pytorch入门手写数字
tensor
scalar(标量)一个数值
vector(向量):一维数组
matrix(矩阵):二维数组
tensor(张量):大于二维的数组,即多维数组
手写字体识别流程
- 定义超参数
- 构建transforms,主要是对图像做变化
- 下载加载数据集mnist
- 构建网络模型
- 定义训练方法
- 定义测试方法
- 开始训练模型,输出预测结果
名词
专业超参数
参数:模型f(x,0)0称为模型的参数,可以通过优化算法进行学习。
超参数:用来定义模型结构或者优化策略
batch_size批处理:每一个数据集循环运行几轮
transforms变化,旋转图片,以及正则化
nomalize正则化,模型出现过拟合现象时,降低模型复杂度
卷积层
有卷积核构建,卷积核称为卷积,也称为滤波器。卷积的大小可以在实际需要时自定义长和宽(1*1,3*3,5*5)
池化层
对图片进行压缩(降采样)的一种方法,如max pooling,average pooling
激活层
激活函数的作用就是,在所有隐藏层之间添加一个激活函数这样输出就是一个非线性函数了,因而神经网络的表达能力更强了
损失函数
在深度学习中,损失反应模型最后预测结果与实际真值之间的差距,可以通过训练分析训练结果是否好坏,例如均方损失,交叉熵
卷积核
又称为滤波器,可认为是某种特征
卷积维度
一般情况下,卷积核在几个维度上滑动就是在几维卷积核中
卷积过程类似于用一个模板去图像上寻找它上次的区域,与卷积核模式越相似,激活值越高,从而实现特征提取
通道(Channel):卷积层的通道数(层数)。如下图是一个卷积核(kernel)为3×3、步长(stride)为1、填充(padding)为1的二维卷积:
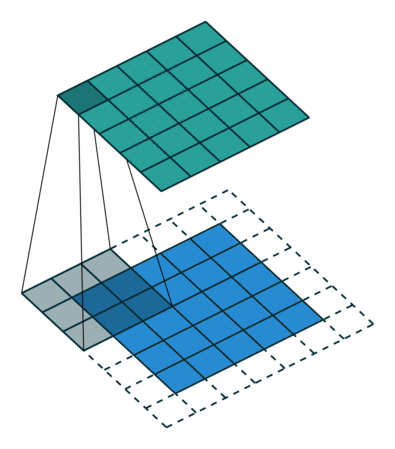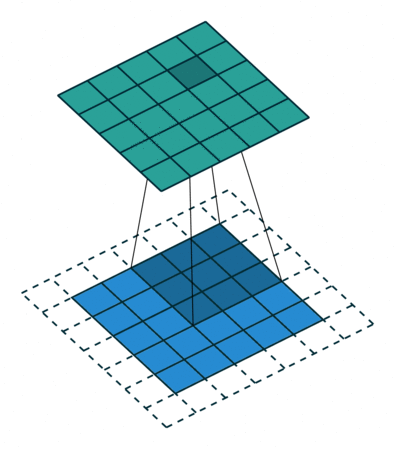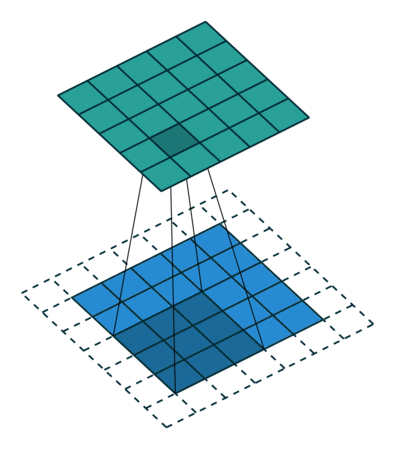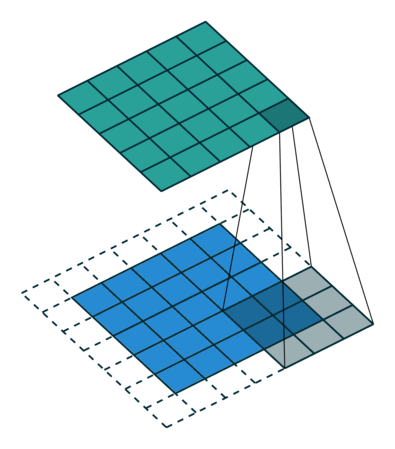
卷积运算
卷积核在输入信号图像上滑动,相应位置上进行乘加
卷积的计算过程非常简单,当卷积核在输入图像上扫描时,将卷积核与输入图像中对应位置的数值逐个相乘,最后汇总求和,就得到该位置的卷积结果。不断移动卷积核,就可算出各个位置的卷积结果。如下图:
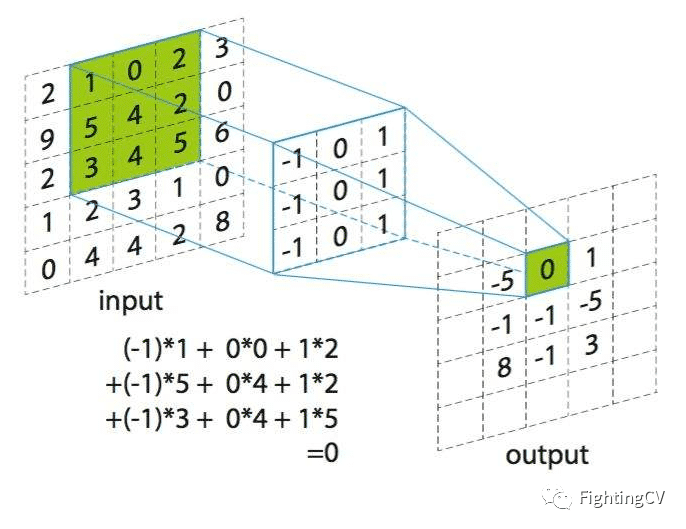
卷积的定义是从纯数学语境下继承下来的
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import cv2
import numpy as np
BATCH_SIZE = 16 # 每批处理的数据
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
EPOCHS = 10 # 训练数据的轮次
# 构建pipline=transforms.Compose
pipeline = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) # 标准化
])
# 下载数据集
train_set = datasets.MNIST("data", train=True, download=True, transform=pipeline) # 放在data目录,训练集,确定要下载
test_set = datasets.MNIST("data", train=False, download=True, transform=pipeline)
# 加载数据
train_loader = DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True) # 加载数据,设置batch_size,并打乱
test_loader = DataLoader(test_set, batch_size=BATCH_SIZE, shuffle=True)
with open("./data/MNIST/raw/train-images-idx3-ubyte", "rb")as f:
file = f.read()
image1 = [int(str(item).encode('ascii'), 16) for item in file[16:16 + 784]]
print(image1)
image1_np = np.array(image1, dtype=np.uint8).reshape(28, 28, 1)
print(image1_np.shape)
cv2.imwrite("./img/digit.jpg", image1_np)
class Digit(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 10, 5) # 灰度图片的通道为1,输出通道为10,5是卷积核(kernel)
self.conv2 = nn.Conv2d(10, 20, 3) # 10输入通道 20是输出通道 ,3是kernel
self.fc1 = nn.Linear(20 * 10 * 10, 500) # 20*10*10输入通道,500是输出通道
self.fc2 = nn.Linear(500, 10) # 500: 输入通道,输出通道
def forward(self, x):
input_size = x.size(0) #
x = self.conv1(x) # 卷积操作 x是输入运算的张量 输入 batch_size*1*28*28 输出 batch*10*24*24 (24=28-5+1)
x = F.relu(x) # 保持shpae(形状)不变 输出 batch*10*24*24 激活层,让输入进来的数据表达能力更强
x = F.max_pool2d(x, 2, 2) # 步长是2,输入:batch*10*24*24 输出 batch*10*12
x = self.conv2(x) # batch*10*24*24输出batch*10*24*24 (12-3+1=10)
x = F.relu(x)
x = x.view(input_size, -1) # 拉平 -1是自动计算维度,20*10*10= 2000 简单理解为把聚成数据编程一行
x = self.fc1(x) # 输入batch*2000 输出:batch*500
x = F.relu(x) # 保持shpae不变
x = self.fc2(x) # 输入bathch*500 输出:batch*10
output = F.log_softmax(x, dim=1) # 调用损失函数,计算分类后每个数字的概率值
return output
model = Digit().to(DEVICE) # 创建模型部署到设备上
optimizer = optim.Adam(model.parameters())
def train_model(model, device, train_loader, optimizer, eporch):
# 模型训练
model.train()
for batch_index, (data, target) in enumerate(train_loader): # data是图片 target是标签
# 部署DEVICE
data, target = data.to(device), target.to(device)
# 梯度初始化为0
optimizer.zero_grad()
# 训练后的结果
output = model(data)
# 计算损失
loss = F.cross_entropy(output, target)
# 找到概率值最大的下标
# pred = output.max(1, keepdim=True) # pred=output=argmax(dim=1)
# 反向传播
loss.backward()
# 参数优化
optimizer.step()
if batch_index % 3000 == 0: # 三千次循环打印一次
print("Tran Epoch:{} \t Loss:{:.6f}".format(eporch, loss.item()))
def test_model(model, device, test_loader):
# 模型验证
model.eval()
# 正确率
correct = 0.0
# 测试损失
test_loss = 0.0
with torch.no_grad(): # 不会计算梯度也不会进行反向传播
for data, target in test_loader:
# 部署到device上
data, target = data.to(device), target.to(device)
# 测试数据
output = model(data)
# 计算测试损失
test_loss += F.cross_entropy(output, target).item()
# 找到概率值最大的索引的下标
pred = output.max(1, keepdim=True)[1] # 0是值,1是索引
# 累计正确的值
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print(
"Test--average loss:{:.4f},accuracy:{:.3f}\n".format(test_loss, 100.0 * correct / len(test_loader.dataset)))
for epoch in range(1, EPOCHS + 1):
train_model(model, DEVICE, train_loader, optimizer, epoch)
test_model(model, DEVICE, train_loader)