Kubernetes中的网络
iptables和IPVS
从k8s1.8版本开始,kube-proxy引入了IPVS模式,IPVS模式与iptables同样基于netfilter,但是ipvs采用的hash表,iptables采用一条条的规则表。
iptables又是为了防火墙设计的,集群数量越来越多iptables规则就越来越多,而iptables规则是从上到下匹配,所以效率就越是地低下。因此当service数量达到一定规模时,hash查表的速度优势就会显现出来,从而提高service的服务性能。
每个节点的kube-proxy负责监听API server中service和endpoint的变化情况。将变化信息写入本地userspace、iptables、ipvs来实现service负载均衡,使用NAT将vip流量转至endpoint中。由于userspace模式因为可靠性和性能(频繁切换内核、用户空间)早已经淘汰,所有客户端请求svc,先经过iptables,然后再经过kube-proxy到pod,所以性能差。
ipvs和iptables都是基于netfilter的,差别如下
- ipvs为集群提供了更好的可扩展性和性能
- ipvs支持比iptables更复杂的负载均衡算法(最小负载,最少连接,加权等)
- ipvs支持服务器监控检查和连接重试功能
Kube-proxy
kube-proxy是Kubernetes工作节点上的一个网络代理组件,运行在每个node上
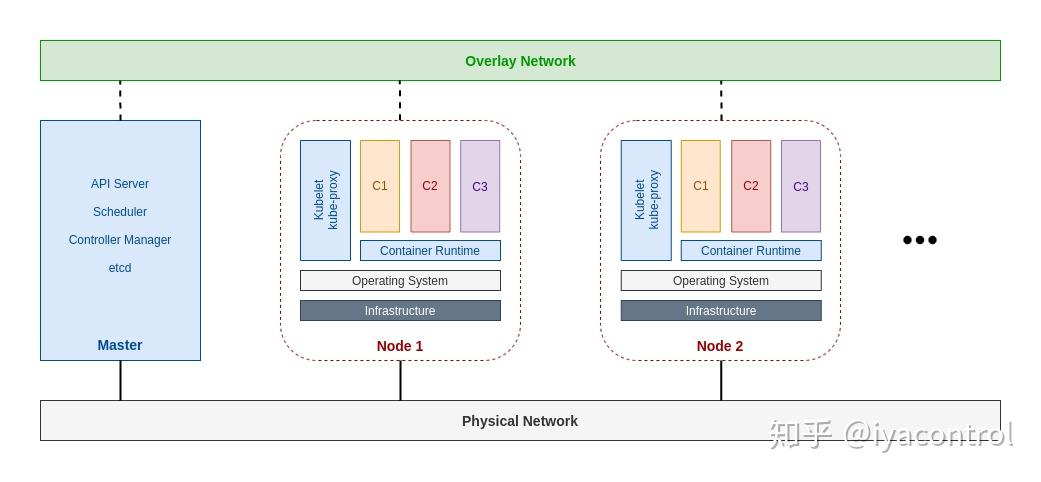
kube-proxy维护节点上的网络规则,实现了Kubernetes Service概念的一部分。它的作用是使发往Service的流量(通过ClusterIP和端口)负载均衡到正确的后端Pod。
工作原理
kube-proxy监听API server中资源对象的变化情况,包括以下三种
- service
- endpoint、endpointslices
- node
然后根据监听资源变化操作代理后端来为服务配置负载均衡。
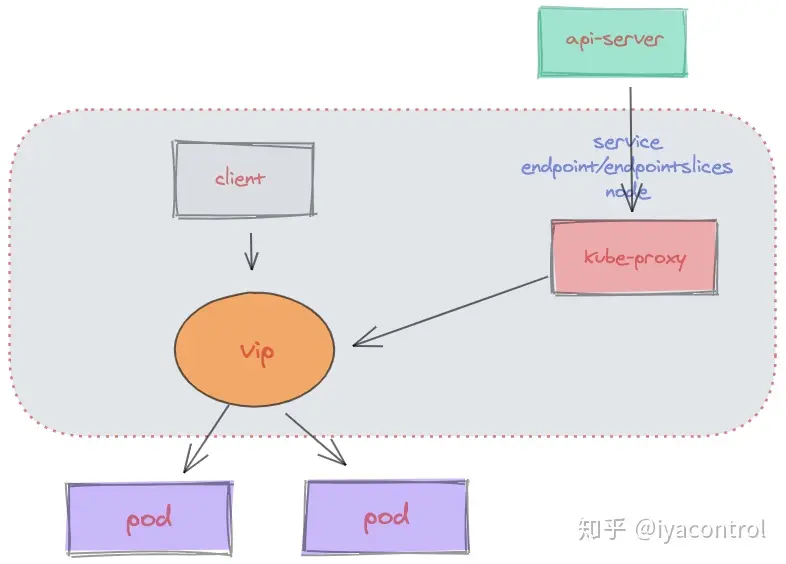
如果你的Kubernetes使用EndpointSlice,那么kube-proxy会监听EndpointSlice,否则会监听Endpoint。
如果你启用了服务拓扑,那么kube-proxy也会监听node信息。服务拓扑(service topology)可以让一个服务基于集群的Node拓扑进行流量路由。例如,一个服务可以指定流量是被优先路由到一个和客户端在同一个Node或者在同一可用区域的端点。
EndpointSlice是实现某service的端点的子集。一个service可以有多个EndpointSlice对象与之对应,必须将所有的EndpointSlice拼接起来才能形成一套完整的端点集合。Service通过标签来选择EndpointSlice。
代理模式
目前kuybe-proxy支持4种代理模式
- userspace
- iptables
- ipvs
- Kernelspace
其中kernelspace专用于windows,userspace是早期版本实现
iptables
iptables是一种linux内核功能,旨在称为一种高效的防火墙,具有足够的灵活性来处理各种常见的数据包操作和过滤需求。它允许将灵活规则序列附加到内核的数据包处理管道中的各种钩子上。
在iptables模式下,kube-proxy将规则附加到NAT预路由钩子上,以实现其NAT和负载均衡功能。这种方法很简单,使用成熟的内核功能,并且可以通过iptables实现网络策略组件完美配合。
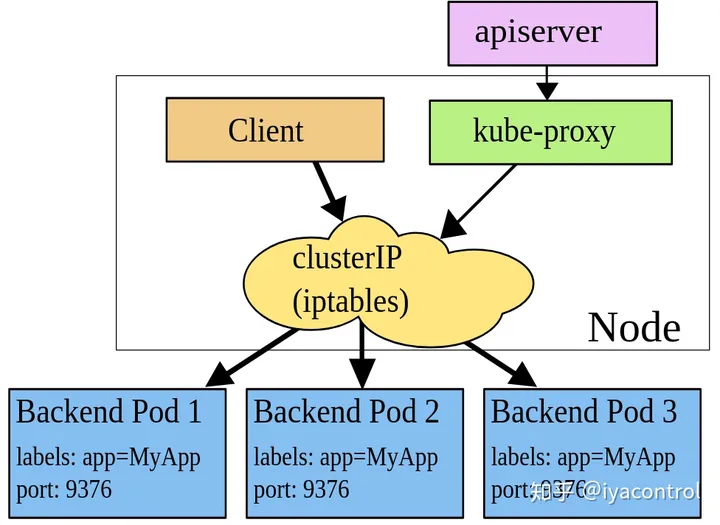
默认的策略是,kube-proxy在iptables模式下随机选择一个后端。
如果kube-proxy在iptables模式下运行,并且所选的第一个pod没有响应,则连接失败。这与用户空间模式不同:在这种情况下,kube-proxy将检测到与第一个pod的连接以失败,并会自动使用其他后端Pod重试。
但是,kbe-proxy对iptables规则进行编程的方式是一种O(n)复杂度的算法,其中n与集群大小(或更确切地说,服务的数量和每个服务背后的后端Pod的数量)成比例地增长)。
ipvs
IPVS是专门用于负载均衡的Linux内核功能。在IPVS模式下,kube-proxy可以对IPVS负载均衡器进行编程,而不是使用iptables。这非常有效,它还使用了成熟的内核功能,并且IPVS旨在均衡许多服务的负载。它具有优化的API和优化的查找例程,而不是一系列顺序规则。 结果是IPVS模式下kube-proxy的连接处理的计算复杂度为O(1)。换句话说,在大多数情况下,其连接处理性能将保持恒定,而与集群大小无关。
与iptables模式下的kube-proxy相比,IPVS模式下的kube-proxy重定向通信的延迟要短,并且在同步代理规则时具有更好的性能。与其他代理模式相比,IPVS模式还支持更高的网络流量吞吐量。
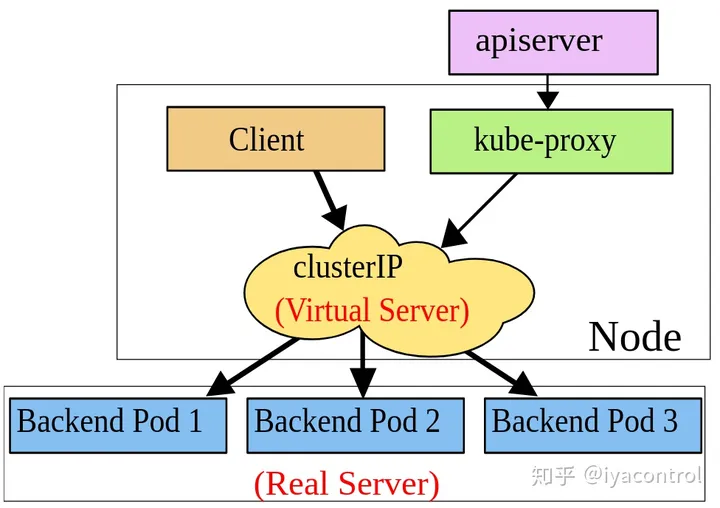
IPVS提供了更多选项来平衡后端Pod的流量。 这些是:
rr: round-robinlc: least connection (smallest number of open connections)dh: destination hashingsh: source hashingsed: shortest expected delaynq: never queue
IPVS的一个潜在缺点是,与正常情况下的数据包相比,由IPVS处理的数据包通过iptables筛选器钩子的路径不同。如果打算将IPVS与其他使用iptables的程序一起使用,则需要研究它们是否可以一起正常工作。 不过Ipvs代理模式已经推出很久了,很多组件已经适配的很好了,比如Calico。
总的来说IPVS更侧重于用于实现高性能的负载均衡和流量转发。
性能对比
TIGERA 公司 从响应时间和CPU使用率两个角度对两种代理模式进行了对比。在专用节点上运行了一个“客户端”微服务Pod,它每秒向Kubernetes服务生成1000个请求,该请求由集群中其他节点上运行的10个“服务器”微服务Pod承载。然后,在iptables和IPVS模式下,使用各种数量的Kubernetes服务(每个服务有10个Pod支持),最多10,000个服务(带有100,000个服务后端)来测量客户端节点上的性能。
- 在超过1,000个服务(10,000个后端Pod)之前,iptables和IPVS之间的平均往返响应时间之间的差异微不足道。
- 仅当不使用keepalive连接时,平均往返响应时间才有差异。
- iptables和IPVS之间的CPU使用率差异不明显,直到超过1,000个服务(带有10,000个后端Pod)为止。
- 在10,000个服务(具有100,000个后端pod)的情况下,使用iptables的CPU的增加量约为内核的35%,而使用IPVS的CPU的增加量约为内核的8%。
总结
对于iptables和IPVS模式,kube-proxy的响应时间开销与建立连接相关,而不是与在这些连接上发送的数据包或请求的数量有关。这是因为Linux使用的连接跟踪(conntrack)能够非常有效地将数据包与现有连接进行匹配。如果数据包在conntrack中匹配,则无需检查kube-proxy的iptables或IPVS规则即可确定该如何处理。
在集群中不超过1000个服务的时候,iptables 和 ipvs 并无太大的差异。而且由于iptables 与网络策略实现的良好兼容性,iptables 是个非常好的选择。
当你的集群服务超过1000个时,而且服务之间链接大多没有开启keepalive,IPVS模式可能是一个不错的选择。
发展趋势
接口化,类似于CNI。kube-proxy只实现主体框架和接口规范,社区可以有iptables,ipvs,ebpf,nftables等具体实现。
Kubernetes以具备可扩展性而著名。截止到目前,Kube-proxy 几乎是所有k8s组件里边最没有接口化的一个组件。如果想给 kube-proxy 增加一种代理模式,必须代码侵入。所以社区有人想将 nftables 做为 kube-proxy 的一种后端,该 pr 至今没有被merge。
nftables是一个新式的数据包过滤框架,旨在替代现用的iptables、ip6tables、arptables和ebtables的新的包过滤框架。
nftables旨在解决现有{ip/ip6}tables工具存在的诸多限制。相对于旧的iptables,nftables最引人注目的功能包括:改进性能、支持查询表、事务型规则更新、所有规则自动应用等等。
- 无 kube-proxy。交给容器网络框架实现。
践行该观点的容器网络框架非cilium莫属。
Cilium 正在通过 ebpf 实现 kube-proxy 提供的功能。不过由于 ebpf 对 os 内核版本要求比较高,所以一些低版本内核是无法支持的。
CNI chaining 允许cilium 和其他cni容器网络组建结合使用。通过Cilium CNI chaining ,基本网络连接和IP地址管理由非Cilium CNI插件管理,但是Cilium将eBPF程序附加到由非Cilium插件创建的网络设备上,以提供L3 / L4 / L7网络可见性和策略强制执行和其他高级功能,例如透明加密。
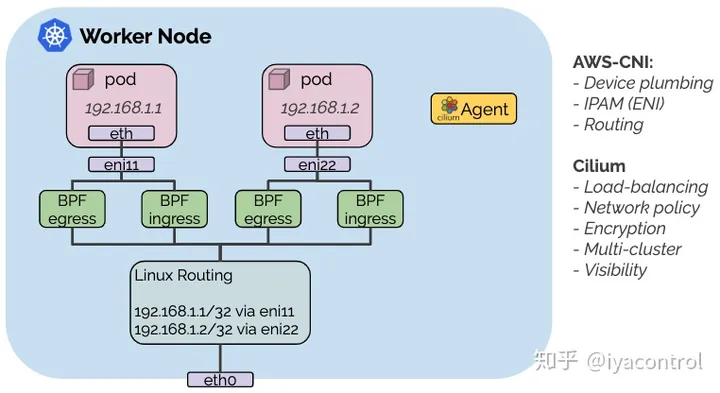
而且该趋势已经被多家公有云厂商认可和支持。比如阿里云结合 terway CNI 和 Cilium,使用cilium提供Kubernetes的Service和NetworkPolicy实现。
CNI机制与Flannel工作原理
循序渐进理解CNI机制与Flannel工作原理 :: Yingchi Blog
CNI,它的全称时ContainerNetworkInterface,即容器网络的API接口。Kubernetes网络的发展方向是通过插件的方式来集成不同的网络方案,CNI就是这一努力的结果。CNI只专注解决容器网络连接和容器销毁时的资源释放,提供一套框架,所以CNI可以支持大量不同的网络模式,并且容易实现。
网络模型到CNI
在理解CNI机制以及Flannel等具体实现方案之前,首先要理解问题的背景,这里从Kubernetes网络模型开始回顾。
从底层网络来看,Kubernetes的网络通信可以分为三层去看待:
- pod内部容器通信
- 同主机Pod间容器通信
- 跨主机Pod间容器通信
对于前俩点其实不难理解
- 对于Pod内部容器通信,由于Pod内部的容器处于同一个Network Namepsace下(通过Pause容器实现)即共享同一个网卡,因此可以直接通信。
- 对于同主机Pod间容器通信,Docker会在每个主机上创建一个Docker0网桥,主机上面所有的Pod内的容器全部接到网桥上,因此可以互通。
而对于第三点,跨主机Pod间容器通信,Docker并没有给出很好的解决方案,对于Kubernetes而言,跨主机Pod容器通信是非常重要的一项工作,但有意思的是,Kubernetes并没有自己去解决这个问题,而是专注于容器编排问题,对于跨主机的容器通信规则则是交给了第三方实现,这就是CNI机制。
CNI,它的全称是 Container Network Interface,即容器网络的 API 接口。kubernetes 网络的发展方向是希望通过插件的方式来集成不同的网络方案, CNI 就是这一努力的结果。CNI 只专注解决容器网络连接和容器销毁时的资源释放,提供一套框架,所以 CNI 可以支持大量不同的网络模式,并且容易实现。平时比较常用的 CNI 实现有 Flannel、Calico、Weave 等。
CNI插件通常由三种实现方式:
- Overlay:靠隧道打通,不依赖底层网络
- 路由:靠路由打通,不分依赖底层网络;
- Underlay:靠底层网络打通,强依赖底层网络
在选择CNI插件时要根据自己实际需求进行考量,比如考虑NetworkPolicy是否要支持Pod网络间的访问策略,可以考虑Calico、Weave;Pod的创建速度,Overlay或路由模式的CNI插件在创建Pod时比较快,Underlay较慢;网络性能,Overlay性能相对较差,Underlay即路由模式相对较快。
我Flannel工作原理
CNI中经常见到的解决方案是Flannel,由CoreOS退出,Flannel采用的便是上面降到的Overlay模式。
Overlay网络简介
Overlay网络(Overlay Network)属于应用层网络,它是面向应用层的,不考虑网络层,物理层的问题。
具体而言Overlay网络是指建立在另一个网络上的网络。该网络中的节点可以看做通过虚拟或逻辑链路连接起来的。虽然在底层由很多条物理链路,但是这些虚拟或逻辑链路都与路径一一对应。列如:许多p2p网络就是Overlay网络,因为它运行在物联网的上层。Overlay网络允许对没有IP地址表示的目的主机路由信息,例如:Freenet和DHT(分布式哈希表)可以路由信息到一个存储特定文件的节点,而这个节点的IP地址实现并不知道。
Overlay网络被认为是一条用来改善互联网路由的途径,让二层网络在三层网络中传递,即解决了二层的缺点,又解决了三层的不灵活
Flannel的工作原理
Flannel实质上就是一种Overlay网络,也就是将TCP数据包装在另一种网络包里面进行路由转发和通信,目前已经支持 UDP、VxLAN、AWS VPC 和 GCE 路由等数据转发方式。
Flannel会在每一个宿主机上云霄名为flanneld代理,其负责为宿主机预先分配一个子网,并未Pod分配IP地址。Flannel使用Kubernetes或etcd来存储网络配置、分配的子网和主机公共IP等信息。数据包通过VXLAN、UDP或host-gw这些类型的后端机制进行转发。
Flannel规定宿主机下各个Pod属于同一个子网,不同宿主机下的Pod属于不同子网。
工作模式
支持3种实现:UDP、VxLAN、host-gw,
- UDP 模式:使用设备 flannel.0 进行封包解包,不是内核原生支持,频繁地内核态用户态切换,性能非常差;
- VxLAN 模式:使用 flannel.1 进行封包解包,内核原生支持,性能较强;
- host-gw 模式:无需 flannel.1 这样的中间设备,直接宿主机当作子网的下一跳地址,性能最强;
host-gw的性能损失大约在10%左右,而其他所有基于VxLAN“隧道”机制的网络方案,性能损失在20%~30%左右。
UDP模式
在计算机网络中,TUN 与 TAP 是操作系统内核中的虚拟网络设备。不同于普通靠硬件网路板卡实现的设备,这些虚拟的网络设备全部由软件实现,并向运行于操作系统上的软件提供与硬件的网络设备完全相同的功能。 TAP 等同于一个以太网设备,它操作第二层数据包如以太网数据帧。TUN 模拟了网络层设备,操作第三层数据包比如 IP 数据封包。
操作系统通过 TUN/TAP 设备向绑定该设备的用户空间的程序发送数据,反之,用户空间的程序也可以像操作硬件网络设备那样,通过 TUN/TAP 设备发送数据。在后种情况下,TUN/TAP 设备向操作系统的网络栈投递(或“注入”)数据包,从而模拟从外部接受数据的过程。
UDP 模式的核心就是通过 TUN 设备 flannel0 实现。TUN设备是工作在三层的虚拟网络设备,功能是:在操作系统内核和用户应用程序之间传递IP包。 相比两台宿主机直接通信,多出了 flanneld 的处理过程,这个过程,使用了 flannel0 这个TUN设备,仅在发出 IP包的过程中经过多次用户态到内核态的数据拷贝(linux的上下文切换代价比较大),所以性能非常差 原理如下:
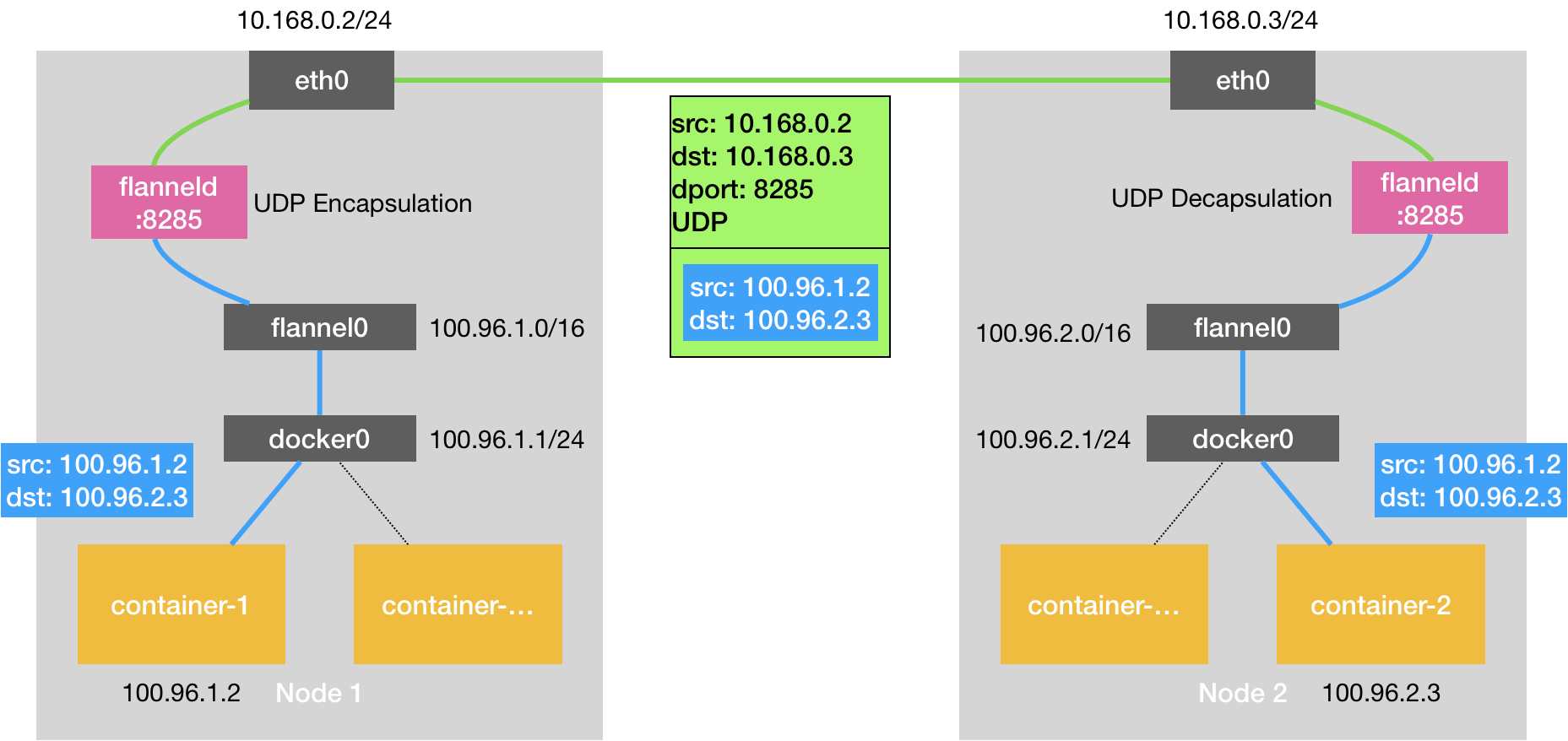
以flannel0为例,操作系统将一个IP包发给flannel0,flannel0把IP包发给创建这个设备的应用程序:flannel进程(内核态->用户态) 相反,flannel进程向flannel0发送一个IP包,IP包会出现在宿主机的网络栈中,然后根据宿主机的路由表进行下一步处理(用户态->内核态) 当IP包从容器经过docker0出现在宿主机,又根据路由表进入flannel0设备后,宿主机上的flanneld进程就会收到这个IP包
flannel管理的容器网络里,一台宿主机上的所有容器,都属于该宿主机被分配的“子网”,子网与宿主机的对应关系,存在Etcd中(例如Node1的子网是100.96.1.0/24,container-1的IP地址是100.96.1.2)
当flanneld进程处理flannel0传入的IP包时,就可以根据目的IP地址(如100.96.2.3),匹配到对应的子网(比如100.96.2.0/24),从Etcd中找到这个子网对应的宿主机的IP地址(10.168.0.3)
然后 flanneld 在收到container-1给container-2的包后,把这个包直接封装在UDP包里,发送给Node2(UDP包的源地址,就是Node1,目的地址是Node2)
每台宿主机的flanneld都监听着8285端口,所以flanneld只要把UDP发给Node2的8285端口就行了。然后Node2的flanneld再把IP包发送给它所管理的TUN设备flannel0,flannel0设备再发给docker0
VXLAN模式
VxLAN,即Virtual Extensible LAN(虚拟可扩展局域网),是Linux本身支持的一网种网络虚拟化技术。VxLAN可以完全在内核态实现封装和解封装工作,从而通过“隧道”机制,构建出 Overlay 网络(Overlay Network)
VxLAN的设计思想是: 在现有的三层网络之上,“覆盖”一层虚拟的、由内核VxLAN模块负责维护的二层网络,使得连接在这个VxLAN二层网络上的“主机”(虚拟机或容器都可以),可以像在同一个局域网(LAN)里那样自由通信。 为了能够在二层网络上打通“隧道”,VxLAN会在宿主机上设置一个特殊的网络设备作为“隧道”的两端,叫VTEP:VxLAN Tunnel End Point(虚拟隧道端点) 原理如下:
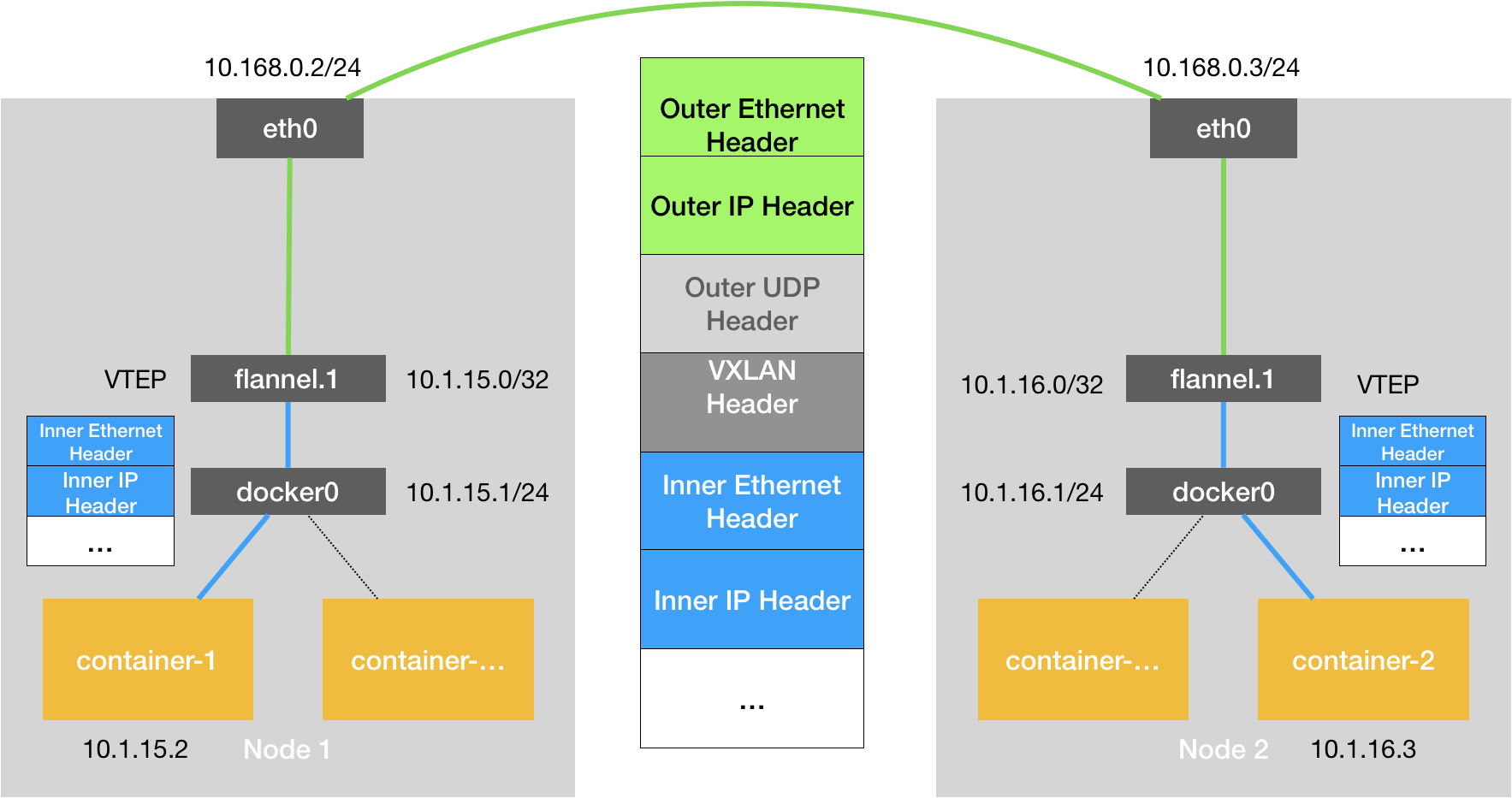
flannel.1设备,就是VxLAN的VTEP,即有IP地址,也有MAC地址 与UDP模式类似,当container-发出请求后,上的地址10.1.16.3的IP包,会先出现在docker网桥,再路由到本机的flannel.1设备进行处理(进站),为了能够将“原始IP包”封装并发送到正常的主机,VxLAN需要找到隧道的出口:宿主机的VTEP设备,这个设备信息,由宿主机的flanneld进程维护
VTEP设备之间通过二层数据桢进行通信 源VTEP设备收到原始IP包后,在上面加上一个目的MAC地址,封装成一个导去数据桢,发送给目的VTEP设备(获取 MAC地址需要通过三层IP地址查询,这是ARP表的功能)

封装过程只是加了一个二层头,不会改变“原始IP包”的内容 这些VTEP设备的MAC地址,对宿主机网络来说没什么实际意义,称为内部数据桢,并不能在宿主机的二层网络传输,Linux内核还需要把它进一步封装成为宿主机的一个普通的数据桢,好让它带着“内部数据桢”通过宿主机的eth0进行传输,Linux会在内部数据桢前面,加上一个我死的VxLAN头,VxLAN头里有一个重要的标志叫VNI,它是VTEP识别某个数据桢是不是应该归自己处理的重要标识。 在Flannel中,VNI的默认值是1,这也是为什么宿主机的VTEP设备都叫flannel.1的原因
一个flannel.1设备只知道另一端flannel.1设备的MAC地址,却不知道对应的宿主机地址是什么。 在linux内核里面,网络设备进行转发的依据,来自FDB的转发数据库,这个flannel.1网桥对应的FDB信息,是由flanneld进程维护的 linux内核再在IP包前面加上二层数据桢头,把Node2的MAC地址填进去。这个MAC地址本身,是Node1的ARP表要学习的,需 Flannel维护,这时候Linux封装的“外部数据桢”的格式如下

然后Node1的flannel.1设备就可以把这个数据桢从eth0发出去,再经过宿主机网络来到Node2的eth0 Node2的内核网络栈会发现这个数据桢有VxLAN Header,并且VNI为1,Linux内核会对它进行拆包,拿到内部数据桢,根据VNI的值,所它交给Node2的flannel.1设备
host-gw模式
Flannel 第三种协议叫 host-gw (host gateway),这是一种纯三层网络的方案,性能最高,即 Node 节点把自己的网络接口当做 pod 的网关使用,从而使不同节点上的 node 进行通信,这个性能比 VxLAN 高,因为它没有额外开销。不过他有个缺点, 就是各 node 节点必须在同一个网段中 。

howt-gw 模式的工作原理,就是将每个Flannel子网的下一跳,设置成了该子网对应的宿主机的 IP 地址,也就是说,宿主机(host)充当了这条容器通信路径的“网关”(Gateway),这正是 host-gw 的含义 所有的子网和主机的信息,都保存在 Etcd 中,flanneld 只需要 watch 这些数据的变化 ,实时更新路由表就行了。 核心是IP包在封装成桢的时候,使用路由表的“下一跳”设置上的MAC地址,这样可以经过二层网络到达目的宿主机。
另外,如果两个 pod 所在节点在同一个网段中 ,可以让 VxLAN 也支持 host-gw 的功能, 即直接通过物理网卡的网关路由转发,而不用隧道 flannel 叠加,从而提高了 VxLAN 的性能,这种 flannel 的功能叫 directrouting。
通信过程描述
以 UDP 模式为例,跨主机容器间通信过程如下图所示:
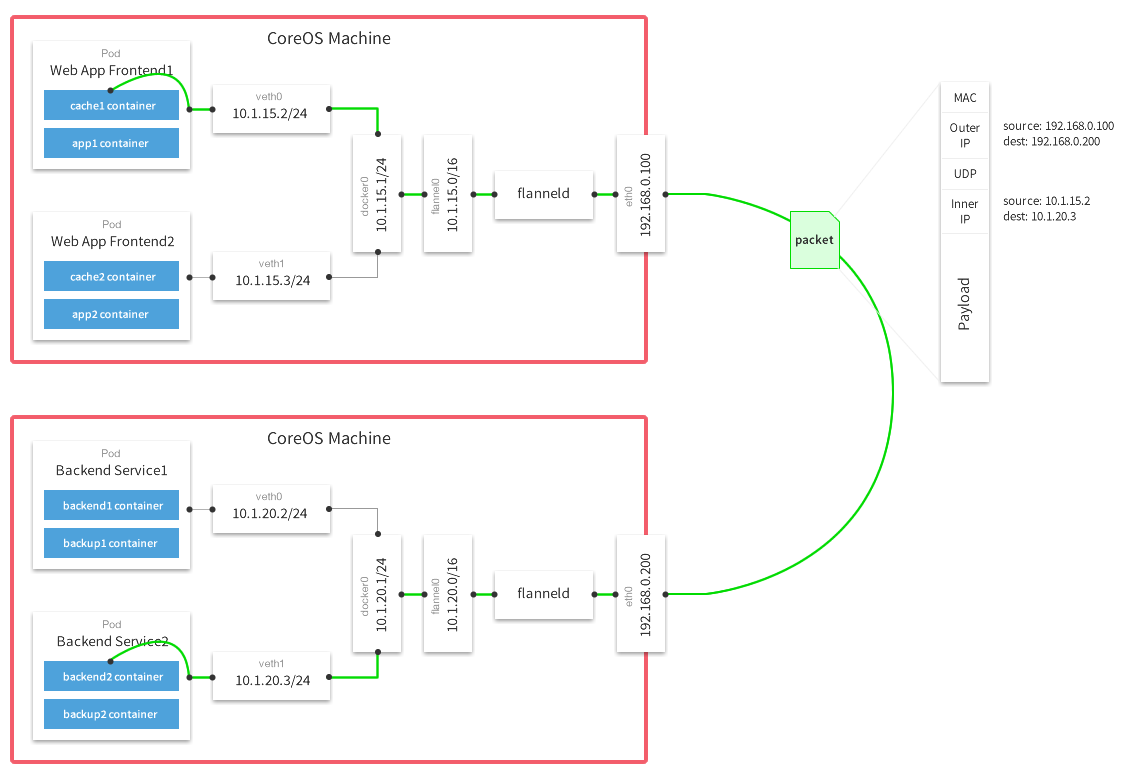
上图是 Flannel 官网提供的在 UDP 模式下一个数据包经过封包、传输以及拆包的示意图,从这个图片中可以看出两台机器的 docker0 分别处于不同的段:10.1.20.1/24 和 10.1.15.1/24 ,如果从 Web App Frontend1 pod(10.1.15.2)去连接另一台主机上的 Backend Service2 pod(10.1.20.3),网络包从宿主机 192.168.0.100 发往 192.168.0.200,内层容器的数据包被封装到宿主机的 UDP 里面,并且在外层包装了宿主机的 IP 和 mac 地址。这就是一个经典的 overlay 网络,因为容器的 IP 是一个内部 IP,无法从跨宿主机通信,所以容器的网络互通,需要承载到宿主机的网络之上。
以 VxLAN 模式为例。
在源容器宿主机中的数据传递过程:
1)源容器向目标容器发送数据,数据首先发送给 docker0 网桥
在源容器内容查看路由信息:
$ kubectl exec -it -p {Podid} -c {ContainerId} -- ip route2)docker0 网桥接受到数据后,将其转交给flannel.1虚拟网卡处理
docker0 收到数据包后,docker0 的内核栈处理程序会读取这个数据包的目标地址,根据目标地址将数据包发送给下一个路由节点: 查看源容器所在Node的路由信息:
$ ip route3)flannel.1 接受到数据后,对数据进行封装,并发给宿主机的eth0
flannel.1收到数据后,flannelid会将数据包封装成二层以太包。 Ethernet Header的信息:
- From:{源容器flannel.1虚拟网卡的MAC地址}
- To:{目录容器flannel.1虚拟网卡的MAC地址}
4)对在flannel路由节点封装后的数据,进行再封装后,转发给目标容器Node的eth0;
由于目前的数据包只是vxlan tunnel上的数据包,因此还不能在物理网络上进行传输。因此,需要将上述数据包再次进行封装,才能源容器节点传输到目标容器节点,这项工作在由linux内核来完成。 Ethernet Header的信息:
- From:{源容器Node节点网卡的MAC地址}
- To:{目录容器Node节点网卡的MAC地址}
IP Header的信息:
- From:{源容器Node节点网卡的IP地址}
- To:{目录容器Node节点网卡的IP地址}
通过此次封装,就可以通过物理网络发送数据包。
在目标容器宿主机中的数据传递过程:
5)目标容器宿主机的eth0接收到数据后,对数据包进行拆封,并转发给flannel.1虚拟网卡;
6)flannel.1 虚拟网卡接受到数据,将数据发送给docker0网桥;
7)最后,数据到达目标容器,完成容器之间的数据通信。