Hive初探
概念
数据仓库:数据仓库(DW)是一个用于存储分析报告的数据系统
数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持
数据仓库本身并不生产任何数据其数据来源于不同的系统
同时数据仓自身也不需要消费任何的数据,其结果开放给外部应用使用
这也是问什么叫仓库,而不是工厂的原因
OLTP
OLTP系统的核心是是面向业务,支持业务,支持事务.所有的业务操作可以分为读写俩种操作,一般来说读压力明显大于写压力.如果在OLTP进行分析,有以下问题需要考虑
- 数据分析也是对数据库进行读取操作,会让读压力倍增
- OLTP进存储周或数月的数据
- 数据分散在不同系统不同表中,字段类型不统一
特征
- 主体是一个抽象的概念,是较高层次上数据综合,归类并进行分析利用抽象
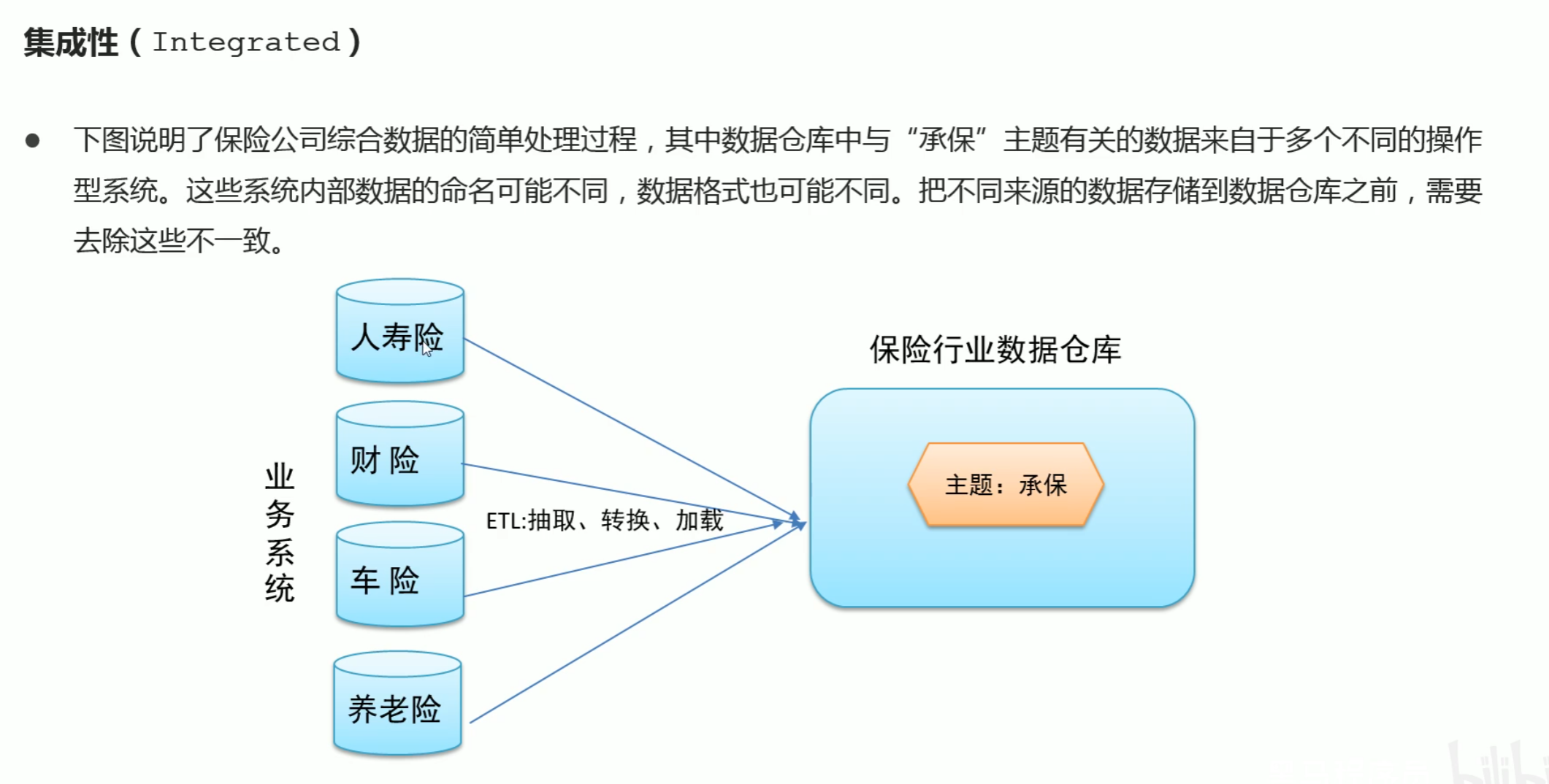
- 主题相关的数据通常会分布在多个操作系统中,彼此分散,独立异构.需要集成到数仓主题下
- 数据仓是数据分析的平台,而不是创造数据的平台
- 数据仓的数据需要随着时间更新,以适应决策需要
OLTP 联机事务处理
OLAP 联机分析处理
数据仓库不是大型数据库,虽然数据仓库存储规模很大,数据仓库也不是要取代传统数据库,数据库存储业务数据,数据仓库一般存储历史数据
数据集市
数据仓库是面向整个集团组织的数据,数据集市(data mart)是面向单个部门使用的
可以认为数据集市是数据仓库的子集,也有人把数据集市叫做小型数据仓库.数据集市通常只涉及一个主题领域,例如市场销售.因为它们较小且更具体,所以通常更易于管理和维护
分层架构
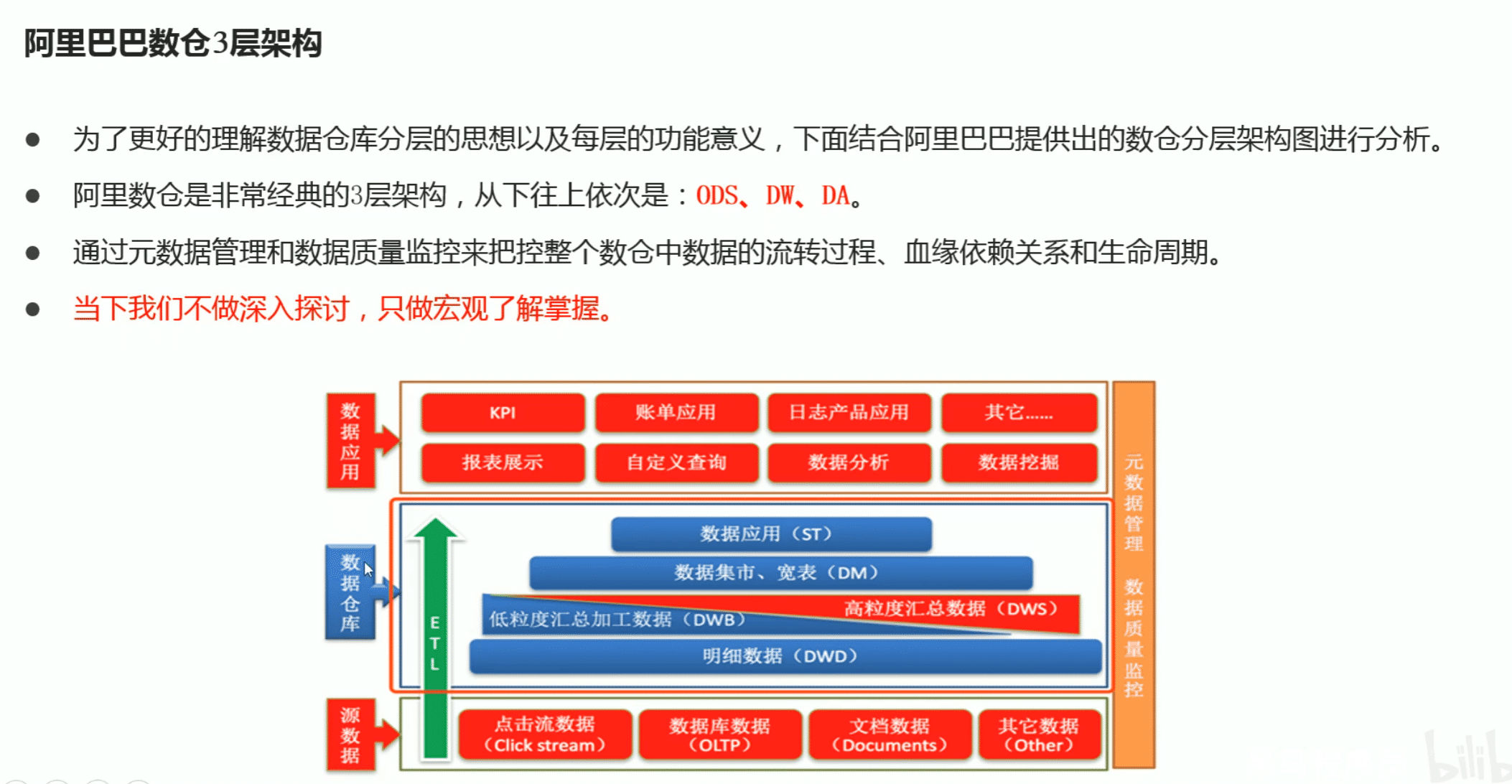
最基础的分层思想,理论上分为三个层:操作型数据层ODS,数据仓库层DW,数据应用层DA
实际上可以给予这个基础分层之上添加新的层次,来满足不同的需求
ETL和ELT
数据仓库从各数据源获取数据及在数据仓库内的数据转换和流动都可以认为是ETL
- 抽取 Extra
- 转换 Transfer
- 装载 Load
ETL
抽取转换装载(传统)
ELT
使用ELT数据在源数据池中提取后立即加载.没有专门的临时数据库ODS

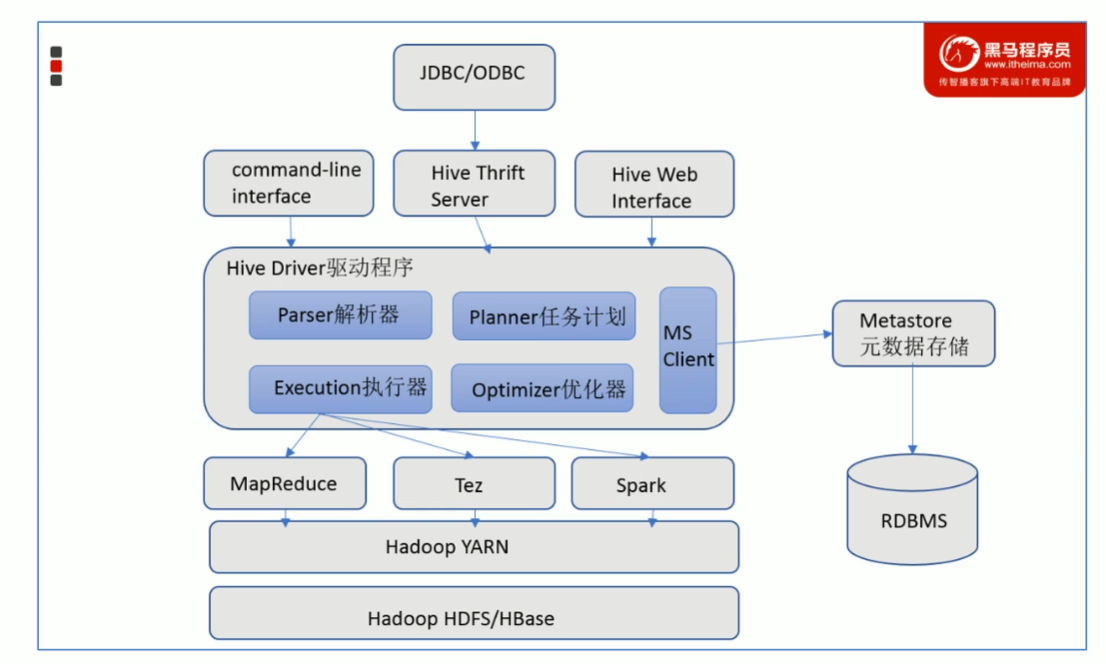
Hive
Apache hive是一款建立在hadoop之上的开元数据系统,可以将存储在hadoop结构化,半结构化的数据文件映射为一张数据表,提供了类似SQL查询模型,称为Hive查询语言(HQL)用于访问和分析存储在Hadoop文件中的大型数据集
Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop集群执行
have能将数据映成为一张表,这个映射是文件和表之间的对应关系