Mysql各种函数与注意
mysql常见函数
统计函数
- count()函数,对于除*以外的任何参数,返回所选集合中非null值的行的数目;对于参数
*是返回集合中所有的数目,包含null的行.没有where的count(*)是结果内部优化的,能快速地返回表中所有记录 - sum:求表中某个字段的总和
- avg函数:求表中某个值的平均值
- max函数求表中某个字段的最大值
- min函数求表中某个字段的最小值
数学函数
数学函数主要用于处理数字,包括整型和浮点数。下面介绍一下常用的几个数学函数。
ABS()函数
ABS()可以求出某字段值的绝对值。
FLOOR()函数
FLOOR()函数用于返回小于或等于参数x的最大整数。
RAND()函数
RAND()函数用于返回0~1之间的随机数。
TRUNCATE(x, y)函数
TRUNCATE(x, y)函数返回x保留到小数点后y位的值。
SQRT(x)函数
SQRT(x)函数用于求参数x的平方根。
下面看一下示例语句:
字符串函数
字符串函数主要用来处理数据表中的字符串。下面介绍一下常用的几个字符串函数。
UPPER(s)和UCASE(s)函数
UPPER(s)和UCASE(s)函数均可用于将字符串s中的所有哦字母变成大写字母。
LEFT(s, n)函数**
LEFT(s, n)函数返回字符串s的前n个字符。
SUBSTRING(s, n, len)函数
SUBSTRING(s, n, len)函数用于将字符串s的第n个位置开始获取长度len的字符串。
日期和时间函数
日期和时间函数是MySQL中最常用的函数之一,主要用于对表中的日期和时间数据进行处理。下面介绍一下几个常用的日期和时间函数。
CURDATE()和CURRENT_DATE()函数
CURDATE()和CURRENT_DATE()函数获取当前日期。
CURTIME()和CURRENT_TIME()函数
CURTIME()和CURRENT_TIME()函数获取当前时间。
NOW()函数
NOW()函数可以获取当前日期和时间,有同样功能的还有CURRENT_TIMESTAMP()、LOCALTIME() 、SYSDATE()和LOCALTIMESTAMP()。
mysql窗口函数
简介
在工种经常会有统计类的需求,对于复杂的统计,传统sql实现起来比较困难,这些需求有些共同点,需要在单表中满足某些条件的记录集内做一些函数操作.不适用窗口函数的话,可能要进行多次连表操作.不适用窗口函数的话,可能要进行多次连表操作,可读性差的同事,还会影响性能
窗口函数使用场景:对分组统计结果的每一条记录进行计算的场景下,使用窗口函数更好,注意是每一条,因为mysql的普通聚合函数的结果如group by是每组只有一条记录.
窗口函数
常用的聚合函数:
- count(col): 表示求指定列的总行数
- max(col): 表示求指定列的最大值
- min(col): 表示求指定列的最小值
- sum(col): 表示求指定列的和
- avg(col): 表示求指定列的平均值
窗口函数也称为OLAP(在线分析处理)函数,意思是对数据库数据进行实时分析处理,窗口函数就是为了实现OLAP而添加的标准SQL功能
窗口的概念非常重要可以理解为记录集合,窗口函数也就是在满足某种条件的记录集合上执行的特殊函数,对每条记录都要在此窗口内执行函数,有的函数,随着记录不同,窗口大小都是固定的,这属于静态窗口;有的函数则相反,不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口
窗口函数和聚合函数很容易混淆
- 聚合函数是将多条记录合为一条;而窗口函数是每条记录都会执行,查询结果并不会改变记录条数,有几条记录执行完还是几条
- 普通聚合函数也可以用于窗口函数中,赋予它窗口函数功能
原因就在于窗口函数的执行顺序(逻辑上的)是在FROM,JOIN,WHERE,GROUP BY,HAVING之后,在ORDER BY,LIMIT,SELECT DISTINCT之前。它执行时GROUP BY的聚合过程已经完成了,所以不会再产生数据聚合。
mysql8才开始支持窗口函数
使用
窗口函数有over关键字,指定函数执行的范围,可以分成是三个部分:分组子句,排序子句,窗口子句
<函数名> over (partition by <分组的列> order by <排序的列> rows between <起始行> and <终止行>)窗口的确定
分组子句 partition by
不分组可以写成partition by null或者直接不写
后面可以跟多个列
和group by的区别:前者不会压缩行数但是后者会,后者只能选取分组的列和聚合的列,也就是说group by生成的结果集与原表的行数和列数都不同
比如现在是这样的数据表
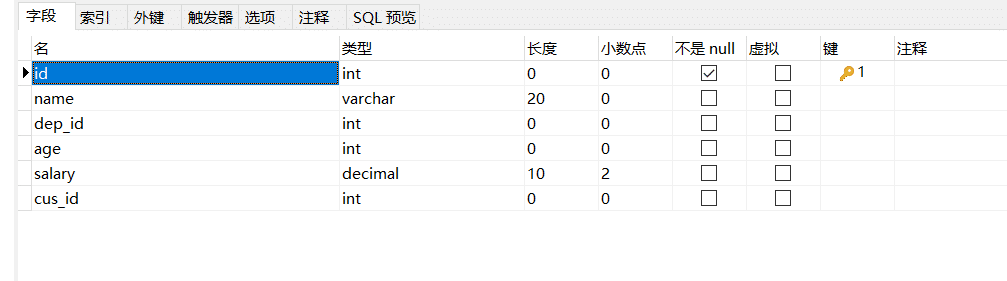
SELECT *,sum(age) over (partition by age) as '总年龄' from testemployeeid name dep_id age salary cus_id 总年龄
109 lhbOM 4 26 2002 4 24503443
110 NTcGX 10 28 2002 7 24503443
111 vneGU 7 23 2008 1 24503443
112 RdOIb 2 27 2002 9 24503443
113 GBNkN 2 25 2002 6 24503443
114 mwwTc 7 20 2005 3 24503443
115 RtuOM 4 26 2001 8 24503443
116 kSIMM 6 22 2008 6 24503443
117 knNYG 3 21 2000 9 24503443
118 nHwmT 7 26 2002 3 24503443
119 shHPe 1 28 2009 5 24503443
120 swehw 8 23 2005 9 24503443group by生成的结果集与原表的行数和列数都有不同
排序字句 order by
不排序可以写order by null或者不写
asc或不写表示升序,desc表示降序
后面可以跟多个列 例如order by age,cus_id
窗口子句rows
- 起始行 N preceding/unbounded preceding
- 当前行:current row
- 终止行:N following/unbounded following
如果不写的话默认就是between unbounded preceding and unbounded following
总体流程
通过partition by和 order by 子句确定大窗口(定义出上接unbounded preceding和下界unbounded following)
通过row子句对每一行数据确定小窗口(滑动窗口)
对每行的小窗口内的数据并升成新的列
函数分类
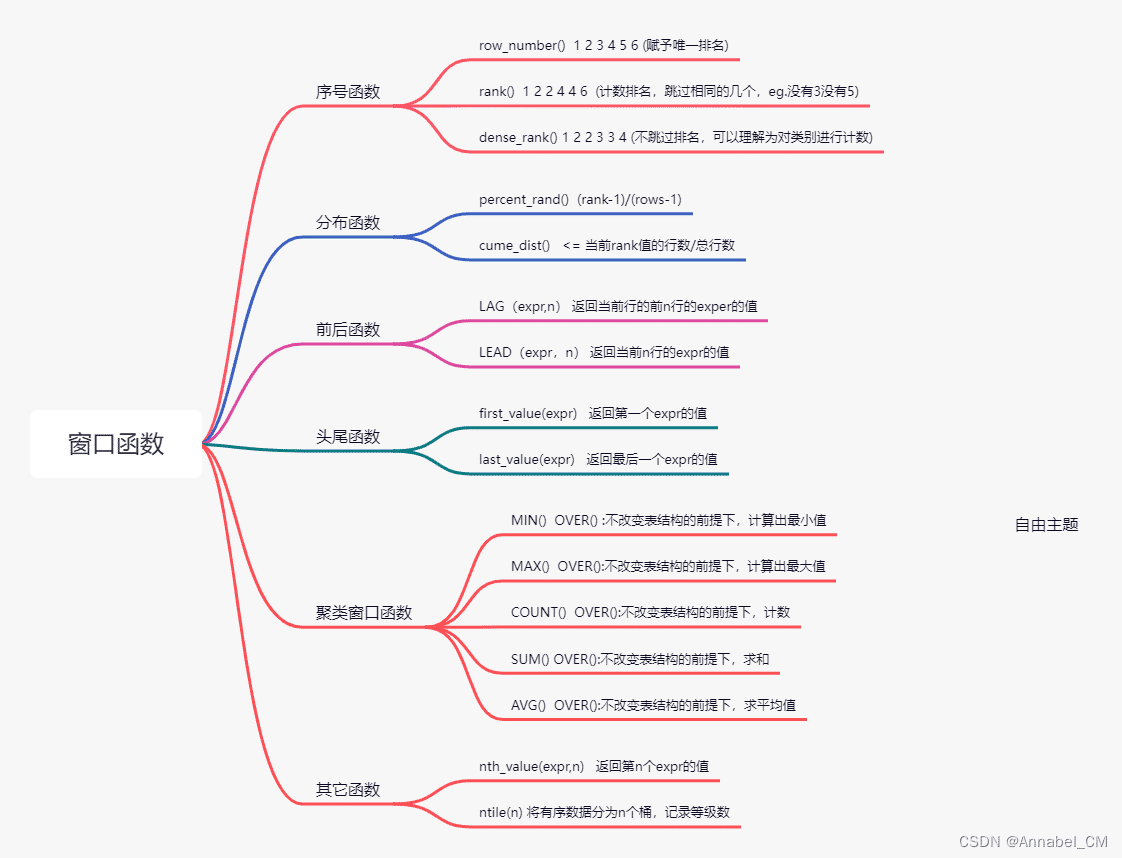
排序类(序号函数)
rank,dense_rank,row_number
SELECT *,rank() over (partition by age) as '排名' from testemployee- row_number():不考虑并列
- rank():考虑并列按年龄分组后作跳跃跑明
- dense_rank():按班级分组后作连续排名,考虑并列
聚合类
sum,avg,count,max,min
跨行类(前后函数)
lag,lead
参数1:比较的列,参数2:便宜量,参数3:找不到的默认值,可以只传俩个参数
比如想找同部门内,id比自己低一名的年龄是多少
lag是低,lead是高
SELECT *,lag(id,1) over (partition by dep_id order by id) as '小id' from testemployee分布函数
percent_rank()
用提:和之前的rank函数相关,每行按照如下公式计算:(rank-1)/(rows-1)
其中rank为rank函数产生的序号,row为当前窗口的记录总行数
cume_dist()
分组内大于等于当前rank值的分数/分组内总行数,这个函数比percent_rank用的多
头尾函数
first_value(expr)/last_value(expr)
得到分区中第一个/最后一个值
得到部门中第一个id
SELECT *,first_value(id) over (partition by dep_id order by id) as '小id' from testemployee其他函数
- nth_value(expr, n)
- 用途:返回窗口中第N个expr的值,expr可以是表达式,也可以是列名
- nfile()
用途:将分区中的有序数据分为n个桶,记录桶号。
此函数在数据分析中应用较多,比如由于数据量大,需要将数据平均分配到N个并行的进程分别计算,此时就可以用NFILE(N)对数据进行分组,由于记录数不一定被N整除,所以数据不一定完全平均,多出来的部分则依次加给第一组、第二组···直到分配完。