序列化编解码与通信
简介
java序列化缺点
Java序列化从JDK 1.1版本就已经提供,它不需要添加额外的类库,只需实现java.io.Serializable并生成序列ID即可,因此,它从诞生之初就得到了广泛的应用。
但是在远程服务调用(RPC)时,很少直接使用Java序列化进行消息的编解码和传输,这又是什么原因呢?下面通过分析Java序列化的缺点来找出答案。
- 无法跨语言开发
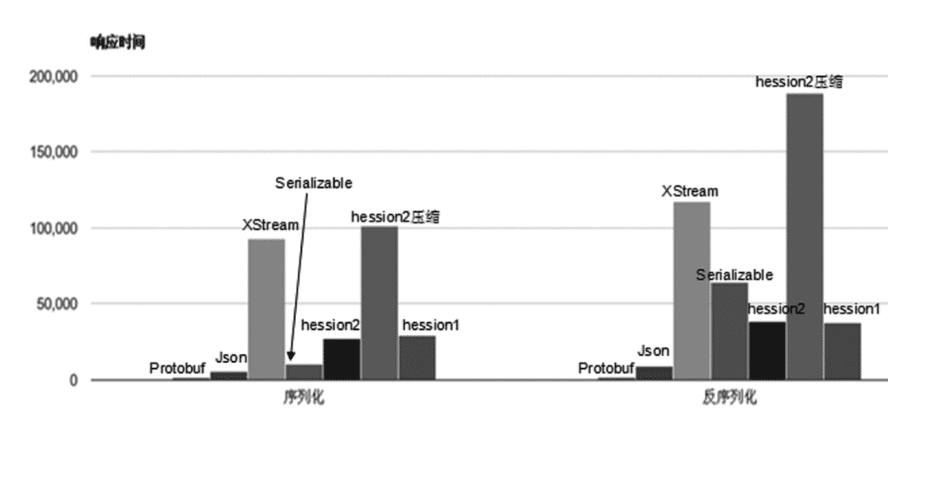
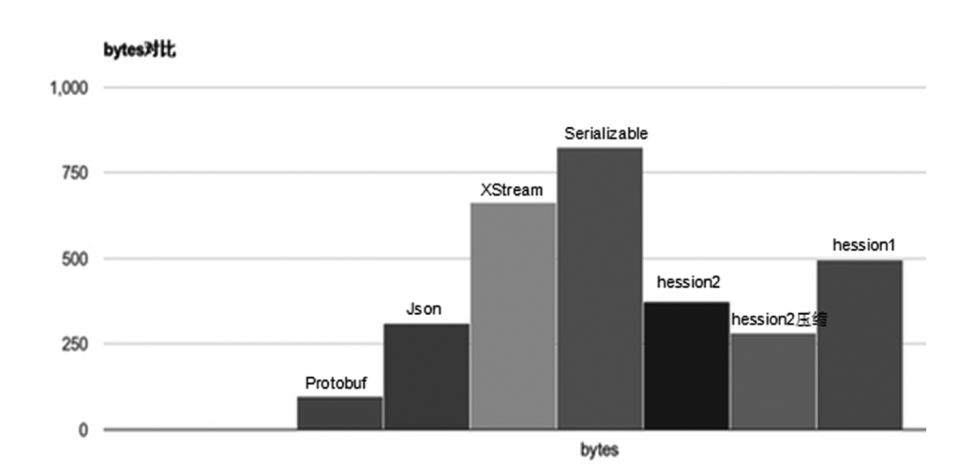
- 序列化后码流太大,采用JDK序列化机制编码后的二进制数组大小竟然是二进制编码的5.29倍
- 性能只能有二进制编码的6.17%左右
Protobuf
简介
Protobuf全程Google Protocal Buffers,它由谷歌开源而来。它将数据结构以proto文件进行描述,通过代码生成工具可以生成对应数据结构pojo对象
Plain Old Java Object 普通的java对象
首先我们来看下为什么不使用XML,尽管XML的可读性和可扩展性非常好,也非常适合描述数据结构,但是XML解析的时间开销和XML为了可读性而牺牲的空间开销都非常大,因此不适合做高性能的通信协议。Protobuf使用二进制编码,在空间和性能上具有更大的优势。
protobuf另一个比较吸引人的地方就是它的数据描述文件和代码生成机制,利用数据描述文件对数据结构进行说明的有点如下
grpc应该大家都没少听说,其使用的就是protobuf。
- 文本化的数据结构描述语言,可以实现语言和平台无关,特别适合异构系统间的集成;
- 通过标识字段的顺序,可以实现协议的前向兼容;
- 自动代码生成,不需要手工编写同样数据结构的C++和Java版本;
- 方便后续的管理和维护。相比于代码,结构化的文档更容易管理和维护。
- protocol没有null一说
通过编写一个.proto的数据结构定义文件,然后调用protobuf的编译器,就会生成对应的类,该类以高效的二进制格式实现protobuf数据的自动编码和解析。 生成的类为定义文件中的数据字段提供了getter和setter方法,并提供了读写的处理细节。 重要的是,protobuf可以向前兼容,也就是说老的二进制代码也可以使用最新的协议进行读取。
使用
定义消息格式
首先我们需要定义传输的消息格式。Protobuf使用.proto文件来定义消息格式,我们需要按照规定语法编写proto文件。
syntax = "proto3";
message Person {
string name = 1;
int32 age = 2;
repeated string hobbies = 3;
}生成java类
一旦我们定义好了消息格式,接下来需要根据.proto文件生成对应的java类。我们可以使用Protocal Buffers的编译器来完成这个任务
首先,安装Protocol Buffers编译器。在命令行中执行以下命令:
protoc --version如果能正确显示版本号,则表示编译器已安装。
然后,使用以下命令将.proto文件编译成Java类:
protoc --java_out=<output_directory> <input.proto>其中,<output_directory>为生成的Java类的输出目录,<input.proto>为.proto文件的路径。
对象序列化
生成了Java类之后,我们可以在代码中使用这些类来创建和操作消息对象。首先,我们需要创建消息对象,并设置相应的字段值。
示例代码:
// 创建Person对象
Person person = Person.newBuilder()
.setName("John")
.setAge(25)
.addHobbies("reading")
.addHobbies("swimming")
.build();
byte[] bytes = person.toByteArray();反序列化
// 将字节数组反序列化为Person对象
Person person = Person.parseFrom(byteArray);在上述示例中,我们使用Person类的parseFrom()方法将字节数组反序列化为Person对象。
至此,我们已经完成了Java使用Protobuf的基本操作。
Thrift
Thrift源于Facebook,在2007年Facebook将Thrift作为一个开源项目提交给了Apache基金会。对于当时的Facebook来说,创造Thrift是为了解决Facebook各系统间大数据量的传输通信以及系统之间语言环境不同需要跨平台的特性,因此Thrift可以支持多种程序语言,如C++、C#、Cocoa、Erlang、Haskell、Java、Ocami、Perl、PHP、Python、Ruby和Smalltalk。
在多种不同的语言之间通信,Thrift可以作为高性能的通信中间件使用,它支持数据(对象)序列化和多种类型的RPC服务。Thrift适用于静态的数据交换,需要先确定好它的数据结构,当数据结构发生变化时,必须重新编辑IDL文件,生成代码和编译,这一点跟其他IDL工具相比可以视为是Thrift的弱项。Thrift适用于搭建大型数据交换及存储的通用工具,对于大型系统中的内部数据传输,相对于JSON和XML在性能和传输大小上都有明显的优势。
Thrift主要由5部分组成。
(1)语言系统以及IDL编译器:负责由用户给定的IDL文件生成相应语言的接口代码;
(2)TProtocol:RPC的协议层,可以选择多种不同的对象序列化方式,如JSON和Binary;
(3)TTransport:RPC的传输层,同样可以选择不同的传输层实现,如socket、NIO、MemoryBuffer等;
(4)TProcessor:作为协议层和用户提供的服务实现之间的纽带,负责调用服务实现的接口;
(5)TServer:聚合TProtocol、TTransport和TProcessor等对象。
我们重点关注的是编解码框架,与之对应的就是TProtocol。由于Thrift的RPC服务调用和编解码框架绑定在一起,所以,通常我们使用Thrift的时候会采取RPC框架的方式。但是,它的TProtocol编解码框架还是可以以类库的方式独立使用的。
JBoss Marshalling
JBoss Marshalling是一个Java对象的序列化API包,修正了JDK自带的序列化包的很多问题,但又保持跟java.io.Serializable接口的兼容。同时,增加了一些可调的参数和附加的特性,并且这些参数和特性可通过工厂类进行配置。
相比于传统的Java序列化机制,它的优点如下。
◎ 可插拔的类解析器,提供更加便捷的类加载定制策略,通过一个接口即可实现定制;
◎ 可插拔的对象替换技术,不需要通过继承的方式;
◎ 可插拔的预定义类缓存表,可以减小序列化的字节数组长度,提升常用类型的对象序列化性能;
◎ 无须实现java.io.Serializable接口,即可实现Java序列化;
◎ 通过缓存技术提升对象的序列化性能。
相比于前面介绍的两种编解码框架,JBoss Marshalling更多是在JBoss内部使用,应用范围有限。
GRPC
现如今,微服务变得越来越流行,而服务之间的通信也扁的越来越重要,服务间通信本质是交换信息而交换信息的中介、桥梁正式PAI
RPC
在聊什么是gRPC前我们先来聊聊什么是RPC
RPC,全程Remote Procedure Call,中文译为远程过程调用。通俗地讲,使用RPC进行通信,调用远程函数就和调用本地函数一样,RPC底层会做好数据的序列化与传输,从而能使我们更轻松地创建分别是应用和服务。
而gRPC,则是RPC的一种,它是免费开源的,由谷歌出品。使用gRPC,我们只需要定义好每个API的Request和Response,剩下的gRPC这个框架会帮我们自动搞定。
另外,gRPC的典型特征就是使用protobuf(全程protocal buffers)作为接口定义语言(Interface Definition Language,缩写IDL),同时底层的消息交换格式也是使用protobuf。
基本通信流程
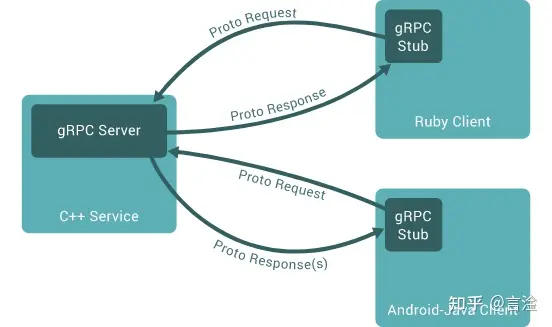
这是官方的一张图,通过这张图,我们可以大致了解下gRPC的通信流程
- gRPC通信的第一步是定义IODL,即我们的接口文档(后缀为.proto)
- 第二部是编译proto文件,得到存根(stub)文件,即上图深绿部分
- 第三部是服务端(gRPC Serverr)实现第一步定义的接口并启动,这些接口的定义在存根文件里面
- 最后一步是客户端借助存根调用服务端的函数,虽然客户端调用的函数是由服务端实现的,但是调用起来就像是本地函数一样。
以上就是gRPC的基本流程,从图中还可以看出,由于我们的proto文件的编译支持多种语言(Go、Java、Python等),所以gRPC也是跨语言的。
gRPC VS Restful
gRPC和Restful
文档规范
文档规范这种东西有点见仁见智,在我看来,gRPC使用proto文件编写接口(API),文档规范比Restful更好,因为proto文件的语法和形式是定死的,所以更为严谨、风格统一清晰;而Restful由于可以使用多种工具进行编写(只要人看得懂就行),每家公司、每个人的攥写风格又各有差异,难免让人觉得比较混乱。
另外,Restful文档的过时相信很多人深有体会,因为维护一份不会过时的文档需要很大的人力和精力,而公司往往都是业务为先;而gRPC文档即代码,接口的更改也会体现到代码中,这也是我比较喜欢gRPC的一个原因,因为不用花很多精力去维护文档。
消息编码
消息编码这块,gRPC使用protobuf进行消息编码,而Restful一般使用JSON进行编码
传输协议
传输协议这块,gRPC使用HTTP/2作为底层传输协议,据说也可替换为其他协议,但目前还未考证;而RestFul则使用HTTP。
传输性能
由于gRPC使用protobuf进行消息编码(即序列化),而经protobuf序列化后的消息体积很小(传输内容少,传输相对就快);再加上HTTP/2协议的加持(HTTP1.1的进一步优化),使得gRPC的传输性能要优于Restful。
传输形式
传输形式这块,gRPC最大的优势就是支持流式传输,传输形式具体可以分为四种(unary、client stream、server stream、bidirectional stream),这个后面我们会讲到;而Restful是不支持流式传输的。
浏览器支持
不知道是不是gRPC发展较晚的原因,目前浏览器对gRPC的支持度并不是很好,而对Restful的支持可谓是密不可分,这也是gRPC的一个劣势,如果后续浏览器对gRPC的支持度越来越高,不知道gRPC有没有干翻Restful的可能呢?
可读性与安全性
由于gRPC序列化的数据是二进制,且如果你不知道定义的Request和Response是什么,你几乎是没办法解密的,所以gRPC的安全性也非常高,但随着带来的就是可读性的降低,调试会比较麻烦;而Restful则相反(现在有HTTPS,安全性其实也很高)
gRPC的适用场景
从上面gRPC和Restful的比较中,我们其实也从侧面了解gRPC的优劣势,也能顺势推断出其应用场景。
总的来说,gRPC主要用于公司内部的服务调用,性能消耗低,传输效率高,服务治理方便。Restful主要用于对外,比如提供接口给前端调用,提供外部服务给其他人调用等,
GRPC流传输
HTTP2
流式传输不是一个新的概念。按照实现方式的不同可以分为实时流式传输和顺序流式传输俩者,前者通常指RTP、RTCP,典型的场景是直播,后者通常是由Nginx,Apache等提供支持的顺序下载
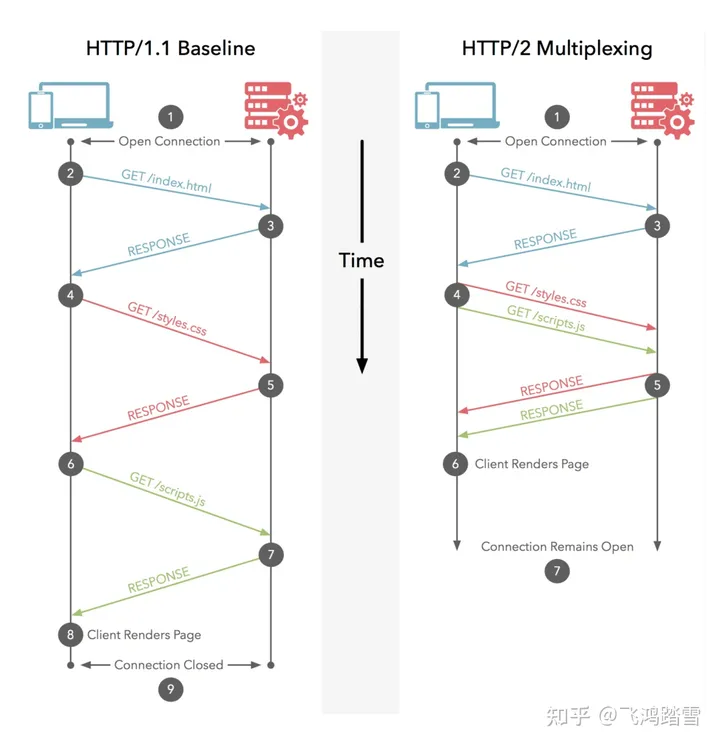
如果对HTTP/2有一定了解的话,就会知道它最为人知的特性是多路复用。在HTTP/1.1的时代,同一个时刻只能对一个请求进行处理或响应,换句话说,下一个请求必须要等当前请求处理完才能继续进行,与此同时,浏览器为了更快地加载页面资源,对同一个域名下的请求并发数进行了限制,所以,你会注意到一个有趣的现象,不分网站会使用多个CDN加速的域名,二者正式为了规避浏览器这一限制,HTTP/1.1时代,可以称为半双工模式。到了HTTP/2的时代,多路复用的特性让一次同时处理多个请求称为了现实,,并且一个TCP通道中的请求不分先后不会阻塞,是真正的全双工通讯。一个和文本更贴近的概念是流,HTTP/2中引入了流(Stream)和帧(Frame)的概念,当TCP通道建立后,后续的所有操作都是以流的方式发送的,而二进制帧则是组成流的最小单位,属于协议层上的流式传输
gRPC中的流式传输
对一个一个gRPC接口而言,他的起源是Protobuf定义。所以,一个最直观的人生是从Protobuf定义入手
// 普通 RPC
rpc SimplePing(PingRequest) returns (PingReply);
// 客户端流式 RPC
rpc ClientStreamPing(stream PingRequest) returns (PingReply);
// 服务器端流式 RPC
rpc ServerStreamPing(PingRequest) returns (stream PingReply);
// 双向流式 RPC
rpc BothStreamPing(stream PingRequest) returns (stream PingReply);可以注意到,相比普通的 RPC 方法(UnaryCall),采用流式传输的 gRPC 接口,主要是多了一个stream关键字。当该关键字修饰参数时,表示这是一个客户端流式的 gRPC 接口;当该参数修饰返回值时,表示这是一个服务器端流式的 gRPC 接口;当该关键字同时修饰参数和返回值时,表示这是一个双向流式的 gRPC 接口。作为类比,双向流式的 gRPC 接口,约等于 WebSocket,即客户端、服务器端都可以以流的形式收/发数据;服务器端流式的 gRPC 接口,约等于 Server-Sent Events,即服务器端以流的形式发数据。同理,客户端流式的 gRPC 接口,即客户端以流的的形式发数据。
我为什么会突然对这个话题产生兴趣呢?个人以为,主要有两个原因:其一,是工作中使用流式传输的机会不多,即使遇到数据量特别大的场合,大家想到的一定是修改 gRPC 数据传输的大小,而不是采用流式传输的做法;其二,是我注意到像 Istio、Envoy、Nacos 等项目,内部都是用 gRPC 作为通信协议,当你需要实现一个控制平面的时候,你会发现那里有大量的流式 gRPC 接口等着你去实现。
Dubbo和GRPC
区别
通讯协议:gRPC基于Http2.0,Dubbo基于定义TCP
序列化:gRPC使用protocol buffer,Dubbo使用hession2等基于java对象的序列化技术(它的序列化方式可以自己扩展,太多了我不列举)
服务注册与发现:gRPC是应用级别的服务注册,而Dubbo2.0及之前的版本都是基于更细力度的服务来进行注册,3.0之后转向应用级别的服务注册。
编程语言:gRPC可以使用任何语言(Http和Protocol buffer天然就是跨语言的),Dubbo只能使用在构建在JVM之上的语言。
服务治理:gRPC自身的治理能力很弱,只能基于Http连接维度进行容错,Dubbo可以基于服务维度进行治理
两者各有优缺点。gRPC的优势在于跨语言、跨平台,但服务治理能力弱。Dubbo服务治理能力强,但是受编程语言限制无法跨编程语言使用
跨语言调用
Duubo是比较流行的服务治理框架,以前Dubbo使用的是私有协议,采用hessian序列化,对于多语言生态来说嫉妒不友好。现在Dubbo发布了新版本V3,推出了基于gRPC的新协议Triple,完全兼容GRPC。
Triple
Triple协议是Duubo3推出的主力协议。Triple意为第三代,通过Dubbo1.0/Dubbo2.0俩代协议的演进,以及云原生带来的技术标准化浪潮,Dubbo3新协议Triple应运而生。
协议选择说明
协议是RPC的核心,它规范了数据在网络的传输内容和格式。除必须的请求,响应数据外,通常还会包含额控制数据,如单次请求的序列化方式,超时时间,压缩方式和鉴权信息等。
协议内容包含三部分
- 数据交换格式:定义RPC、
- 协议结构:定义包含字段列表和各字段语义及不同的字段排列方式
- 协议通过定义规则、格式和语义来约定数据如何在网络之间传输。一次成功的 RPC 需要通信的两端都能够按照协议约定进行网络字节流的读写和对象转换。如果两端对使用的协议不能达成一致,就会出现鸡同鸭讲,无法满足远程通信的需求。
RPC 协议的设计需要考虑以下内容:
- 通用性: 统一的二进制格式,跨语言、跨平台、多传输层协议支持
- 扩展性: 协议增加字段、升级、支持用户扩展和附加业务元数据
- 性能:As fast as it can be
- 穿透性:能够被各种终端设备识别和转发:网关、代理服务器等 通用性和高性能通常无法同时达到,需要协议设计者进行一定的取舍。
HTTP/1.1
比于直接构建于 TCP 传输层的私有 RPC 协议,构建于 HTTP 之上的远程调用解决方案会有更好的通用性,如WebServices 或 REST 架构,使用 HTTP + JSON 可以说是一个事实标准的解决方案。
选择构建在 HTTP 之上,有两个最大的优势:
- HTTP 的语义和可扩展性能很好的满足 RPC 调用需求。
- 通用性,HTTP 协议几乎被网络上的所有设备所支持,具有很好的协议穿透性。
但也存在比较明显的问题:
- 典型的 Request – Response 模型,一个链路上一次只能有一个等待的 Request 请求。会产生 HOL。
- Human Readable Headers,使用更通用、更易于人类阅读的头部传输格式,但性能相当差
- 无直接 Server Push 支持,需要使用 Polling Long-Polling 等变通模式
gRPC
上面提到了在 HTTP 及 TCP 协议之上构建 RPC 协议各自的优缺点,相比于 Dubbo 构建于 TCP 传输层之上,Google 选择将 gRPC 直接定义在 HTTP/2 协议之上。 gRPC 的优势由HTTP2 和 Protobuf 继承而来。
- 基于 HTTP2 的协议足够简单,用户学习成本低,天然有 server push/ 多路复用 / 流量控制能力
- 基于 Protobuf 的多语言跨平台二进制兼容能力,提供强大的统一跨语言能力
- 基于协议本身的生态比较丰富,k8s/etcd 等组件的天然支持协议,云原生的事实协议标准
但是也存在部分问题
- 对服务治理的支持比较基础,更偏向于基础的 RPC 功能,协议层缺少必要的统一定义,对于用户而言直接用起来并不容易。
- 强绑定 protobuf 的序列化方式,需要较高的学习成本和改造成本,对于现有的偏单语言的用户而言,迁移成本不可忽视
Triple
最终我们选择了兼容 gRPC ,以 HTTP2 作为传输层构建新的协议,也就是 Triple。
容器化应用程序和微服务的兴起促进了针对负载内容优化技术的发展。 客户端中使用的传统通信协议( RESTFUL或其他基于 HTTP 的自定义协议)难以满足应用在性能、可维护性、扩展性、安全性等方便的需求。一个跨语言、模块化的协议会逐渐成为新的应用开发协议标准。自从 2017 年 gRPC 协议成为 CNCF 的项目后,包括 k8s、etcd 等越来越多的基础设施和业务都开始使用 gRPC 的生态,作为云原生的微服务化框架, Dubbo 的新协议也完美兼容了 gRPC。并且,对于 gRPC 协议中一些不完善的部分, Triple 也将进行增强和补充。
那么,Triple 协议是否解决了上面我们提到的一系列问题呢?
- 性能上: Triple 协议采取了 metadata 和 payload 分离的策略,这样就可以避免中间设备,如网关进行 payload 的解析和反序列化,从而降低响应时间。
- 路由支持上,由于 metadata 支持用户添加自定义 header ,用户可以根据 header 更方便的划分集群或者进行路由,这样发布的时候切流灰度或容灾都有了更高的灵活性。
- 安全性上,支持双向TLS认证(mTLS)等加密传输能力。
- 易用性上,Triple 除了支持原生 gRPC 所推荐的 Protobuf 序列化外,使用通用的方式支持了 Hessian / JSON 等其他序列化,能让用户更方便的升级到 Triple 协议。对原有的 Dubbo 服务而言,修改或增加 Triple 协议 只需要在声明服务的代码块添加一行协议配置即可,改造成本几乎为 0。
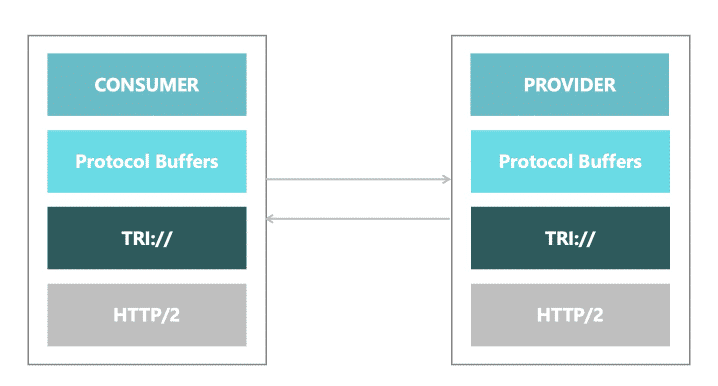
1、完整兼容grpc、客户端/服务端可以与原生grpc客户端打通
2、目前已经经过大规模生产实践验证,达到生产级别
- 特点与优势
1、具备跨语言互通的能力,传统的多语言多 SDK 模式和 Mesh 化跨语言模式都需要一种更通用易扩展的数据传输格式。
2、提供更完善的请求模型,除了 Request/Response 模型,还应该支持 Streaming 和 Bidirectional。
3、易扩展、穿透性高,包括但不限于 Tracing / Monitoring 等支持,也应该能被各层设备识别,网关设施等可以识别数据报文,对 Service Mesh 部署友好,降低用户理解难度。
4、多种序列化方式支持、平滑升级
5、支持 Java 用户无感知升级,不需要定义繁琐的 IDL 文件,仅需要简单的修改协议名便可以轻松升级到 Triple 协议