ConcurrentHashMap
1.7
JDK1.7中的ConcurrentHashMap采用够了分段锁的形式,每一个段为一个Segment类,它类似HashMap的结构,内部有一个Entry数组,数组的每个元素是一个链表。同时Segment继承自ReentrantLock
在HashEntry中采用了volatile来修饰了HashEntry的当前值和next元素的值。所以get方法在获取数据的时候是不需要枷锁的,这样就大大提升了执行效率。
在执行put方法的时候会尝试获取trylock如果获取锁失败,说明存在竞争,那么将通过scanAndLockForPut()方法执行自旋,当自旋的次数达到MAX_SCAN_RETRIES时会执行阻塞锁,直到获取成功
static final int MAX_SCAN_RETRIES =
Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 首先尝试获取锁,获取失败则执行自旋,自旋次数超过最大长度,后改为阻塞锁,直到获取锁成功。
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}阻塞锁
与自旋锁对应,阻塞锁不会进行自旋,而是进入阻塞状态。当获得相应的信号(被外界唤醒、到休眠时间)时,线程进入就绪态,继续竞争临界资源。
JAVA中,能够进入退出、阻塞状态或包含阻塞锁的方法有 ,synchronized 关键字(其中的重量锁),ReentrantLock,Object.wait()、notify(), LockSupport.park()、unpart() (j.u.c经常使用) 。
优缺点
优点:阻塞的线程不会占用CPU太多时间,不会有CPU空转的情况,不会导致CPU占用率过高。竞争激烈的情况下,性能明显高于自旋锁。
缺点:竞争不激烈的情况下,线程的切换会浪费太多时间。
1.8
在JDK中,放弃了segment这种分段锁的形式,而是采用了CAS+Syncronized的方式来保证并发操作的,采用了HashMap一样的结构,直接用数组加链表,在链表长度大于8的时候为了提高查询效率会将链表转为红黑树(链表定位数据的时间复杂度为O(N),红黑树定位数据的时间复杂度为O(logN))。
在代码上也和JDK1.8的HashMap很像,也是将原先的HashEntry改为了Node类,但还是使用了volatile修饰了当前值和next的值。从而保证了在获取数据时候的高效。
在java1.8中的put方法主要是为了保证线程安全做了一系列的措施
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}- 进行hash
- 判断是否需要初始化数据结构
- 根据key定位到当前的Node,如果当前位置空,可以写入数据,利用CAS机制尝试写入数据,如果写入失败,说明存在竞争,将会通过自旋来保证成功
- 如果当前的hashcode值等于moved则需要扩容(扩容时也是用了CAS来保证县城安全)
- 如果上面4部都不满足,则通过synchronized阻塞锁将数据写入
- 如果数据量大于TREEIFY_THRESHOLD需要转换为红黑树
java的1.8ConcurrentHashMap的get方法比较简单
- 根据
key的hashcode寻址到具体的桶上。 - 如果是红黑树则按照红黑树的方式去查找数据。
- 如果是链表就按照遍历链表的方式去查找数据。
size方法
JDK1.8中的ConcurrentHashMap的size()方法的源码如下:
/**
* {@inheritDoc}
*/
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}这个方法最大会返回int的最大值,但是ConcurrentHashMap的长度有可能超过int的最大值。
在JDK1.8中增加了mappingCount()方法,这个方法的返回值是long类型的,所以JDK1.8以后更推荐用这个方法获取Map中数据的数量。
/**
* @return the number of mappings
* @since 1.8
*/
public long mappingCount() {
long n = sumCount();
return (n < 0L) ? 0L : n; // ignore transient negative values
}无论是size()方法还是mappingCount()方法,核心方法都是sumCount()方法。
源码如下:
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}在上面sumCount()方法中我们看到,当counterCells为空时直接返回baseCount,当counterCells不为空时遍历它并垒加到baseCount中。
先看baseCount
/**
* Base counter value, used mainly when there is no contention,
* but also as a fallback during table initialization
* races. Updated via CAS.
*/
private transient volatile long baseCount;baseCount是一个volatile变量,那么我们来看put()方法执行的时候是如何使用baseCount的,在put方法的最后一段代码中会调用addCount()方法,而addCount源码如下
/**
* Adds to count, and if table is too small and not already
* resizing, initiates transfer. If already resizing, helps
* perform transfer if work is available. Rechecks occupancy
* after a transfer to see if another resize is already needed
* because resizings are lagging additions.
*
* @param x the count to add
* @param check if <0, don't check resize, if <= 1 only check if uncontended
*/
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}首先对baseCount做CAS自增操作
如果并发导致baseCount的CAS失败了,则使用counterCells进行CAS
如果counterCells的CAS也失败了,那么则进入fullAddCount()方法,fullAddCount()方法中会进入死循环,直到成功为止。
那么counterCells到底是个啥呢
/**
* A padded cell for distributing counts. Adapted from LongAdder
* and Striped64. See their internal docs for explanation.
*/
@sun.misc.Contended static final class CounterCell {
volatile long value;
CounterCell(long x) { value = x; }
}一个使用了 @sun.misc.Contended 标记的类,内部一个 volatile 变量。@sun.misc.Contended 这个注解是为了防止“伪共享”。
那么什么是伪共享呢?
缓存系统中是以缓存行(cache line)为单位存储的。缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节。当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
所以伪共享对性能危害极大。
JDK 8 版本之前没有这个注解,JDK1.8之后使用拼接来解决这个问题,把缓存行加满,让缓存之间的修改互不影响。
总结
无论是JDK1.7还是JDK1.8中,ConcurrentHashMap的size()方法都是线程安全的,都是准确的计算出实际的数量,但是这个数据在并发场景下是随时都在变的。
java缓存伪共享false sharing
在java中,运行在俩个不同cpu核心上的俩个线程,而这俩个变量恰好存储在同一个cpu cache line中,就会发生错误共享。当第一个县城修改缓存行中其中 一个变量时,其他引用此
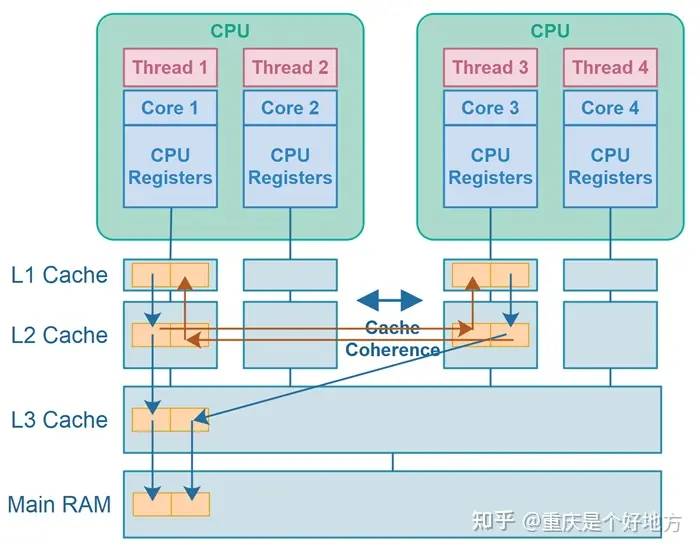
该图显示了运行在不同CPU上的两个线程,它们写入不同的变量(变量存储在同一CPU缓存行中),从而导致伪共享。在上图中,使缓存行变脏用蓝线表示,缓存行失效用红色箭头表示。
当一个CPU往缓存行写入数据时,缓存线会变脏。然后,其他cpu将无法读取此缓存行的数据,知道缓存行数据被更新。
缓存失效后的缓存刷新可以通过缓存一致性机制进行,也可以通过从主RAM重新加载缓存行进行。
在刷新缓存行之前,不允许CPU 访问该缓存行。
伪共享会导致性能损失
当缓存行因另一个CPU更改了该缓存线内的数据而失效时,则需要刷新失效的缓存行——从三级缓存或通过缓存一致性机制。因此,如果CPU需要读取失效的缓存行,它必须等待缓存行刷新。这会导致性能下降。CPU等待缓存行刷新的时间被浪费了,这意味着CPU可以在这段时间内执行更少的指令。
我们了解了缓存cache之后,缓存是以行为单位存在在cache中的,通常而言,一个缓存行大概是64byte。对于java类而言,一个javalong的对象长度为8字节,因此一个缓存行就是8个long的长度。因此,在你访问一个long数组的时候,当数组中有一个值被加载到缓存中的时候,它会额外加载另外7个值,以至于遍历数组的速度可以非常快。因此对于连续存储在内存块的数据结构,都是可以非常快速的遍历的。 对于链表,由于数据不连续,因此很难享受到这个优势。也就是说,CPU处理内存的宽度是64byte。但是我们程序中的基本的变量都会小于这个宽度,因此这会带来另外一个问题,这就是伪共享。 伪共享的意思就是说,当线程1在使用变量x的时候,CPU会将X相连的部分共64字节全部都加载到core的L1中。如果此时线程2需要使用的y,但是y在此时已经做为x相邻的64字节的一部分被加载到了L1中。由于L1是按核心各自独立的,因此这个时候就会对这个缓存行产生了竞争。这就是伪共享。 实际上CPU的处理可能比这个描述复杂,但是对于这种竞争的情况,一般在MESI协议的CPU上,是会互相影响的。 在MESI协议中,如果两个不同的处理器都需要操作相同的缓存行,那么就会导致RFO请求。
class Counter {
@Contended("a")
public volatile long count1 = 0;
@Contended("b")
public volatile long count2 = 0;
}
public class T {
public static void main(String[] args) {
Counter counter1 = new Counter();
Counter counter2 = counter1;
long iterations = 1_000_000_000;
Thread thread1 = new Thread(() -> {
long startTime = System.currentTimeMillis();
for(long i=0; i<iterations; i++) {
counter1.count1++;
}
long endTime = System.currentTimeMillis();
System.out.println("total time: " + (endTime - startTime));
});
Thread thread2 = new Thread(() -> {
long startTime = System.currentTimeMillis();
for(long i=0; i<iterations; i++) {
counter2.count2++;
}
long endTime = System.currentTimeMillis();
System.out.println("total time: " + (endTime - startTime));
});
thread1.start();
thread2.start();
}
}在Java 8和9中,Java有@Contemped注释,它可以用空字节填充类中的字段(当存储在RAM中时,在字段之后),这样该类对象中的字段就不会存储在同一个CPU缓存行中。下面是前面示例中的计数器类,其中一个字段中添加了@contemped注释
最后需要注意下,@Contended注解默认只用于Java核心类
我们可以看到,再运行的时候设置了-XX:-RestrictContended之后,通过注解的方式可以生效。Contended注解必须修改jvm运行参数-XX:-RestrictContended,否则会被jvm忽略。