CopyOnWriteArrayList
简介
源码
- CopyOnWriteArrayList实现了Lsit接口,因此它是一个队列
- CopyOnWriteArrayList包含了成员lock.每一个CopyOnWriteArrayList,都和一个监视器锁Lock绑定,通过lock,实现了对CopyOnWriteArrayList的互斥访问
- CopyOnWriteArrayList底层也是数组
- 集成了三个接口,List,RandomAccess(支持快速随机访问),Cloneable(克隆),serializable(序列化反序列化接口)
final transient ReentrantLock lock = new ReentrantLock();
/** The array, accessed only via getArray/setArray. */
private transient volatile Object[] array;
/**
* Gets the array. Non-private so as to also be accessible
* from CopyOnWriteArraySet class.
*/
final Object[] getArray() {
return array;
}
/**
* Sets the array.
*/
final void setArray(Object[] a) {
array = a;
}
/**
* Creates an empty list.
*/
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}如源码所示,CopyOnWriteArrayList和ArrayList一样,都在内部维护了一个数组。操作CopyOnWriteArrayList其实就是在操作内部的数组。
但关键是和ArrayList的不同之处
private transient volatile Object[] array;看这行代码,使用volatile修饰了内部数组volatile关键字保证了每次拿到的内部数组都是最新值。因为volatile关键字表示直接去主存中获取值,因此哪怕别的线程刚修改完内部数组,也能保证获取内部数组时是最新的。
加锁
final transient ReentrantLock lock = new ReentrantLock();CopyOnWriteArrayList每创建一个实例,都会同时创建一个ReentrantLock锁。CopyOnWriteArrayList会在增,删,改操作时添加锁,而不会在读操作时加锁。
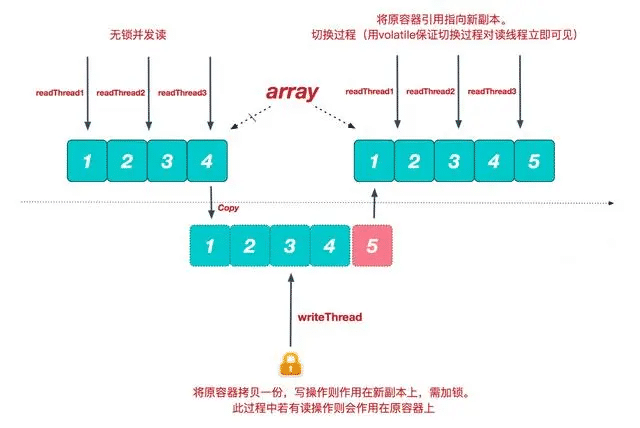
使用COW思想操作数组
COW是CopyOnWrite的缩写.在每次写入之前,先获取源数据的拷贝,修改完拷贝后,再保存到源数据中
get
private E get(Object[] a, int index) {
return (E) a[index];
}
public E get(int index) {
return get(getArray(), index);
}如源码所示,get操作没有加锁,直接返回数组中的对象。
set
public E set(int index, E element) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
E oldValue = get(elements, index);
if (oldValue != element) {
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len);
newElements[index] = element;
setArray(newElements);
} else {
// Not quite a no-op; ensures volatile write semantics
setArray(elements);
}
return oldValue;
} finally {
lock.unlock();
}
}- 加锁
- 获取源数组
- 判断新值和旧值是否相同
- 不同的话拷贝源数组,更新值,然后更新源数组
- 相同的话,不更新值,然后更新源数组(数组内容没变)
- 释放锁
add操作
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}- 加锁
- 获取源数组
- 复制一个源数组长度+1的新数组
- 在数组末尾赋值,然后更新源数组
- 释放锁
remove操作
public E remove(int index) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
E oldValue = get(elemnts, index);
int numMoved = len - index - 1;
if (numMoved == 0)
setArray(Arrays.copyOf(elements, len - 1));
else {
Object[] newElements = new Object[len - 1];
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index + 1, newElements, index,
numMoved);
setArray(newElements);
}
return oldValue;
} finally {
lock.unlock();
}
}大致流程:
- 加锁
- 获取源数组
- 判断删除的位置是不是数组末尾
- 是末尾的话,复制一个数组长度减一的数组,然后更新源数组
- 不是末尾的话,做成一个不包含需要删除的元素的新数组,然后更新源数组
- 释放锁
原因
以上操作可以看出,
查操作不加锁
增删改操作大致流程都是一样的,先加锁,然后复制一份源数组,操作完后写入源数组,释放锁。
那么为什么要这么做呢?都已经加锁了,为什么不能直接操作源数组呢?不然加锁是为了什么?
这是我第一次看到这种做法时的疑问。接下来一一解释。
- 读为什么不加锁
为了提升读的效率
- 加了锁为什么不能直接操作源数组
因为读操作没有加锁。增删改操作时,读操作可以在任何一步时获取数组里的值。
如果刚生成一个新数组,还没有更新里面的值的情况下就被执行了读操作,就会出现不可预料的情况。
因此为了保证数据的最终一致性。只有当数组完全更新结束后,再刷新源数组的值,才能保证读取的要么是旧值,要么是最新值。
- 使用COW就可以保证读操作不出现异常,为什么还需要加锁
加锁是为了保证和其他写操作不冲突。
- 优点:在保证线程安全的情况下,可以获得非常高的读操作
- 虽然写的性能低下,但能保证线程的安全
缺点
因为每次写操作都需要复制一份新数组,所以写操作性能低下,尤其是数组长度很长时,不建议使用CopyOnWriteArrayList。
玉宇澄清,多读取,少写入