HashMap面试题
HashMap的长度为什么是2的幂次方(1.8)
桶的计算方式
首先计算键值对的索引要满足俩个要求:不能越界,均匀分布
大家知道HashMap中,如果想存入数据,首先它需要根据key的 哈希值去定位落入那个桶中
而H % length(h根据key计算出来的哈希值)就能很好的满足这一点,但是取模运算较慢
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}先拿着key的哈希值,无符号右移16位 然后 ^ 异或上key的哈希值,得到一个值,再拿着这个值 & 上数组长度减一最后得出一个数,这个数就是得出的数脚标的位置,也就是存入桶的位置
由上面可以知道定位桶的最后需要做
原因
- HashMap的长度是2的次幂的话,可以让数据更散列更均匀的分布,更充分的利用数组的空间
假设数组长度是一个奇数,那参与最后的&运算的肯定就是偶数,那偶数的话,它的二进制的最后一位肯定永远是0,那说明一定是个偶数,
所以&完获取到的脚标永远是偶数位,那意味着奇数位的脚标永远都没值,有一半的空间是浪费的
- 这也是为什么hashmap每次扩容俩倍的原因
扩容后,元素新的位置,要么在角标原位,要么在原位+扩容长度的位置
hashMap1.8有什么改动
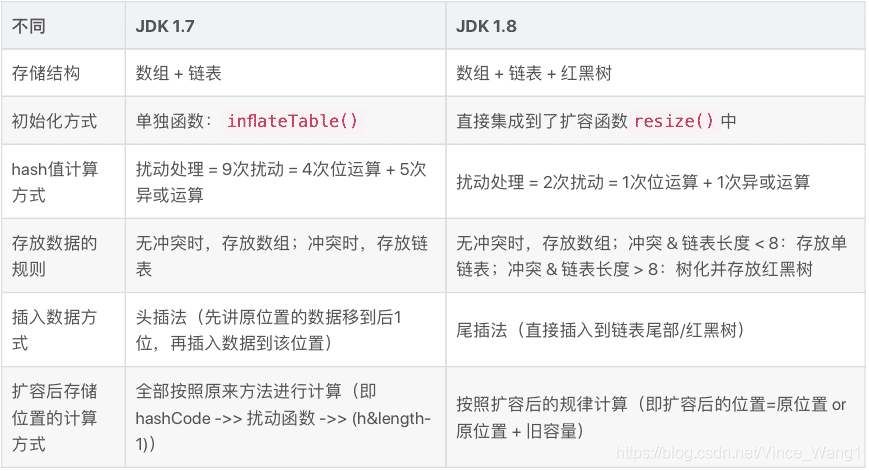
头插改尾插的原因
jdk1.7用的是头插法,1.8之后使用的是尾插法,那么为什么要这样做呢
比如现在是并发常见
- 线程启动T1,和T2都准备对Hashmap进行扩容操作,此时T1和T2指向的都是链表头节点的A,而T1和T2的下一个节点分别是T1.next,和T2.next,他们都指向节点B
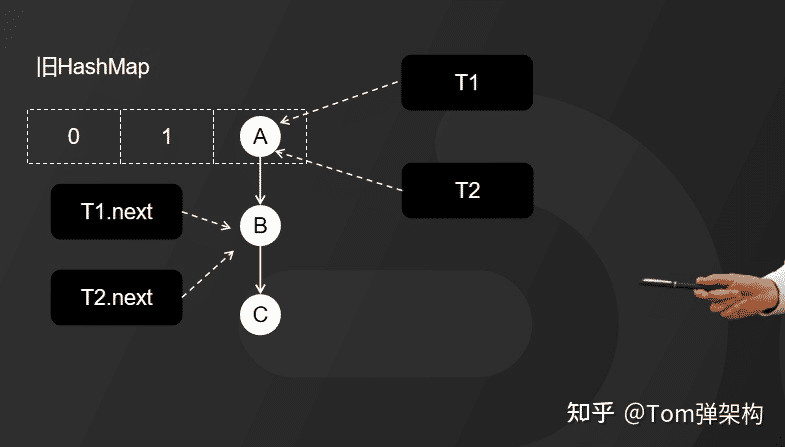
- 第二步:开始扩容,这时候,假设线程T2的时间片用完,进入了休眠状态,而线程T1开始执行扩容操作,一直到线程T1扩容完成后,线程T2才被唤醒。
- 因为HashMap扩容采用的是头插法,线程T1执行之后,链表中的节点顺序发生了改变。但线程T2对于发生的一切还是不可知的,所以它指向的节点引用依然没变。如图所示,T2指向的是A节点,T2.ne
- xt指向的是B节点。
- 因为T1执行完扩容之后,B节点的下一个节点是A,而T2线程指向的首节点是A,第二个节点是B,这个顺序刚好和T1扩容之前的节点顺序是相反的。T1执行完之后的顺序是B到A,而T2的顺序是A到B,这样A节点和B节点就形成了死循环。
因为T1执行完扩容之后,B节点的下一个节点是A,而T2线程指向的首节点是A,第二个节点是B,这个顺序刚好和T1扩容之前的节点顺序是相反的。T1执行完之后的顺序是B到A,而T2的顺序是A到B,这样A节点和B节点就形成了死循环。
java8的rehash改动
在jdk1.7的时候,是将数组扩容为俩倍,然后将hashmap中所有的key重新进行hash寻址算法然后放入到扩容后的数组的新位置
但是jdk1.8之后,对rehash进行了优化,减少了对key重新进行hash求址的寻址算法过程
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//这个 newCap = oldCap << 1 就是扩容两倍的证据
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
//重新构建了一个新的数组,容量是上面计算出来的newCap
//就是原来的两倍大小
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
//拿到老的数组,然后遍历每个数组的位置,对每个节点重新进行rehash
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
//当遍历到这个数组的位置有节点的时候,进入重新rehash
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
//这个的意思很简单,就是这个节点只有一个
//也就是没有形成链表或者红黑树的时候
//此时处理就是重新进行hash寻址算法,找到在新数组的位置放上
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
//就是这个已经是红黑树了,此时会进入红黑树rehash的过程
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
//这个就是链表的rehash的过程
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}其实rehash就是遍历数组的每个位置,判断节点的状态,是单个或者链表或者红黑树。接下来就每种情况进行讨论。
单个节点
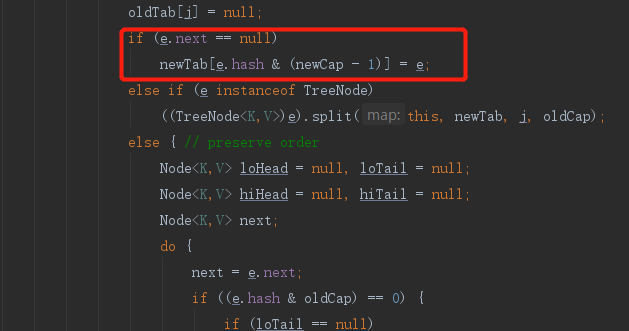
其实重新进行hash寻址算法,找到对应数组的下标,放上就行了
链表
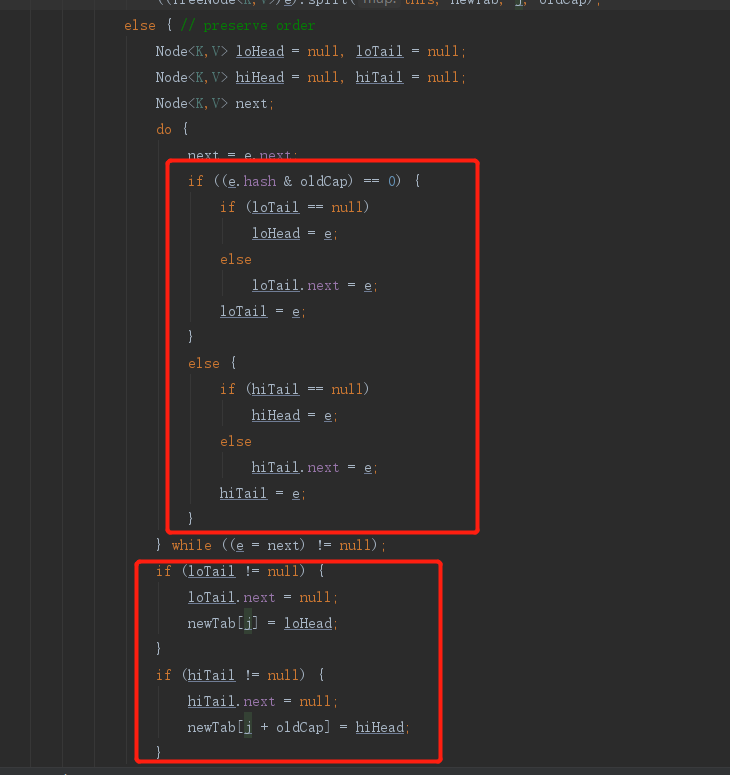
自习阅读源码后会发现,就是将之前的链表重新拆封为了俩个链表,一个链表rehash之后还是在当前位置的index,另一个链表rehash之后的位置变成了index+oldCap
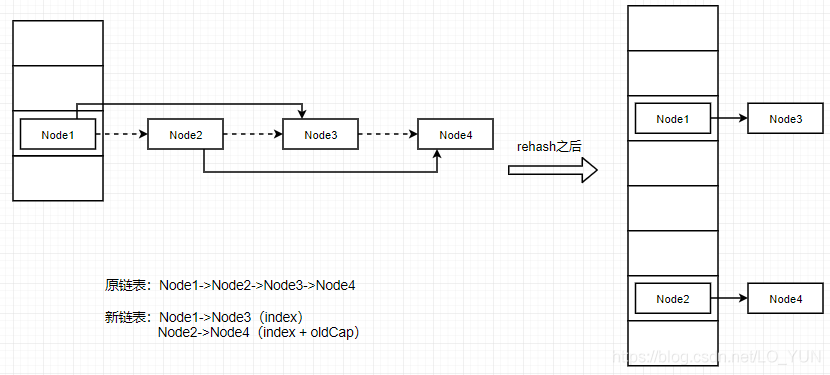
至于为什么可以分为两个链表,这里说明一下。就是hash寻址算法对一个数组下标的所有节点,扩容后进行重新计算的时候,会发现计算出来的位置要么是在原来的index,要么实在原来的index + oldCap的位置,这是hash寻址的一个特点,所以基于这一个既定的结论,就去判断一下每个节点重新hash寻址之后是原来的位置还是index + oldCap的位置就行了(如何判断,就是源码图的第一个红框框出来的),判断是在原来的位置然后一个新的链表,在index + oldCap的位置也形成一个新的链表,这样计算完之后只要把新的两个链表挂在新的数组的 index 和 index + oldCap就行了(如何挂的,就是源码图的第二个红框框出来的)。这样就避免了对每个节点重新进行hash寻址算法,重新放到hash表中的过程,大大提高了效率,这也就是JDK1.8的HashMap扩容rehash算法优化。
红黑树
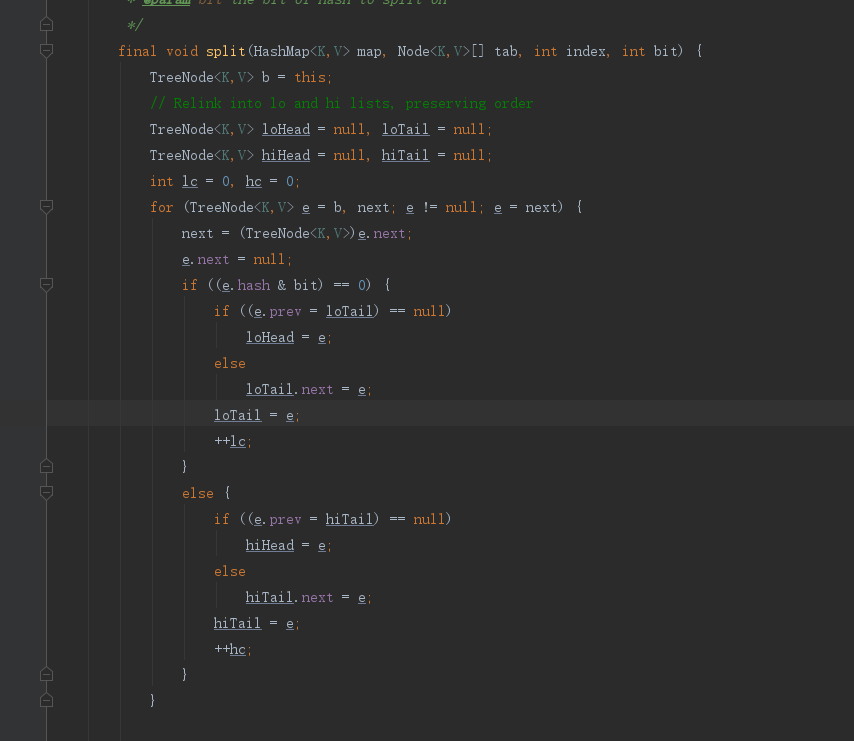
其实原理跟链表的差不多,就是链表拆成两个链表,红黑树这个拆成两个红黑树,分别挂到新的数组的位置上,只不过最后加个判断,就是判断这个红黑树是需要变成链表还是继续是红黑树。
所以在JDK1.8的rehash算法优化就是对原来的链表或者红黑树进行拆分成两部分,然后分别挂在原来数组的位置和 数组的位置 + oldCap的位置,这样做就避免了大量的节点进行重新hash寻址算法和重新放到hash表的过程,大大增加了扩容效率。