mysql派生表,物化表,临时表
派生表,物化表,看起来高大上,其实知识官方给某些场景下使用的临时表取个名字而已
派生表
派生表是用于存储子查询差生结果的临时表,所以本质上来说派生表也是临时表
explain select * from t1 inner join (
select distinct i1 from t3 where id in (3, 666, 990)
) as a on t1.i1 = a.i1+----+-------------+------------+------------+-------+---------------+---------+---------+--------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+---------+---------+--------+------+----------+----------------------------------------------------+
| 1 | PRIMARY | <derived2> | <null> | ALL | <null> | <null> | <null> | <null> | 3 | 100.0 | <null> |
| 1 | PRIMARY | t1 | <null> | ALL | <null> | <null> | <null> | <null> | 8 | 12.5 | Using where; Using join buffer (Block Nested Loop) |
| 2 | DERIVED | t3 | <null> | range | PRIMARY | PRIMARY | 4 | <null> | 3 | 100.0 | Using where; Using temporary |
+----+-------------+------------+------------+-------+---------------+---------+---------+--------+------+----------+----------------------------------------------------+
通过explain结果可以看到select中的子查询会产生一个派生表,存储子查询的结果,然后用t1和派生表进行连接操作
物化表
物化表(Materialized View),也是用于存储查询差生结果的临时表,这个子查询特质where子句中条件里的子查询
物化表由俩种使用场景
- 对子查询进行半连接优化时,使用物化策略
- In 子查询转换为SUBQUERY,UNCACHEABLE SUBQUERY的exits相关子查询把子查询的结果物化,避免对于主查询符合条件的每一条记录,子查询都要执行一次从原表里读取数据
explain select * from t1 where t1.i1 in (
select i1 from t3 where id in (3, 666, 990, 887, 76) and i2 > 16384
)+----+--------------+-------------+------------+-------+---------------+---------+---------+--------+--------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------+-------------+------------+-------+---------------+---------+---------+--------+--------+----------+----------------------------------------------------+
| 1 | SIMPLE | <subquery2> | <null> | ALL | <null> | <null> | <null> | <null> | <null> | 100.0 | <null> |
| 1 | SIMPLE | t1 | <null> | ALL | <null> | <null> | <null> | <null> | 8 | 12.5 | Using where; Using join buffer (Block Nested Loop) |
| 2 | MATERIALIZED | t3 | <null> | range | PRIMARY | PRIMARY | 4 | <null> | 5 | 33.33 | Using where |
+----+--------------+-------------+------------+-------+---------------+---------+---------+--------+--------+----------+----------------------------------------------------+通过上面的explain结果可以看到,in子查询的结果物化之后(select_type = MATERIALIZED)和 t1 表进行连接操作
子查询由五种优化策略
- 子查询由五种优化策略,子查询表上拉(table pullout)
- 重复值消除(duplicate weedout)
- 首次匹配(first match)
- 松散扫描(loose scan)
- 物化连接(materialzation)
我在执行上面的 select 语句的 explain 时,通过计算成本选择的是重复值消除策略,为了演示,我用 set optimizer_switch='duplicateweedout=off' 禁用了重复值消除策略
explain
select * from t1 where t1.i1 in (
select i1 from t3 where id in (3, 666, 990, 887, 76) and i2 > rand() * 100
) and t1.str1 > 'abc';+----+----------------------+-------+------------+-------+---------------+---------+---------+--------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+----------------------+-------+------------+-------+---------------+---------+---------+--------+------+----------+-------------+
| 1 | PRIMARY | t1 | <null> | ALL | <null> | <null> | <null> | <null> | 8 | 33.33 | Using where |
| 2 | UNCACHEABLE SUBQUERY | t3 | <null> | range | PRIMARY | PRIMARY | 4 | <null> | 5 | 33.33 | Using where |
+----+----------------------+-------+------------+-------+---------------+---------+---------+--------+------+----------+-------------+
通过上面的 explain 结果,实际上没有体现出来使用了物化表,这需要用上另一个杀手锏了(optimizer_trace)
先执行以下命令,开启 optimizer_trace
set optimizer_trace="enabled=on";
set optimizer_trace_max_mem_size=1048576;然后执行sql语句
-- 注意:
-- 查询 information_schema.optimizer_trace 表的 SQL 要和前面的 SQL 一起执行
-- 不然查不到执行过程的信息
select * from t1 where t1.i1 in (
select i1 from t3 where id in (3, 666, 990, 887, 76) and i2 > rand() * 100
) and t1.str1 > 'abc';
select * from information_schema.optimizer_trace;{
"transformation": {
"select#": 2,
"from": "IN (SELECT)",
"to": "materialization",
"chosen": true,
"unknown_key_1": {
"creating_tmp_table": {
"tmp_table_info": {
"row_length": 5,
"key_length": 4,
"unique_constraint": false,
"location": "memory (heap)",
"row_limit_estimate": 3355443
}
}
}
}
}
上面的 JSON 是摘取了 trace 结果中的一段,可以看到是把 IN 子查询的结果集物化到临时表了,并且使用的是 Memory 引擎的临时表
临时表
临时表,除了派生表,物化表之外,其它会用到临时表的地方,都是为了用空间换时间的,主要由
- group by 不能使用索引时
- distinct 不能使用索引时
- unioin
子查询是如何执行的
不想关查询执行方式
select * from s1 where key1 in (select common_field from s2)
- 单独执行子查询
- 将子查询结果作为外层参数,并执行外层查询
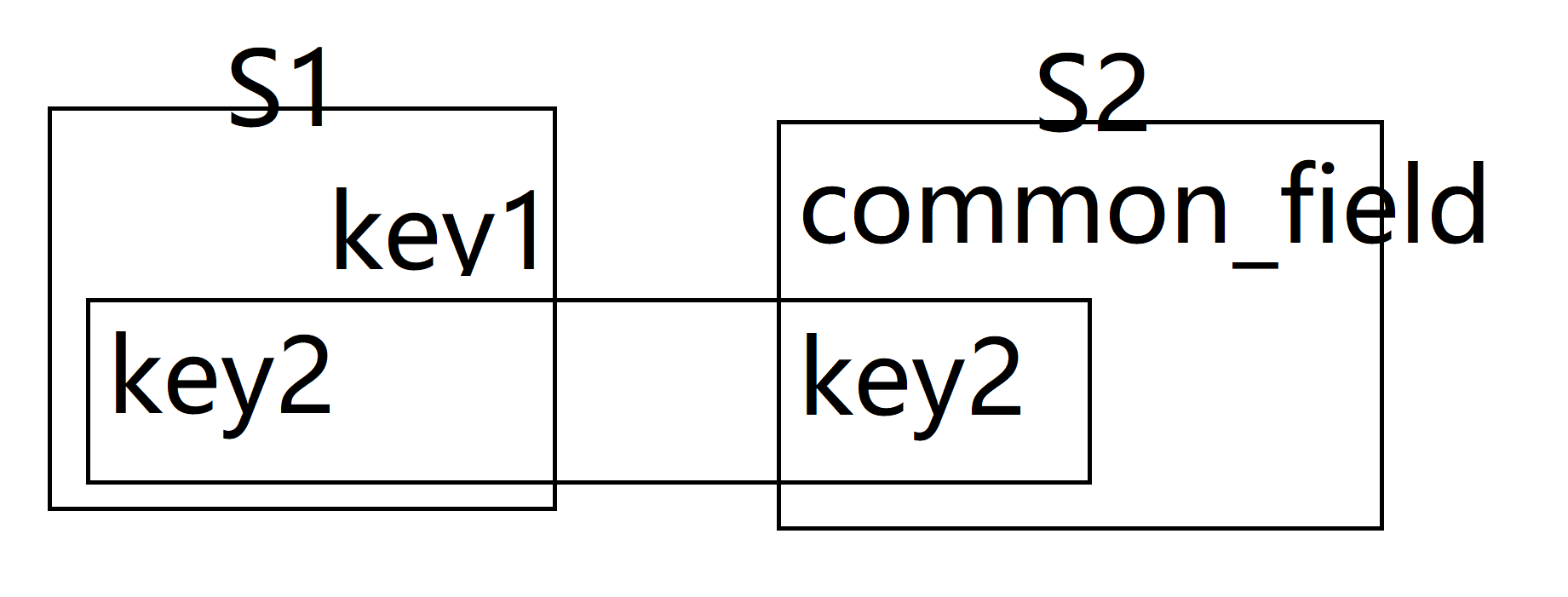
简单理解为key1匹配到了就自动返回s1的key1字段
子查询优化方式
二分优化
如果key1 in (1,3,4,5,6,7)这种语句,in里面的若干参数会优先被排序,如果查询时不能利用索引形成若干扫描区间,那么将会对已排好序的参数进行二分查找,加速in表达式的效率
in子查询优化
对于不相关的子查询 select * from t1 where key1 in (select m1 from s2 where key2 = 'a')
如果子查询单独查询,返回结果非常多,那将导致效率低下,甚至内存可能放不下这么多的结果,对于这种情况
Mysql提出了物化表的概念,即将子查询的结果放到一张临时表中(也称物化表)临时表的特征如下
- 临时表中的列就是子查询的列
- 临时表中的记录将被去重
临时表的去重通过建立唯一索引的方式去重,所有的列将别当做联合唯一索引,去重可以让临时表更节省空间,并且不会造成对结果的影响。
一般情况下,临时表不会过大的话,会放在内存中,即memory表,并且为其建立hash索引,通过hash索引可以更快的搜到临时表中对应的结果
如果临时表过大将被放在磁盘中,索引结构也会转换为b+树,通过B+树叶可以快速找到记录
物化表转连接
物化表也是一张表,有了物化表后可以考虑将原本的物化表建立连接查询,针对之前的SQL
select * from t1 where key1 in (select m1 from s2 where key2 = 'a')如果t1表中的key1在物化表中的m1里存在,则加入结果集,对物化表说,如果m1在t1表中key1里存在,则加入结果集
此时可以将子查询转化为内连接查询,转换连接查询后,就可以计算连接成本,选择最优的执行计划
以t1作为驱动表的成本计算如下
- 子查询转物化表需要的成本
- 扫描s1表的成本
- s1表记录*通过key1对物化表进行单标访问的成本
以物化表作为驱动的表成本计算如下
- 子查询转物化表需要的成本
- 扫描物化表需要的成本
- 物化表记录*通过m1对t1表进行单表访问的成本
mysql将选择二者之间成本较低的进行执行
半连接(semi join)
通过物化表可以将子查询转换为连接查询,MySQL在物化表的基础上做了更进一步的优化,即不建立临时表,直接将子查询转为连接查询。
select * from t1 where key1 in (select m1 from s2 where key2 = 'a')上面的SQL最终要达到的效果是,如果t1表中的记录key1存在于子查询s2表中的m1列中,则加入结果集,与下面的SQL较为相似:
select t1.* from t1 innert join s2 on t1.key1 = s2.m1 where s2.key2 = '1'乍一看好像满足转换趋势,不过要考虑三种情况
- 对于t1表,s2结果集中如果没有满足on条件的,不加入结果集
- 对于t1,表,如果结果集中有且只有一条符合条件的,加入结果集
- 对于t1表,s2结果集中有多条符合条件的,那么该条记录多次加入结果集
对于1,2的内连接,都是符合上面子查询要求的,但是结果3,在子查询中只会出现一条记录,但是连接查询中会出现多条,因此二者不能完全等价,但是连接查询效果有非常好,因此提出了半链接的概念
对于t1表,只关心s1表中有没有符合条件的记录,而不关心有多少条记录与之匹配,最终的结果集只保留t1表中的就行了,因此MySQL内部的半连接语法类似是这么写的
select t1.* from t1 semi join s2 on t1.key1 = s2.m1 where s2.key2 = '1' #(这不能直接执行,半连接只是一种概念,不开放给用户使用)半连接的实现方式有下面几种:
- 子查询中的表上拉
当子查询的列只有逐渐或者唯一二级索引时,直接将子查询提升到外层来连接查询
例如 select * from t1 where key1 in (select m1 from s2 where key2 = 'a')
如果m1是s2的主键或唯一索引,那么语句直接被优化为:
select t1.* from t1 inner join s2 on t1.key1 = s2.m1 where s2.key2 = '1'
因为子查询中的主键或唯一索引本身就是不重复的,因此直接提升做连接,也不会出现重复值。
- 重复值消除
例如 select * from t1 where key1 in (select m1 from s2 where key2 = 'a')
如果m1不是s2的主键或唯一索引,那么优化后的语句依然可以是:
select t1.* from t1 inner join s2 on t1.key1 = s2.m1 where s2.key2 = '1'
不过此时我们需要一张临时表来做帮忙:
create table tmp (
id int primary key
);这样在连接查询时,每当有s1的记录加入结果集时,则把该记录的id放到这个临时表中,如果添加失败,说明之前有重复的数据已经添加过了,直接丢弃就好,这样就保证了数据不会重复。
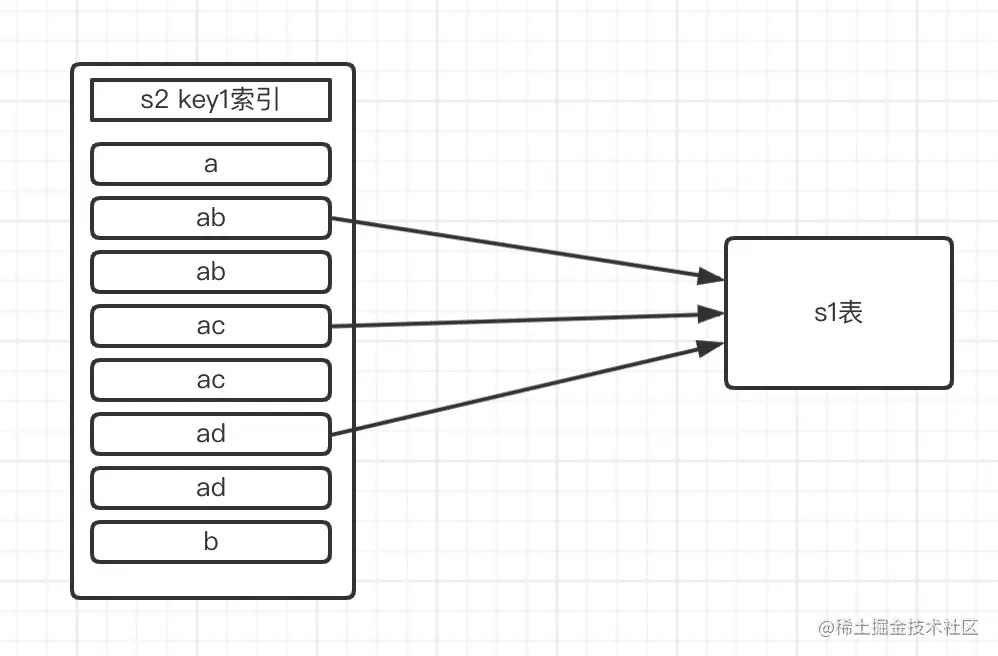
- 松散扫描
select * from s1 where key3 in (select key1 from s2 where key1 > 'a' and key1 < 'b')对于上面的查询,假设 key1 是 s2 的索引,那么优化为半连接可以是,扫描key1索引,如下图:
我们在key1索引中,得到符合搜索条件的值,并且相同的值只取第一条与s1去匹配,找到了则加入最终的结果集,这种虽然是扫描索引,但是只取第一条匹配的记录,被称为松散扫描。
- 半连接就是上面提到的物化表转连接方式
- 首次匹配就是上面提到的相关子查询的执行方式
select * from s1 where key1 in (select common_field from s2 where s1.key2 = s2.key2)- 先从外查询中取一条记录
- 从外查询中取出子查询设计到的值,并执行子查询
- 子查询的结果与where做匹配,成立则记录加入结果集,否则就丢弃
- 重复执行步骤1
对于相关子查询:
select * from t1 where key1 in (select m1 from s2 where t1.key3 = s2.key3)
可以很方便的转换为半连接:
select * from t1 semi join s2 on t1.key1 = s2.m1 and t1.key3 = s2.key3
半连接后就可以用 重复值消除、松散扫描、首次匹配 这几种方式来进行查询,但是需要注意的是,相关子查询是无法使用物化表的,因为物化表的条件是子查询并不依赖外层查询的值,可以单独直接直接子查询转成物化表。
半连接的适用条件
并非所有的in子查询语句都可以转为半连接,只有下方类型语句才可以:
select ... from outer_tables where expr in (select ... from inner_tables ...) and ...
select ... from outer_tables where (o1,o2,...) in (select o1,o2,... from inner_tables ...) and ...
- 子查询必须是与in操作符组合的布尔表达式,并在外层查询的where或者on子句中出现
- 外层查询可以有其他的查询条件,不过必须使用 and 操作符与 in 操作符连接起来
- 子查询必须是一个单一的查询,不能是union连接的若干个子查询
- 子查询不能包含group by、having语句或聚合函数
半连接的不适用条件(不能转成semi join的SQL)
在外层查询的where条件中,存在其他搜索条件使用or操作符与in子查询组成的布尔表达式
select * from s1 where key1 in (select m1 from s2 where key3 = 'a') or key2 > 100
使用not in,而不是 in
select * from s1 where key1 not in (select m1 from s2 where key3 = 'a')
位于 select 子句中
select key1 in (select m1 from s2 where key3 = 'a') from s1
子查询中包含 group by 、having 或者 聚合函数
select from s1 where key1 not in (select count() from s2 group by key1)
子查询包括union
select * from s1 where key1 in (select m1 from s2 where key3 = 'a' union select m1 from s2 where key3 = 'b')
对于无法转为半连接的子查询优化
- 物化
select * from s1 where key1 not in (select m1 from s2 where key3 = 'a')
对于not in,无法半连接,可以直接将子查询物化,然后判断结果是否在物化表中,进行速度加快。
- 转为 exists
在where或on子句中的in子查询无论是相关还是不相关的,都可以转为exists子查询,通用的转换表示如下:
outer_expr in (select inner_expr from ... where subquery_where)
可以转换为
exists (select inner_expr from ... where subquery_where and outer_expr = inner_expr)
转换成exists的好处是,可以有效的利用索引,例如:
select * from s1 where key1 in (select key3 from s2 where s1.common_field = s2.common_field) or key2 > 1000
假设上表中的 common_field 并非索引,但是key1和key3是索引,那么上面中直接走子查询将无法利用索引,但是转换为exists如下:
select * from s1 where exists (select 1 from s2 where s1.common_field = s2.common_field and s1.key1 = s2.key3) or key2 > 1000
如果in不符合半连接的条件,那么将从子查询物化和exists的转换之间选一个成本更低的来执行。
- any/all 子查询优化
对于非相关的any/all子查询, 一般可以转换成我们熟悉的的方式来进行:
原始表达式 转换为
| 原始表达式 | 转换为 |
|---|---|
| < any(select inner_expr ...) | < (select max(inner_expr ...)) |
| > any(select inner_expr ...) | > (select min(inner_expr ...)) |
| < all(select inner_expr ...) | < (select min(inner_expr ...)) |
| > all(select inner_expr ...) | > (select max(inner_expr ...)) |
- [not]/exists 子查询的优化
对于[not]/exists的非相关子查询,先执行子查询,然后重写原先的查询语句,如下:
select * from s1 where exists (select 1 from s2 where key1 = 'a') or key2 > 100
上面的子查询是不相关子查询,可先执行子查询,如果子查询结果为true,原先的语句可重写如下:
select * from s1 where exists true or key2 > 100
进一步简化:
select * from s1 where exists true
对于[not]/exists的相关子查询,将按照上文中的 相关子查询执行方式 进行执行,如果子查询中的条件是索引,可加快查询速度。
- 派生表的优化
派生表一般会被写入到一个内部的临时表中,然后将这个表作为普通的表来查询。
- 延迟物化
如下SQL:
select from (select from s1 where key1 = 'a') as derived_s1 innert join s2 on derived_s1.key1 = s2.key1 where s2.key2 = 1
因为SQL的where条件中,判断了s2的key2有无等于1的数据,为了减少临时表的生成,会先去查找s2表中是否有key2=1的数据,如果没有就不生成派生表了。
- 派生表与外层合并
如下SQL:
select from (select from s1 where key1 = 'a') as derived_s1
上面的SQL可直接优化为:
select * from s1 where key1 = 'a'
再如刚刚的SQL:
select from (select from s1 where key1 = 'a') as derived_s1 innert join s2 on derived_s1.key1 = s2.key1 where s2.key2 = 1
如果s2中存在数据,我们可以将派生表和外层查询合并,同时将派生表的搜索条件放到外层查询的搜索条件中:
seelct * from s1 innert join s2 on s1.key1 = s2.key1 where s1.key1 = 'a' and s2.key2 = 1
此处成功消除派生表。
当派生表中有以下的函数或语句时,不可与外层查询合并:
聚合函数:max、min、sum等
distinct
group by
having
limit
union 或 union all
派生表对应的子查询select子句中含有另一个子查询
转载自