互独立的,即这n个行向量组成的nn矩阵可逆。执行矩阵向量乘B*D,得到m个校验块C1~ Cm
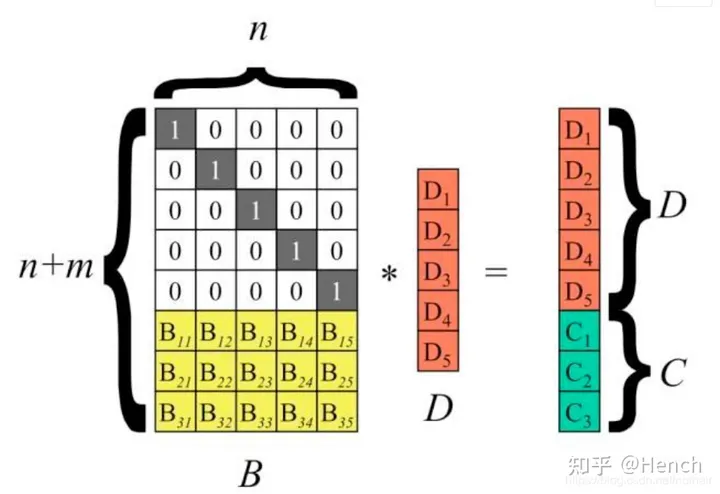
假设m个硬盘发生了故障,即图4中的数据块D1、D4、C2丢失,需要从剩下的n个数据块中恢复出来源数据D1~Dn
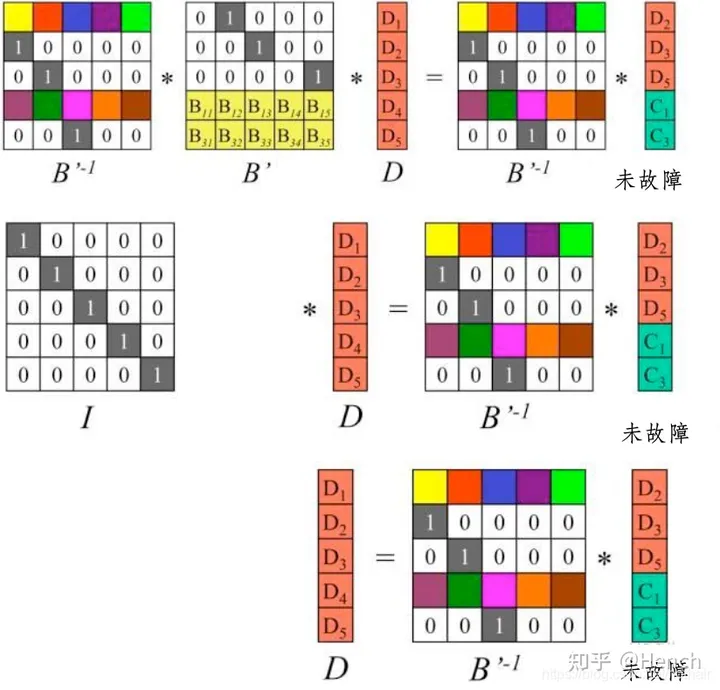
从矩阵B中将剩余数据块对应的行向量挑出来,组成新矩阵B’,B’乘以向量D的结果恰好是未故障的数据块
因为B的任意n行组成的矩阵都可逆,所以矩阵B’存在逆矩阵,记为B’-1,显然有B’-1 * B’=E(单位矩阵乘任何矩阵B都等于B)
左右两边同时左乘矩阵B’-1,就得到了n个源数据块D1~Dn,完成数据恢复.
LRC
LRC(Locally Repairable Codes),是一种局部校验编码方法,其核心思想为:将校验块(parity block)分为全局校验块(global parity)、局部校验块(local reconstruction parity)故障恢复时分组计算。
根据LRC的思想我们将上面的例子重新进行一番改造,分成俩个组
P1=D1+D2
P2=D3+D4
P3= D1+D2+ D3+D4
P1、P2是局部校验。P3是全局校验。
当仅损坏一个数据块时,可以根据该数据在所在的分组,在组内对该数据块进行重建。损坏一个数据块时的最差情况就是全局校验块损坏,此时需要读全部数据块数据进行重建。
当损坏两个数据块时情况分成组内和组外,不管哪种需要拉取全部数据进行重建,此时采用LRC方法并不能提升性能。
假设有四块:D1,D2,D3,D4,校验数据两块P1,P2.组成下面方程组:
当损坏三块数据时,如果这三个数据块在一个组内,例如P1、D1、D2。此时就无法进行数据重建,虽然我们这里是使用三个校验。
所以LRC并不是100%保证数据不丢,并且还要多占用一部分存储空间,一切事情都是有两面性的,顾此就要失彼,但是总的来说LRC还是很有竞争力的技术。
条形布局(striping layout)
条(stripe)是由若干个相同大小的单元(cell)构成的序列。文件数据被一次写入条的各个单元中,当一个条写满之后再写入下一个条,一个条的不同单元位于不同的数据块中。这种布局方式称为条形布局。
优点:客户端缓存数据较少,无论文件大小都适用
缺点:会影响一些位置铭感任务的性能,因为原先在一个节点上的快被分散到了多个不同的节点上,和多副本策略转换比较麻烦。

优势
可靠性:可靠性是根据容错能力来衡量的,即可以在不丢失数据的情况下持续发生故障的数量。通过复制,多个相同副本会存储在不同的节点上一级不同的站点上。通过纠删码,对象会编码为数据和奇偶校验片段,并分布在多个节点和站点上。这种分散方式可同时提供站点和节点故障保护。与复制相比,就删吗提高可靠性,而存储成本相当。
可用性,可用性定义为存储节点出现故障或无法访问时检索对象的功能。与复制相比,纠删码可以以相当的存储成本提高可用性。
存储效率:相对于相似级别的可用性和可靠性,通过纠删码保护对象比通过复制保护的相同对象占用的磁盘空间更少。例如,复制到两个站点的 10 MB 对象会占用 20 MB 的磁盘空间(两个副本),而采用 6+3 纠删编码方案在三个站点之间进行纠删编码的对象只会占用 15 MB 的磁盘空间。
注: 擦除编码对象的磁盘空间计算为对象大小加上存储开销。存储开销百分比是奇偶校验片段数除以数据片段数。
缺点
与复制相比,纠删编码具有以下缺点:
- 需要增加存储节点和站点的数量。例如,如果您使用的纠删编码方案为 6+3 ,则必须在三个不同的站点上至少有三个存储节点。相比之下,如果只复制对象数据,则每个副本只需要一个存储节点。
- 在分布在不同地理位置的站点之间使用纠删编码时,检索延迟会增加。与在本地复制并提供的对象(客户端连接的同一站点)相比,通过 WAN 连接检索经过纠删编码并分布在远程站点上的对象的对象片段所需时间更长。
- 在地理位置分散的站点之间使用纠删编码时,检索和修复的 WAN 网络流量使用率较高,尤其是频繁检索的对象或通过 WAN 网络连接进行对象修复。
- 当您在站点间使用纠删编码时,最大对象吞吐量会随着站点间网络延迟的增加而急剧下降。这一减少是由于 TCP 网络吞吐量相应减少 StorageGRID ,从而影响 StorageGRID 系统存储和检索对象片段的速度。
- 提高计算资源的利用率。