Kafka
简介
作用
MessageQueue,消息队列中间件.很多人说MQ通过将消息队列接收分离来实现应用程序的异步和解耦,这给人的感觉是MQ是异步的,用来解耦的,但这个只是MQ的效果而不是目的.MQ的真正目的是为了通讯,屏蔽底层复杂的通讯协议,定义了一套应用层的,更加简单的通讯协议.一个分布式系统中俩个模块要么是HTTP,要么是自己开发的RPC,单着俩种协议其实都是原始的协议.HTTP协议很难实现俩段通讯--模块A可以调用B,B也可以主动调用A,如果要做到这个俩段都要背上webserver,而且还不支持长链接.TCP就更加原始了,粘包心跳,私有协议,想一想就头皮发麻.MQ要做的就是在这些协议上构建一个简单的协议--生产者消费者模型.MQ带给我门的协议本身具体的通讯协议,而是更高层次的通讯模型,它定义了俩个对象--发送数据的叫生产者;接受数据的叫消费者,提供一个SDK让我们可以自定义自己的生产者和消费实现消息通讯而无视底层通讯协议
流派
目前消息队列选型有很多种
- rabbitMQ:简单,可玩性功能性强
- rocketMQ:阿里内部根据kafka的内部执行原理,手写的一个消息队列中间件.性能与kafka相比肩,除此外封装了更多的功能
- kafka :全球消息处理性能最好最快的一款mq
- zeroMQ
主要分为有broker的MQ和无Broker的MQ
有Broker的MQ
这个流派通常有一台服务器作为Broker,所有消息都通过它中转.生产者吧消息发送给它就结束自己的任务了,Broker则主动把消息推送给消费者(或者消费者主动轮询),简单可以理解为有broker的消息队列就是以中间件的形式存在的
重Topic
kafka,JMS(ActiveMQ)就属于这个流派,生产者会发送key和数据到Breker,由Broker比较key之后决定发给哪个消费者.这种模式是最常见的模式,是我们对MQ最多的映像.这这种模式下一个topic往往是一个比较大的数据概念,甚至一个系统中可能只有一个topic
kafka,rocketMQ,AvtiveMQ
轻Topic
这种代表是RabbitMQ(或者说是AMQP).生产者发送key和数据,消费者定义订阅的队列,broker收到数据后会通过一定的逻辑计算出key对应的队列,然后把数据交给队列
RabbitMQ
无Broker
无Broker的MQ代表是ZeroMQ.该作者非常的睿智,它意识到MQ是更高级的Socket,是解决通讯问题的.所以ZeroMQ被设计成了一个"库"而不是一个中间件,这种实现也可以达到没有broker的目的
节点之间通讯的消息都是发送到彼此的队列中,每个节点既是生产者又是消费者.ZeroMq做的事情就是封装出一套类似于Socket的API完成发送数据读取数据
ZeroMQ其实就是一个跨语言的,重量级的Actor模型邮箱库.可以把自己的程序想想成一个Actor,ZeroMq就是提供邮箱功能的库;zeroMQ可以实现同一台机器的RPC通讯也可以实现不同机器的TCP,UDP通讯
俩种模式
点对点:消费者主动拉拉取数据,消息收到后清除消息
发布订阅模式
- 可以有多个topic主题
- 消费者消费数据后,不删除数据
- 每个消费者互相独立,都可以消费到数据
kafka介绍
kafka最初是由linkedin公司开发,是一个分布式,支持分区(partition),多副本(replica),基于zookeeper协调的分布式消息系统,它最大的特性就是可以实时处理大量数据以满足各种需求场景
场景
- 日志:可以用kafka手机各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop,hbase,solr等
- 消息系统:解耦生产者和消费者,缓存消息等
- 用户活动跟踪,kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页,搜索,点击等活动,这些信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者封装到hadoop,数据仓库中做离线分析和挖掘
- 运营指标:kafka经常用来记录运营监控数据.包括手机各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告
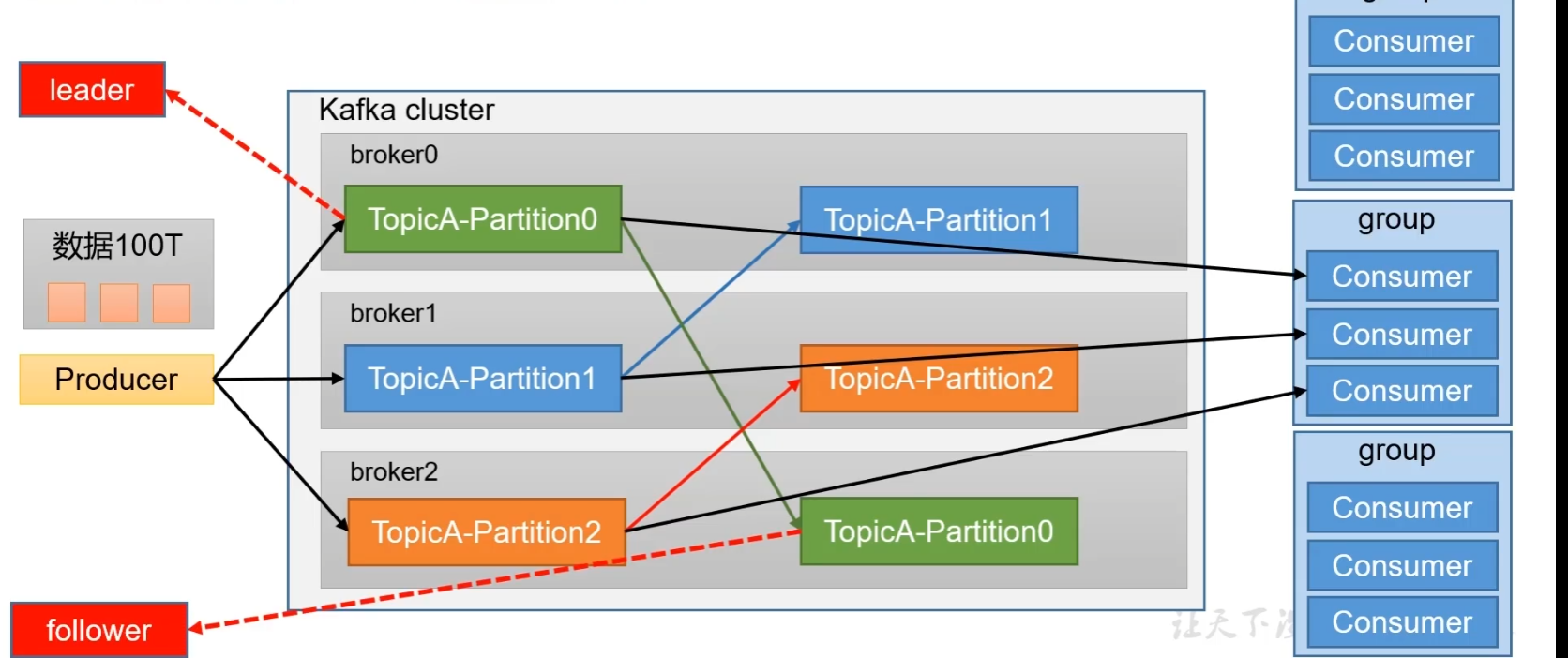
架构
为方便扩展并提高吞吐量,一个topic分为多个partition
配合分区的设计,提出消费者组的概念,组内每个消费者并行消费
为提高可用性,为每个partition增加若干个副本,leader和follower,无论是生产还是消费数据都是对leader来操作的,当leader挂掉后,follower会取而代之
部分数据记录在zookeeper中,zookeeper记录了整个集群中哪些服务器上线了,还会记录每一个分区谁是leader,kafka2.8.0之后可以配置不采用zookeeper
安装kafka
config/server.properties
#当前机器的唯一标识
broker.id=0
num.network.threads=3
# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# 存储数据的地方默认是(/tmp/kafka-logs)是一个临时路径
log.dirs=/opt/module/kafka/datas
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
#
zookeeper.connect=localhost:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
要求
jdk,和启动zk
./kafka-server-start.sh -daemon ../config/server.properties #-daemon 表示守护执行在zk中 ls /就可以了
没有的话安装下jdk
apt install openjdk-8-jdk-headless查看zk的节点
[admin, brokers, cluster, config, consumers, controller, controller_epoch, feature, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper]查看是否启动成功
ps -aux |grep properties基本操作和概念
| 名称 | 解释 |
|---|---|
| Broker | 消息中间件处理节点,一个kafka节点就是一个broker,一个或多个broker可以组成一个kafka集群 |
| Topic | kafka根据topic对消息进行分类,发布到kafka集群的每条消息都要指定一个topic |
| producer | 消息生产者, 向broker发送消息的客户端 |
| Consumer | 消息消费者,从Broker读取消息的客户端 |
| ConsumerGroup | 每个Consumer属于一个特定的Consumer Group,一条消息可以被多个不同的Customer Group消费,但是一个ConsumerGroup中只能有一个Consumer能够消费该消息 |
| partition | 物理上的概念,一个topic可以分为多个partition,每个partition都是有序的 |
创建topic
topic,消息主题,可以实现消息的分类,不同消费者订阅不同的消息
执行下列命令创建名为test的topic,这个topic只有一个partition,并且备份因子为1
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test新版本
./kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test查看topic
./kafka-topics.sh --list --zookeeper localhost:2181新版本
./kafka-topics.sh --list --bootstrap-server localhost:9092发送和消费消息
./kafka-console-producer.sh --broker-list localhost:9092 --topic test执行后会进入客户端,在客户端中进行生产消息
消费消息
方式1:从最后一条信息的偏移量+1开始消费
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test方式2:从头开始消费,即便之前消费过的也可以继续消费
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic test注意
- 消息会被存储
- 消息是有顺序的
- 消息是有偏移量的
- 消费时可以指名偏移量进行消费
细节
生产者将消息发送给broker,broker会将消息保存在本地日志文件中
/usr/local/kafka/data/kafka-logs/主题-分区/00000000.log消息的保存是有序的,通过offset偏移量来描述消息的有序性
消费者消费时,也是根据offset来描述当前要消费的位置
单播消息
单播消息,一个消费组里 只会有一个消费者收到某个topic中的消息.于是可以创建多个消费者,这些消费者在同一个消费组中
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --consumer-property group.id=testGroup --topic test这条命令配置了消费组为testGroup,俩个客户端都执行这条命令就可以实现单播消息
如果多个消费者在同一个消费组,那么只有一个消费者可以收到订阅的topic中的消息.换言之,同一个消费组中只能有一个消费者能收到一个topic中的消息
多播消息
不同的消费组订阅同一个topic,那么不同的消费组中,只有一个消费者能收到消息.实际上也是多个消费组中的多个消费者收到了同一个消息

查看消费组信息
#查看当前主题下有哪些消费组
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
# 查看消费组中的具体信息:比如当前偏移量,最后一条消息偏移量,堆积的消息数量
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group testGroup- cuurent-offset:最后被消费的消息的偏移量
- log-end-offset:消息总量(最后一条消息的偏移量)
- lag 积压了多少消息
主题和分区
概念
主题topic在kafka中是一个逻辑概念,kafka通过topic将消息进行分类.不同的topic会被订阅该topic的消费者消费
但有一个问题如果说这个topic中的消息非常多,多到需要几t来村,因为消息是会保存到log日志文件中的.
为了解决文件过大的问题,kafka提出了partition的概念

一个主题中的消息量是非常大的,因此可以通过分区的设置来分布式存储这些消息
优势
- 分区存储,可以解决统一存储文件过大的问题
- 提供了读写的吞吐量
多分区主题
./kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 -partitions 2 --topic test1然后查看
./kafka-topics.sh --list --bootstrap-server localhost:9092定期将自己消费分区的offset提交给kafka内部topic:__consumer_offsets,提交过去的时候,key是consumerGroupid+topic+分区号,value就是当前offset的值,kafka会定期清理topic里的消息,最后保留最新的那条数据
因为__consumer_offset可能会接受高并发请求,kafka默认给其分配50个分区(可以通过offset.topic.num.partitions设置)这样可以通过加机器的方式抗大并发
通过如下公式可选出consumer消费者的offset要提交到的__consumer_offsets的哪个分区
公式:hash(consumerGroupId)%__consume_offset主题的分区数