Docker网络虚拟化实现原理
Docker网络虚拟化实现原理(Bridge模式) - 知乎 (zhihu.com)
花了三天时间终于搞懂 Docker 网络了-腾讯云开发者社区-腾讯云 (tencent.com)
背景
docker的bridge模式
bridge模式是docker在创建容器时使用的默认模式,也是最常用的模式,在briger模式的默认配置下,容器和主机、其他bridge模式容器可以互相访问,容器也能访问外网,但是外网不能访问容器。通常容器会被分配一个172.17.0.0/16网段的IP,宿主机和其他bridge模式容器也是在同一个网段,可以互相通信。
networkNamespace
namespace是linux提供的一种资源隔离机制,每个进程属于一个namespace,只能访问通namespace内的资源,Linux提供了多种namespace,详细内容可以看相关文章。NetWorkNamespace提供了网络接口、IPv4和IPv6协议栈、路由表、Netfilter规则、/proc/net目录(/proc/PID/net的符号链接), /sys/class/net目录下的各种文件、/proc/sys/net下的各种文件、端口号、本地套接字等网络资源的隔离。
veth
一个物理网卡只能属于一个NetWork Namespace,那么在只有一个物理网卡的情况下,另一个NetWork Namesoace如何访问外网呢?其实这是不同NetworkNamespace如何通信的问题Linux内核也提供了一种特殊的网络接口设备:veth,veth接口是成对创建,在一段发出的报文会在另一端接收到,相当于一根网线的俩端。那么可以把一堆veth分别放在俩个Network Namespace中,通过报文转发来实现不同Network Namespace之间的通信。
+-----------------+ +-----------------+
| | | |
| A +------+ +------+ B |
| Network | veth1+---------+veth2 | Network |
| Namespace+------+ +------+Namespace |
| | | |
+-----------------+ +-----------------+Linux的bridge模块
Linux的bridge模块,bridge顾名思义,起到了桥接的作用。Linux内核的bridge是一类网络接口,可以把其他网络接口假如到bridge中,同属一个bridge的接口相当于接入同一个二层交换机,可以进行二层报文的转发,一个bridge接口有独立的mac地址表(fdb表)。bridge接口同时也是一个网络接口。
假设创建了一个bridge接口br0,把eth0加入了br0,那么eth0收到的报文不会进入协议栈,而是在br0内进行报文转发,因此加入到bridge内的接口所设置的ip是不起作用的,而br0接口收到报文是会进入协议栈的,因此可以设置br0的ip地址。
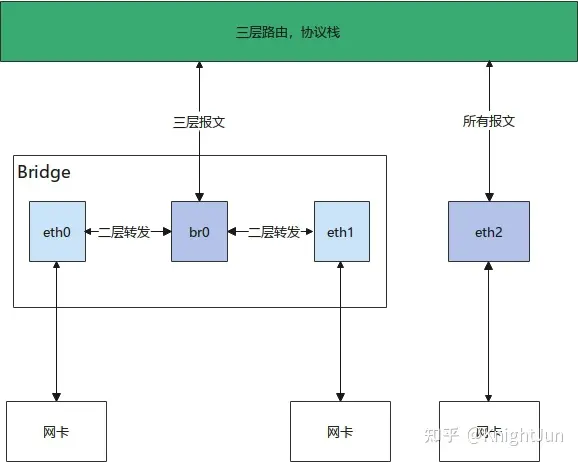
Netfilter
Netfilter是linux内核中的对报文转发进行控制的一套机制,能在报文转发路径上不同的时间点对报文进行不同的控制。时间点包括接收报文进入协议栈进行路由前(NF_IP_PRE_ROUTING)、接收报文路由结果是本地(NF_IP_LOCAL_IN)、接收报文路由结果是转发(NF_IP_FORWARD)、本机发送的报文进行路由之前(NF_IP_LOCAL_OUT)、路由后要离开本机的报文(NF_IP_POST_ROUTING),对报文的控制包括转发,丢弃,nat地址转换,修改报文等行为。Netfilter的功能十分复杂和强大,能对报文转发实现灵活的控制,是Linux下很多防火墙实现的基础。
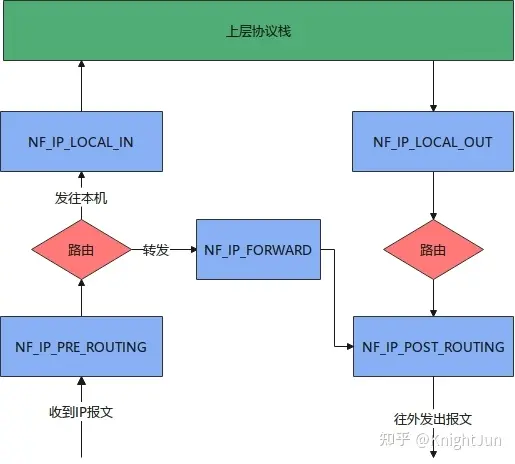
docker网络理论
容器网络实质上是由 Dokcer 为应用程序所创造的虚拟环境的一部分,它能让应用从宿主机操作系统的网络环境中独立出来,形成容器自有的网络设备、IP 协议栈、端口套接字、IP 路由表、防火墙等等与网络相关的模块。
Docker 为实现容器网络,主要采用的架构由三部分组成:CNM、Libnetwork 和驱动。
CNM
Docker网络架构采用的设计规范是CNM(Container Network Model):容器网络模型中规定了Docker网络的基础组成要素Sandbox、Endpoint、Network。
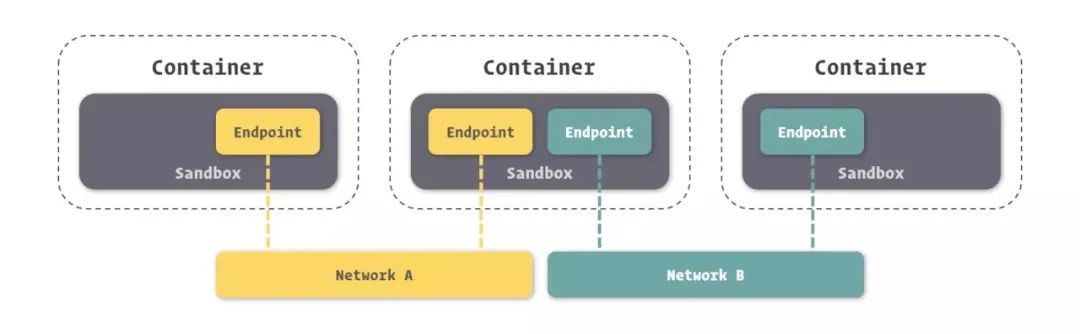
- Sandbox,提供了容器的虚拟网络栈,也即端口套接字、IP路由表、防火墙、DNS配置等内容。主要用于隔离容器网络与宿主机网络,形成了完全独立的容器网络环境。
- Network,Docker内部的虚拟子网,网络内的参与者互相可见并能够进行通讯。Docker虚拟网路和宿主机网络是存在隔离关系的,其目的主要是形成容器间的安全通讯环境。
- Endpoint,就是虚拟网络接口,就像普通网络接口一样,Endpoint主要职责是负责创建连接。在CNM中,终端负责将沙盒连接到网络。
如上图所示(我们将图中的三个容器从左到右依次标记为 1、2、3),那么容器 2 有两个 endpoint 并且分别接入 NetworkdA 和 NetworkB。那么容器 1 和容器 2 是可以实现通信的,因为都接入了 NetworkA。但是容器 3 和容器 1,以及容器 2 的两个 Endpoint 之间是不能通信的,除非有三层路由器的支持。 ”
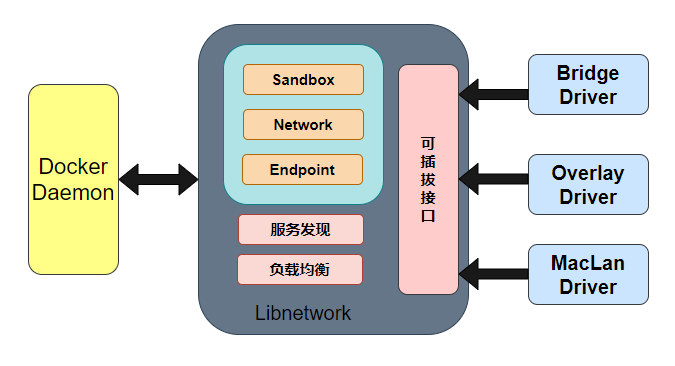
Libnetwork
Libnetwork 是 CNM 的标准实现。Libnetwork 是开源库,采用 Go 语言编写(跨平台的),也是 Docker 所使用的库,Docker 网络架构的核心代码都在这个库中。Libnetwork 实现了 CNM 中定义的全部三个组件,此外它还实现了本地服务发现、基于 Ingress 的容器负载均衡,以及网络控制层和管理层功能。
驱动
如果说 Libnetwork 实现了控制层和管理层功能,那么驱动就负责实现数据层。比如网络的连通性和隔离性是由驱动来处理的。驱动通过实现特定网络类型的方式扩展了 Docker 网络栈,例如桥接网络和覆盖网络。
Docker 内置了若干驱动,通常被称作原生驱动或者本地驱动。比如 Bridge Driver、Host Driver、Overlay Driver、MacLan Driver、None Driver 等等。第三方也可以编写 Docker 网络驱动,这些驱动被叫做远程驱动,例如 Calico、Contiv、Kuryr 以及 Weave 等。每个驱动负责创建其上所有网络资源的创建和管理。
其中 Bridge 和 Overlay 在开发过程中使用频率较高。
- Bridge,Docker 容器的默认网络驱动,通过网桥来实现网络通讯。
- Overlay,借助 Docker 集群模块 Docker Swarm 搭建的跨 Docker Daemon 网络。通过它可以搭建跨物理网络主机的虚拟网络,进而让不同物理机中运行的容器感知不到多个物理机的存在。
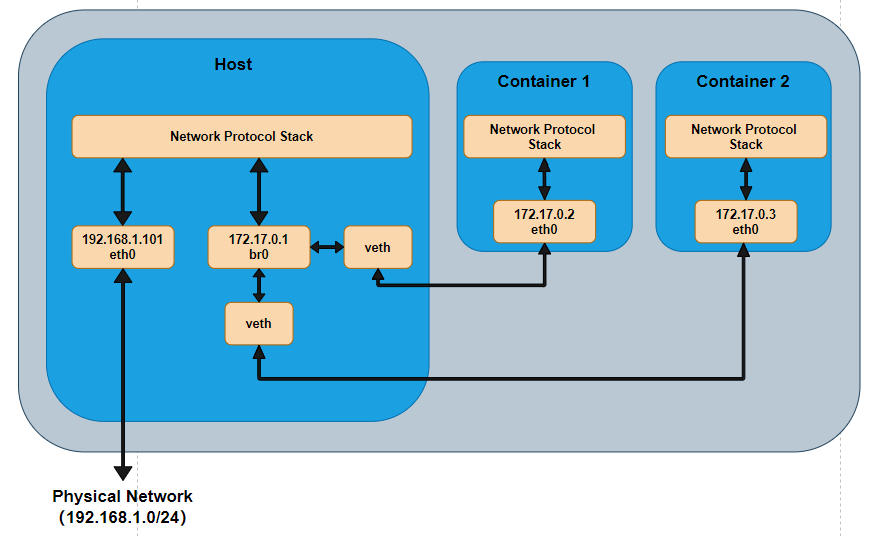
在 Docker 安装时,会自动安装一块 Docker 网卡称为 docker0,用于 Docker 各容器及宿主机的网络通信。
docker0 Link encap:Ethernet HWaddr 02:42:be:6b:61:dc
inet addr:172.17.0.1 Bcast:172.17.255.255 Mask:255.255.0.0
inet6 addr: fe80::42:beff:fe6b:61dc/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:332 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 B) TX bytes:30787 (30.7 KB)★个人理解:CNM 就是一个设计文档,指导你怎么去实现容器网络,而 Libnetwork 和驱动则是其具体实现,从而确保容器网络的通信。 ”
桥接网络
Docker 的 bridge 网络采用内置的 bridge 驱动,而 bridge 的底层采用的是 Linux 内核中 Linux bridge 技术(这意味着 bridge 是高性能并且是非常稳定的)。
那么 Linux 内核中 Linux bridge 应用于容器的话,到底是一个什么样的拓扑图呢?如图所示(这个拓扑关系不清楚接下去的很多东西难以理解,所以先贴出采用 bridge 之后的一个拓扑图),由于容器运行在自己单独的 network namespace 中,所以有单独的协议栈。容器中配置网关为 172.17.0.1,发出去的数据包先到达 br0,然后交给主机的协议栈,由于目的 IP 是外网 IP,且主机会开启 IP forward 功能,于是数据包通过主机的 eth0 发出去。由于 172.17.0.1 是内网 IP ,所以一般发出去之前会做 NAT 转换。由于要进过主机的协议栈并且要做 NAT 转换,所以性能上可能会差点,但是优点就是容器处于内网中,安全性相对要高点。
默认情况下,创建的容器在没有使用 --network 参数指定要加入的 docker 网络时,默认都是加入 Docker 默认的单机桥接网络,也就是下面的 name 为 bridge 的网络。
2.1. 创建新的单机桥接网络
使用 docker network create 命令,我们可创建一个名为 “localnet” 的单机桥接网络,并且在内核中还会多出一个新的 Linux 网桥。
$ docker network ls
NETWORK ID NAME DRIVER SCOPE
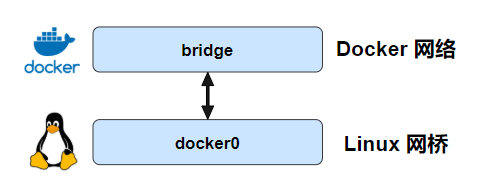
0dda6f303b8b bridge bridge local而默认的 bridge 网络是被映射到内核中为 docker0 的网桥上。
$ ip link show docker0
4: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 02:**:**:**:**:** brd ff:ff:ff:ff:ff:ff
$ docker network inspect bridge | grep bridge.name
"com.docker.network.bridge.name": "docker0",Docker 默认的 bridge 网络和 Linux 内核中的 “docker0” 网桥是一个对应关系,如图所示。bridge 是 Docker 中对网络的命名,而 docker0 是内核中网桥的名字。(个人理解:你就可以把 bridge 和 docker0 当成 Linux 网桥的两个名字,两个都是代表同一个东西。docker 为了管理网络,又给 docker0 这个网桥取名为 bridge)。
那么容器在没有指定要加入的网络情况下,都是加入这个网络的,加入之后的拓补图跟前面的一样。另外,单机桥接网络中的容器想要对外发布的话,需要依赖于端口的映射,这也是为啥我们在启动容器时需要指定端口映射关系的原因。
下面我们通过创建一个新的 Docker 桥接网络来阐述容器内部的通信、端口映射等情况。
使用 docker network create 命令,我们可创建一个名为 “localnet” 的单机桥接网络,并且在内核中还会多出一个新的 Linux 网桥。
$ docker network create -d bridge localnet
$ docker network ls
NETWORK ID NAME DRIVER SCOPE
......
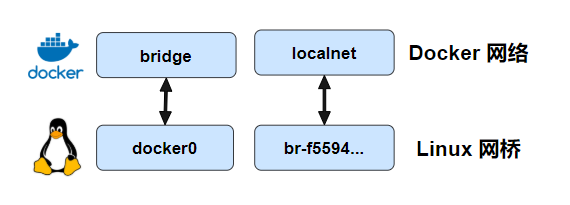
f55943e20201 localnet bridge local在创建完之后,我们可以通过 brctl 工具来查看系统中的 Linux 网桥。可以看到,输出的内容中包含了两个网桥,docker0 是默认的 Docker bridge 网络所使用的网桥,br-f55943e20201 是 Docker localnet 网络所使用的网桥。这两个网桥目前都没有任何设备接入(看 interface 列)。这两个网桥所处的网段是不同的,一个是 172.18.0.1,另一个则是 172.17.0.1。
$ brctl show
bridge name bridge id STP enabled interfaces
br-f55943e20201 8000.02421d9aa3e1 no
docker0 8000.0242be6b61dc no
$ ifconfig
br-f55943e20201 Link encap:Ethernet HWaddr 02:42:1d:9a:a3:e1
inet addr:172.18.0.1 Bcast:172.18.255.255 Mask:255.255.0.0
......
docker0 Link encap:Ethernet HWaddr 02:42:be:6b:61:dc
inet addr:172.17.0.1 Bcast:172.17.255.255 Mask:255.255.0.0
......
2.2. 同个网络中的容器间通信
使用下面这条命令即可运行一个新的容器,并且让这个新容器加入到 localnet 这个网络中的。
$ docker container run -d --name demo1 --network localnet alpine sleep 3600我们查看网桥的情况,demo1 的网络接口连接到了网桥 br-f55943e20201 上,如图所示。
$ brctl show
bridge name bridge id STP enabled interfaces
br-f55943e20201 8000.02421d9aa3e1 no vethf6a3fba
docker0 8000.0242be6b61dc no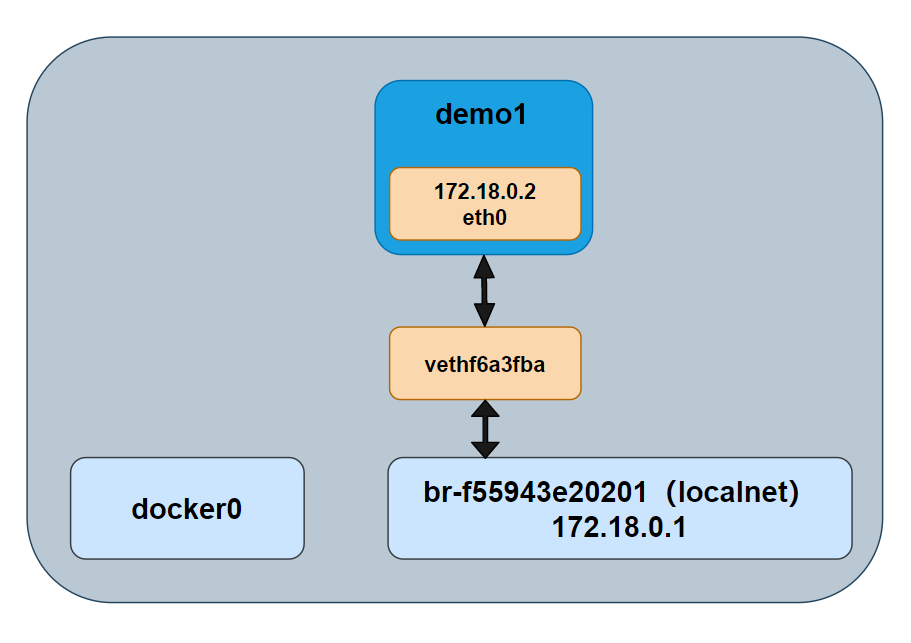
如果在相同的网络中继续接入新的容器,那么新接入的容器是可以通过 demo1 这个名称来 ping 通的。如下所示,我们创建了一个新的容器(demo2),并且在这个容器中直接 ping demo1 发现可以的 ping 通的。这是因为,demo2 运行了一个本地 DNS 解析器,该解析器会将该请求转发到 Docker 内部 DNS 服务器中。DNS 服务器中记录了容器启动时通过 --name 或者 --net-alias 参数指定的名称和容器之间的和映射关系。
之外,我们可以看到 demo1 的 IP 地址是 172.18.0.2,这个与网桥 br-f55943e20201 是处于同一个网段内的。
/ # ls
bin dev etc home lib media mnt opt proc root run sbin srv sys tmp usr var
/ # ping demo1
PING demo1 (172.18.0.2): 56 data bytes
64 bytes from 172.18.0.2: seq=0 ttl=64 time=0.230 ms
64 bytes from 172.18.0.2: seq=1 ttl=64 time=0.161 ms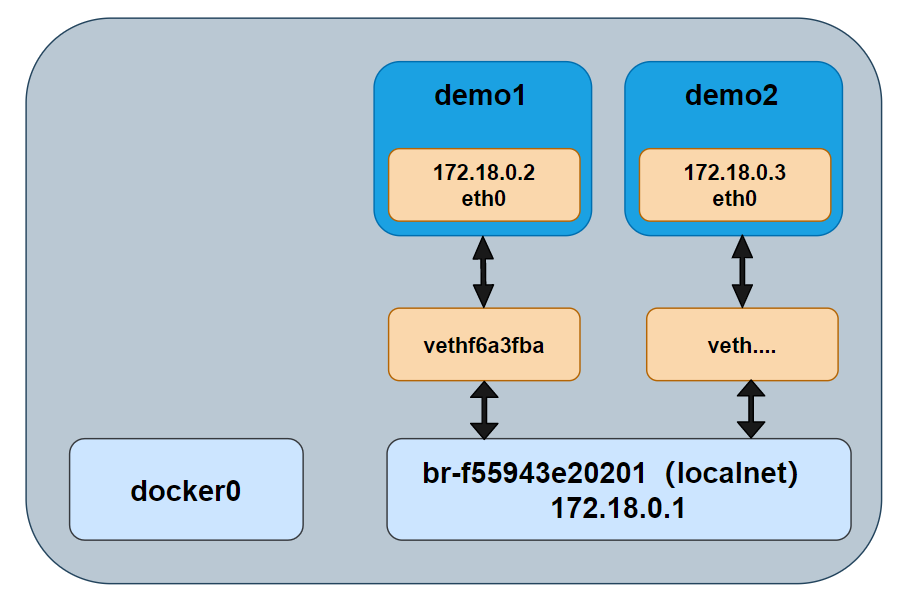
★Docker 默认的 bridge 网络是不支持通过 Docker DNS 服务进行域名解析的,自定义桥接网络是可以的。 ”
2.3. 暴露端口
同一个网络中的容器之间虽然可以互相 ping 通,但是并不意味着可以任意访问容器中的任何服务。Docker 为容器增加了一套安全机制,只有容器自身允许的端口,才能被其他容器所访问。如下所示,我们可以通过 docker container ls 命令可以看到容器暴露给其他容器访问的端口是 80,那么我们只能容器的 80 端口进行访问,而不能对没有开放的 22 端口进行访问。
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5a8dece3841d nginx "/docker-entrypoint.…" 3 minutes ago Up 3 minutes 80/tcp web
$ telnet 172.18.0.2 80
Trying 172.18.0.2...
Connected to 172.18.0.2.
Escape character is '^]'.
$ telnet 172.18.0.2 20
Trying 172.18.0.2...
telnet: Unable to connect to remote host: Connection refused复制
我们可以在镜像创建的时候定义要暴露的端口,也可以在容器创建时定义要暴露的端口,使用 --expose。如下所示,就额外暴露了 20、22 这两个端口。
$ docker container run -d --name web --expose 22 --expose 20 nginx
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4749dac32711 nginx "/docker-entrypoint.…" 12 seconds ago Up 10 seconds 20/tcp, 22/tcp, 80/tcp web复制
容器的端口暴露类似于打开了容器的防火墙,具体能不能通过这个端口访问容器中的服务,还得看容器中有无应用监听并处理来自这个端口的请求。
2.4. 端口映射
上面提到的桥接网络中的容器只能与位于相同网络中的容器进行通信,假如一个容器想对外提供服务的话,需要进行端口映射。端口映射将容器的某个端口映射到 Docker 主机端口上。那么任何发送到该端口的流量,都会被转发到容器中。如图所示,容器内部开放端口为 80,该端口被映射到了 Docker 主机的 10.0.0.15 的 5000 端口上。最终访问 10.0.0.15:5000 的所有流量都会被转发到容器的 80 端口。
Overlay
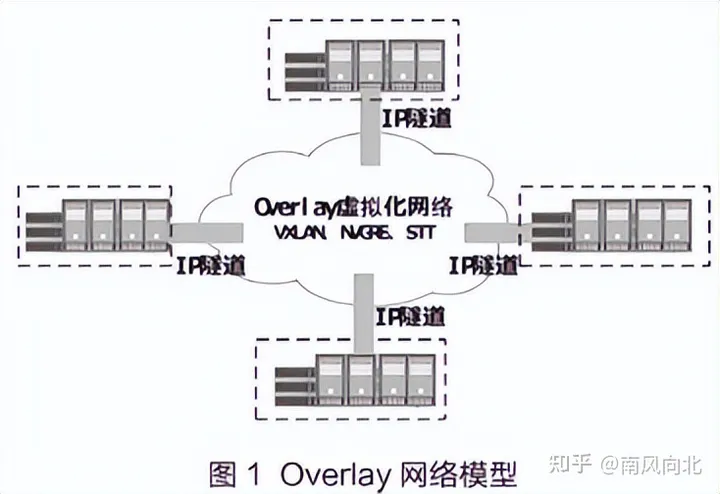
什么是Overlay网络
overlay(又叫叠加网络、覆盖网络)简单理解就是把一个逻辑网络建立在一个实体网络上。其在大体框架上对基础网络不进行大规模修改就能实现应用在网络上的承载,并能与其他网络业务分离,通过控制协议对边缘的网络设备进行网络构建和扩展,是SD-WAN以及数据真心等解决方案使用的核心组网技术。
为什么需要overlay网络
说到为什么需要用到Overlay网络就要提到它的对立面-Underlay
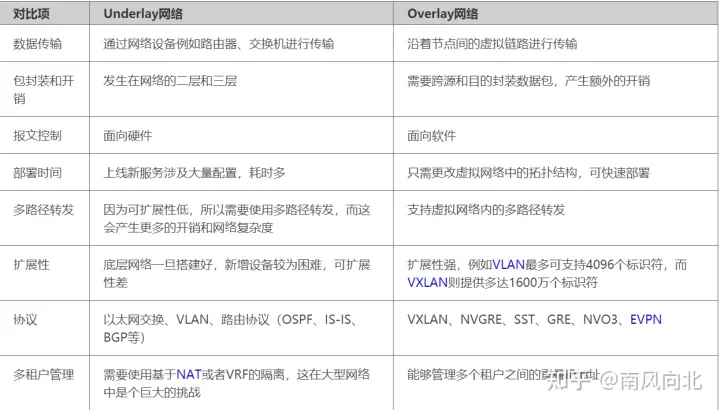
underlay是传统单层网络,是当前数据中心网络基础转发架构的网络。在Underlay网格中,互联的设备通过OSI七层模型中的网络层、数据链路层中的路由协议来确保之间IP连通性。但这些固定不变的规则带来了很大的问题,
其一,由于硬件根据目的的IP地址进行数据包的转发,传输路径不易修改、不够灵活,当业务进行修改需要手工对现有网络连接进行修改,耗时费力。
其二,underlay网络在互联网上不能提供完善的安全传输,且底层协议错综复杂无法良好的视线功能兼容
那么,为了解决Underlay带来的问题,Overlay网络便应运而生了!
Overlay网络协议和标准
Overlay网络有着各种网络协议和标准,包括VXLAN、NVGRE、STT、GRE、NVO3、EVPN等,下面我们来介绍Overlay的集中常见协议标准。
VXLAN:Overlay主流标准
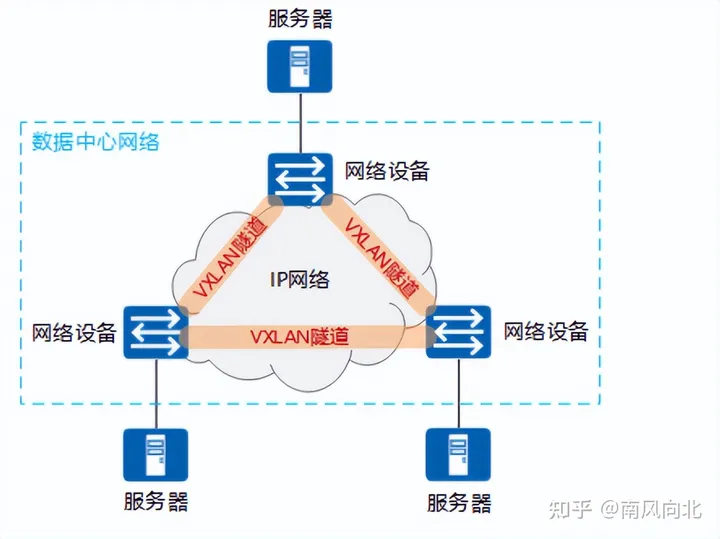
VXLAN(Virtual Exetensible LAN)是一种网络虚拟化技术,基于IP网络且采用MAC in UDP封装形式的二层VPN技术,可以解决改进大型云计算部署时的扩展的问题,是对vlan的一种扩展。
VXLAN可以给予已有的服务提供商或企业IP网络,分散的物理站点提供二层互联,并能够为不通过租户提供业务隔离,VXLAN技术通过建立VXLAN隧道,在现有网络架构上创建大量的虚拟可扩展局域网,不同的虚拟可扩展使用VNI(VXLAN Network Identifier虚拟可扩展局域网网络标识符)进行标识。
NVGRE
NVGRE是另一种Overlay技术,与VXLAN不同的是,NVGRE没有采用标准传输协议(TCP/UDP),而是借助通用路由封装协议GRE。
NVGRE使用GRE头部的低24位作为租户网络标识符(TNI),与VXLAN一样可以支持1600个虚拟网络。为了提供描述带宽利用率粒度的流,传输网络时需要使用GRE头,但是这导致NVGRE不能兼容传统负载均衡,这是NVGRE与VXLAN相比最大的区别也是NVGRE最大的不足,所以为了提高负载均衡能力建议每个NVGRE主机使用多个IP地址,确保更多流量能够被负载均衡。
STT
StatelessTransportTunnelingProtocol是一个术语术语,是Nicira提交的一种通道协议,与VXLAN和VGGRE相似,它将两个帧封装在一个ip消息包的payload中,并且在前面加上tcp头和STT头。请注意STT的tcp头是为了充分利用TSO,LRO,GRO等网卡特性而精心构造的。
Docker的Overlay
Overlay和Underlay网络协议区别及概述讲解 - 记忆流年 - 博客园 (cnblogs.com)
跨主机网络意味着将不同主机上的容器用同一个虚拟网络连接起来。这个虚拟网络的拓扑结构和实现技术就是网络模型。 物理网络模型中,连通多个物理网桥上的主机的一个简单办法是通过媒介直接连接这些网桥设备,各个主机处于同一个局域网(LAN)之中,管理员只需要确保各个网桥上每个主机的IP地址不相互冲突即可。类似地,若能够直接连接宿主机上的虚拟网桥形成一个大的局域网,就能在数据链路层打通各宿主机上的内部网络,让容器可通过自有IP地址直接通信。为避免各容器之间的IP地址冲突,一个常见的解决方案是将每个宿主机分配到同一网络中的不同子网,各主机基于自有子网向其他容器分配IP地址。
显然,主机间网络通信只能经由主机上可对外通信的网络接口进行,跨主机在数据链路层直接连接虚拟网桥的需求必然难以实现,除非借助宿主机间的通信网络构建的通信隧道进行数据帧转发。这种于某个通信网络之上构建出的另一个逻辑通信网络即Overlay网络或underlay网络。为支持容器跨主机通讯,Docker提供了Overlay driver,使用户可以创建基于VxLAN的overlay网络。VxLAN可以将二层数据封装到UDP进行传输,VxLAN 提供与 VLAN 相同的以太网二层服务,但是拥有更强的扩展性和灵活性。
Docker overlay网络需要一个key-value数据库用于保存网络状态信息,包括Network、Endpoint、IP等。Consul、Etcd 和 ZooKeeper 都是 Docker 支持的 key-vlaue 软件。
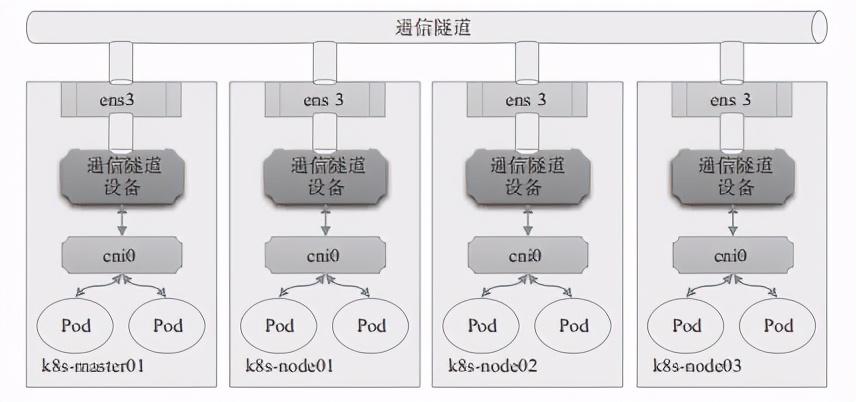
隧道转发的本质是将容器双方的通信报文分别封装成各自宿主机之间的报文,借助宿主机的网络隧道完成数据交换。这种虚拟网络的基本要求是各宿主机只需支持隧道协议即可,对于底层网络没有特殊要求。
docker会为每个overlay网络创建一个独立的network namespace,其中会有一个linux bridge br0,endpoint还是有veth pair实现,一段连接到容器中,另一端连接到namespace br0上。br0除了连接所有的endpoint,还会连接一个vxlan设备(即宿主机作为VETP的网卡),用于于其他host建立vxlan tunnel。容器之间的数据就是通过这个tunnel通信的。
Overlay网络建立在另一个计算机网络之上的虚拟网络 ,所以它不能独立出现,Overlay底层依赖的网络就是underlay网络,这俩个概念也经常成对出现。
Underlay网络是专门用来承载用户ip流量的基础架构层,它于Overlay网络之间的关系有点类似物理机与虚拟机。Underlay网络和物理机都是真正的存在的实体,它们分别对应着真实存在的网络设备和计算设备,而 Overlay 网络和虚拟机都是依托在下层实体使用软件虚拟出来的层级。
VXLAN协议是目前最流行的Overlay网络隧道协议之一,它也是由IETF定义的NVO3(Network Virtualization over Layer 3)标准技术之一,采用L2 over L4(MAC-in-UDP)的报文封装模式,将二层报文用三层协议进行封装,可实现二层网络在三层范围内进行扩展,将“二层域”突破规模限制形成“大二层域”。
XVLAN的显著优势之一就是对底层网络没有侵入性,管理员只需要在原有网络之上添加一些额外设备即可构建出虚拟的逻辑网络来。这个额外添加的设备称为VTEP(VXLAN Tunnel Endpoints),它工作于VXLAN网络的边缘,负责相关协议报文的封包和解包操作,从作用说相当于VXLAN隧道的出入口设备。
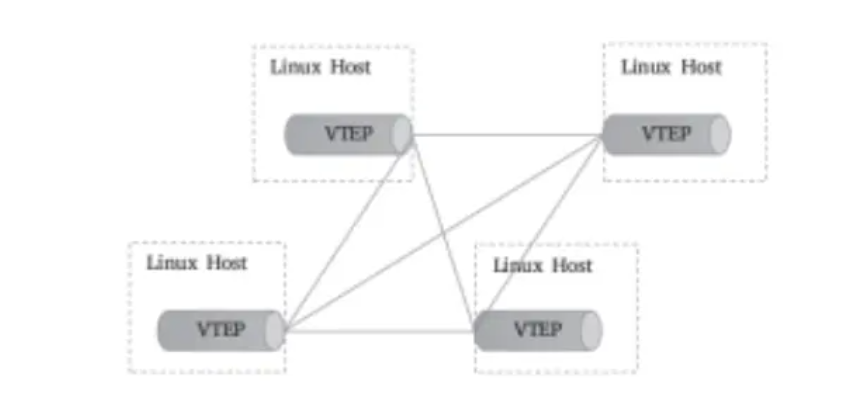
VTEP代表着一类支持VXLAN协议的交换机,而支持VXLAN协议的操作系统也可将一台主机模拟为VTEP,Linux内核自3.7版本开始通过vxlan内核模块原生支持此协议。于是,各主机上由虚拟网桥构建的LAN便可借助vxlan内核模块模拟的VTEP设备与其他主机上的VTEP设备进行对接,形成隧道网络。同一个二层域内的各VTEP之间都需要建立VXLAN隧道,因此跨主机的容器间直接进行二层通信的VXLAN隧道是各VTEP之间的点对点隧道,如图10-8所示。
对于Flannel来说,这个VTEP设备就是各节点上生成flannel.1网络接口,其中的“1”是VXLAN中的BD标识VNI,因而同一Kubernetes集群上所有节点的VTEP设备属于VNI为1的同一个BD。
类似VLAN的工作机制,相同VXLAN VNI在不同VTEP之间的通信要借助二层网关来完成,而不同VXLAN之间,或者VXLAN同非VXLAN之间的通信则需经由三层网关实现。VXLAN支持使用集中式和分布式两种形式的网关:前者支持流量的集中管理,配置和维护较为简单,但转发效率不高,且容易出现瓶颈和网关可用性问题;后者以各节点为二层或三层网关,消除了瓶颈。
然而,VXLAN网络中的容器在首次通信之前,源VTEP又如何得知目标服务器在哪一个VTEP,并选择正确的路径传输通信报文呢?
常见的解决思路一般有两种:多播和控制中心。
多播是指同一个BD内的各VTEP加入同一个多播域中,通过多播报文查询目标容器所在的目标VTEP。
而控制中心则在某个共享的存储服务上保存所有容器子网及相关VTEP的映射信息,各主机上运行着相关的守护进程,并通过与控制中心的通信获取相关的映射信息。Flannel默认的VXLAN后端采用的是后一种方式,它把网络配置信息存储在etcd系统上。
Linux内核自3.7版本开始支持vxlan模块,此前的内核版本可以使用UDP、IPIP或GRE隧道技术。事实上,考虑到当今公有云底层网络的功能限制,Overlay网络反倒是一种最为可行的容器网络解决方案,仅那些更注重网络性能的场景才会选择Underlay网络。