JUC详解
CAS和Unsafe
CAS
线程的安全实现包含
- 互斥同步:synchronized和ReentrantLock
- 非阻塞同步CAS,atomicXXXX
- 无同步方案:栈封闭,ThreadLocal,可重入代码
什么是cas
cas全称为Compare-and-swap,直译就是比较并交换。就是一条CPU的原子指令,起作用是让CPU进行比较俩个值是否相等,然后原子地更新某个位置的值。
其实现方式基于硬件平台的汇编指令,就算是CAS是靠硬件实现的,JVM只是封装了汇编调用,哪些Atomiclnteger类便是使用了这些封装后的接口.
CAS操作需要输入俩个值,一个旧值,(期望操作的值)和一个新值,在操作期间先比较下旧值有没有发生变化,如果没有发生变化,才交换新值,发生了变化则不交换
CAS操作是原子性的,所以多线程并发使用CAS更新数据的时,可以不用锁.JDK大量使用了CAS来更新数据防止加锁来保持原子更新
synchronized加锁
public class Test {
private int i=0;
public synchronized int add(){
return i++;
}
}java中为我们提供了AtomicInteger 原子类(底层基于CAS进行更新数据的),不需要加锁就在多线程并发场景下实现数据的一致性。
public class Test {
private AtomicInteger i = new AtomicInteger(0);
public int add(){
return i.addAndGet(1);
}
}ABA问题
要问CAS需要在操作值的时候,检查有没有发生变化,比如没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生改变,但实际上是变化了
ABA的问题解决思路就是使用版本号.在变量前面追加上版本号,每次变量更新的时候把版本号+1
从java1.5开始,JDK的Atomic包里提供了一个AtomiscStampedReference来解决ABA问题.这个了compareAndSet放啊作用就是首先检查当前引用是否等于预期引用,并且检查当前标志是否等于语气标志,如果全部相等,则以原子方式将该引用和标志的值设置为设定给的新值。
循环时间开销大
自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。如果JVM支持处理器提供的pause指令,那么效率有一定提升。
pause指令有俩个作用:第一,可以延迟流水执行命令de-pipeline 使cpu不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,字啊一些处理器上延时是0,第二它可以避免在推出循环的时候因内存顺序冲突(Memory Order Violation)而引起CPU流水线被清空(CPU Pipeline Flush),从而提高CPU的执行效率
只能保证一个共享变量的原子操作
当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子啊哦做,但是对多个变量共享操作时,循环CAS就无法保证操作的原子性,这时候可以用锁.
从1.5开始,jdk提供了AtomicReference类来保证引用对象之间的原子性,就可以把多个变量放在一个对象里来进行CAS操作
unsafe类
unsafe是位于sum.sisc包下的一个类,主要提供一些执行低级别,不安全操作的方法,如直接访问系统内存资源,自主管理内存资源等,这些方法在提升java运行效率,增强java语言底层资源操作能力方面起到了很大作用。但由于Unsafe类使java语言拥有我类似c语言一样操作内存空间的能力,这无疑也增加了程序发生相关指针问题的风险。在程序中过渡不正确的使用Unsafe类会使得程序出错概率变大,使得java这种安全的语言变得不再安全,因此对unsafe的使用一定要慎重
这个类尽管里面的方法都是public的,但是并没有办法使用它们,JDK API文档也没提供任何关于这个类的方法解释.总而言之对unsafe类的使用都是受限的,只有受新人的代码才能获得该类的实例,当然JDK库里面的类是可以随意使用的.
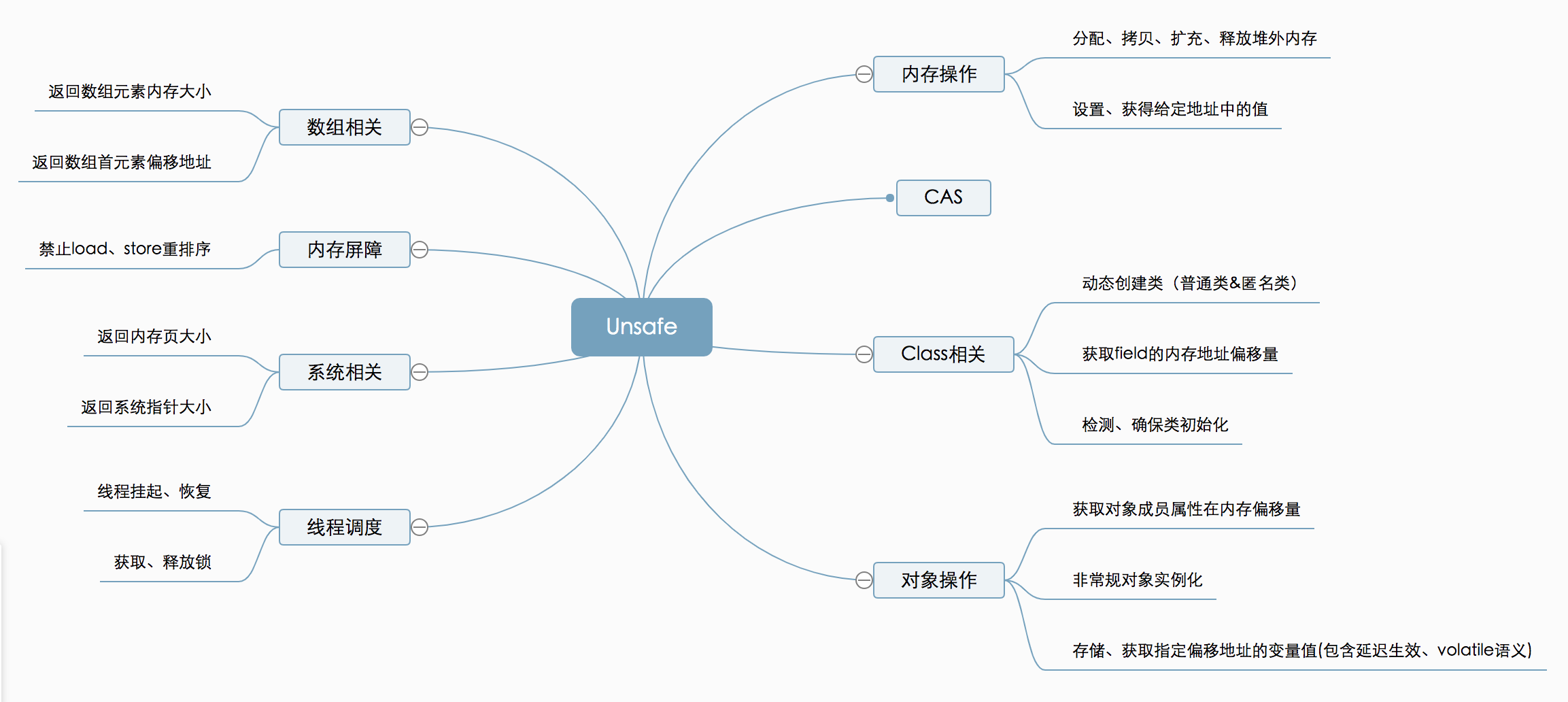
著作权归https://pdai.tech所有。 链接:https://www.pdai.tech/md/java/thread/java-thread-x-juc-AtomicInteger.html
如上图所示,Unsafe提供的API大致可分为内存操作、CAS、Class相关、对象操作、线程调度、系统信息获取、内存屏障、数组操作等几类,下面将对其相关方法和应用场景进行详细介绍。
Unsafe与CAS
反编译出来的代码:
public final int getAndAddInt(Object paramObject, long paramLong, int paramInt)
{
int i;
do
i = getIntVolatile(paramObject, paramLong);
while (!compareAndSwapInt(paramObject, paramLong, i, i + paramInt));
return i;
}
public final long getAndAddLong(Object paramObject, long paramLong1, long paramLong2)
{
long l;
do
l = getLongVolatile(paramObject, paramLong1);
while (!compareAndSwapLong(paramObject, paramLong1, l, l + paramLong2));
return l;
}
public final int getAndSetInt(Object paramObject, long paramLong, int paramInt)
{
int i;
do
i = getIntVolatile(paramObject, paramLong);
while (!compareAndSwapInt(paramObject, paramLong, i, paramInt));
return i;
}
public final long getAndSetLong(Object paramObject, long paramLong1, long paramLong2)
{
long l;
do
l = getLongVolatile(paramObject, paramLong1);
while (!compareAndSwapLong(paramObject, paramLong1, l, paramLong2));
return l;
}
public final Object getAndSetObject(Object paramObject1, long paramLong, Object paramObject2)
{
Object localObject;
do
localObject = getObjectVolatile(paramObject1, paramLong);
while (!compareAndSwapObject(paramObject1, paramLong, localObject, paramObject2));
return localObject;
}从源码中发现,内部使用自旋的方式进行CAS更新(while循环进行CAS更新,如果更新失败,则循环再次重试)。
又从Unsafe类中发现,原子操作其实只支持下面三个方法。
public final native boolean compareAndSwapObject(Object paramObject1, long paramLong, Object paramObject2, Object paramObject3);
public final native boolean compareAndSwapInt(Object paramObject, long paramLong, int paramInt1, int paramInt2);
public final native boolean compareAndSwapLong(Object paramObject, long paramLong1, long paramLong2, long paramLong3);unsafe其他功能
unsafe提供了硬件级别的操作,比如获取某个属性在内存中的位置,比如说修改对象字段值,即使它是私有的.不过 java的本身就是为了屏蔽底层的差异,对于一般的开发而言也很少会有这样的需求
举个例子,比如说
public native long staticFieldOffset(Field paramField);这个方法可以用来获取给点的paramfield的内存地址偏移量,这个值对于给定的field是唯一的且固定不变的
public native int arrayBaseOffset(Class paramClass);
public native int arrayIndexScale(Class paramClass);第一个是用来获取数组第一个元素的便宜地址,最后一个是用来获取数组的转换因子即数组中元素的增量地址的
public native long allocateMemory(long paramLong);
public native long reallocateMemory(long paramLong1, long paramLong2);
public native void freeMemory(long paramLong);分别用来分配内存,扩充内存和释放内存的
AtomicInteger
一AtomicInteger为例
public final int get(); //获取当前值
public final int getAndSet(int newValue)//获取当前的值,并设置新的值
public final int getAndIncrement();//获取当前的值,并自增
public final int getAndDecrement();//获取当前的只并自减
public final int getAndAdd(int delta);
void lazySet(int newValue);最终会设置成newVlaue,使用lazySet设置值后,可能导致其他线程在之后的一小段时间内可以读到旧的值相比 Integer 的优势,多线程中让变量自增:
private volatile int count = 0;
// 若要线程安全执行执行 count++,需要加锁
public synchronized void increment() {
count++;
}
public int getCount() {
return count;
}使用 AtomicInteger 后:
private AtomicInteger count = new AtomicInteger();
public void increment() {
count.incrementAndGet();
}
// 使用 AtomicInteger 后,不需要加锁,也可以实现线程安全
public int getCount() {
return count.get();
}源码解析
public class AtomicInteger extends Number implements java.io.Serializable {
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
//用于获取value字段相对当前对象的“起始地址”的偏移量
valueOffset = unsafe.objectFieldOffset(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
private volatile int value;
//返回当前值
public final int get() {
return value;
}
//递增加detla
public final int getAndAdd(int delta) {
//三个参数,1、当前的实例 2、value实例变量的偏移量 3、当前value要加上的数(value+delta)。
return unsafe.getAndAddInt(this, valueOffset, delta);
}
//递增加1
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
...
}我们可以看到 AtomicInteger 底层用的是volatile的变量和CAS来进行更改数据的。
- volatile保证线程的可见性,多线程并发时,一个线程修改数据,可以保证其它线程立马看到修改后的值
- CAS 保证数据更新的原子性
延伸到的元子类:13个
更新基本类型
使用原子的方式更新基本类型,atomoc包提供了以下三个类
- AtomicBoolean:原子更新布尔类型
- AtomicInteger:原子更新整型
- AtomicLong:原子更新长整型
以上三个类提供的方法几乎一模一样,可以参考上面AtomocInteger中相关的方法
原子更新数组
通过原子的方式更新数组里的某个元素,Atomic包里提供了以下四个类
- AtomicIntegerArray:原子更新整形数组里的元素
- AtomicLongArray:原子更新长整形数组里的元素
- AtomicBoleanArray:原子更新布尔数组里的元素
- AtomicReferenceArray:原子更新引用类型数组里的元素.
原子更新引用类型
Atomic包提供了以下三个类
- AtomicReference:原子更新引用类型
- AtomicStampedReference:原子更新引用类型,内部使用Pair来存储元素值及其版本号
- AtomicMarkableReference:原子更新带有标记的引用类型
这三个类提供的方法都差不多,首先构造一个引用对象,然后把引用对象set进Atomic类,然后compareAndSet等一些方法啊去进行原子操作,原理都是基于Unsafe实现但AtomicReferenceFieldUpdater略有不同,更新的字段必须用volitile修饰
举个 AtomicReference例子
import java.util.concurrent.atomic.AtomicReference;
public class AtomicReferenceTest {
public static void main(String[] args){
// 创建两个Person对象,它们的id分别是101和102。
Person p1 = new Person(101);
Person p2 = new Person(102);
// 新建AtomicReference对象,初始化它的值为p1对象
AtomicReference ar = new AtomicReference(p1);
// 通过CAS设置ar。如果ar的值为p1的话,则将其设置为p2。
ar.compareAndSet(p1, p2);
Person p3 = (Person)ar.get();
System.out.println("p3 is "+p3);
System.out.println("p3.equals(p1)="+p3.equals(p1));
}
}
class Person {
volatile long id;
public Person(long id) {
this.id = id;
}
public String toString() {
return "id:"+id;
}
}输出
p3 is id:102
p3.equals(p1)=false说明
著作权归https://pdai.tech所有。 链接:https://www.pdai.tech/md/java/thread/java-thread-x-juc-AtomicInteger.html
- 新建AtomicReference对象ar时,将它初始化为p1。
- 紧接着,通过CAS函数对它进行设置。如果ar的值为p1的话,则将其设置为p2。
- 最后,获取ar对应的对象,并打印结果。p3.equals(p1)的结果为false,这是因为Person并没有覆盖equals()方法,而是采用继承自Object.java的equals()方法;而Object.java中的equals()实际上是调用"=="去比较两个对象,即比较两个对象的地址是否相等。
原子更新字段类
Atomic包提供了四个类进行原子字段更新
- AtomicIntegerFieldUpdater:原子更新整形的字段的更新器
- AtomicLongFieldUpdater:原子类更新长整形字段的更新器
- AtomicReferenceFieldUpdater:原子类的引用类型更新器
- AtomicStampedFieldUpdater:原子类带有版本好的引用类型更新器
这四个类的使用方式都差不多,是基于反射的原子更新字段的值.要想原子地更新字段类需要俩步
- 因为原子更新字段类都是抽象类每次更新的时候必须使用静态方法newUpdater创建一个更新器,并且需要设置想要更新的类和属性
- 更新类的字段必须使用public,volatile修饰
对AtomicIntegerFieldUpdater的使用稍微有一些限制和约束,如下
- 字段必须是volatile类型的,在线程之间共享变量时保证立即可见
- 字段的描述类型(修饰符public/protected/default/private)是与调用者与操作对象字段的关系一致.也就是说调用者能够直接操作对象字段,那么就可以进行反射的原子操作.但是对于父类字段,子类是不能直接操作的,尽管子类可以访问父类的字段
- 只能是实例变量,不能是类变量,也就是说不能加static关键字
- 只能是可修饰变量,不能是final变量,义务final的语义就是不可修改,实际上final和volivate是有冲突的,俩个关键字不能同时存在
- 对于AtomicIntegerFieldUpdater和AtomicLongFieldUpdater只能修改int/long类型字段,不能修改包装类型的字段.如果包装类型就需要使用AtomicReferenceFieldUpdater
AtomicStampedReference解决CAS的ABA问题
AtomicStampedReference主要维护包含一个对象引用以及一个可以自动更新的整数stamp
public class AtomicStampedReference<V> {
private static class Pair<T> {
final T reference; //维护对象引用
final int stamp; //用于标志版本
private Pair(T reference, int stamp) {
this.reference = reference;
this.stamp = stamp;
}
static <T> Pair<T> of(T reference, int stamp) {
return new Pair<T>(reference, stamp);
}
}
private volatile Pair<V> pair;
....
/**
* expectedReference :更新之前的原始值
* newReference : 将要更新的新值
* expectedStamp : 期待更新的标志版本
* newStamp : 将要更新的标志版本
*/
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
// 获取当前的(元素值,版本号)对
Pair<V> current = pair;
return
// 引用没变
expectedReference == current.reference &&
// 版本号没变
expectedStamp == current.stamp &&
// 新引用等于旧引用
((newReference == current.reference &&
// 新版本号等于旧版本号
newStamp == current.stamp) ||
// 构造新的Pair对象并CAS更新
casPair(current, Pair.of(newReference, newStamp)));
}
private boolean casPair(Pair<V> cmp, Pair<V> val) {
// 调用Unsafe的compareAndSwapObject()方法CAS更新pair的引用为新引用
return UNSAFE.compareAndSwapObject(this, pairOffset, cmp, val);
}- 如果元素和版本号都没有变化,并且和新的也相同,返回true;
- 如果元素值和版本号都没有变化,并和新的完全不相同,就构造一个新的pair对象并执行CAS更新pair
- 首先,使用版本号控制;
- 其次,不重复使用节点(Pair)的引用,每次都新建一个新的Pair来作为CAS比较的对象,而不是复用旧的;
- 最后,外部传入元素值及版本号,而不是节点(Pair)的引用
还有哪些类可以解决ABA问题
AtomicMarkableReference,它不是维护一个版本号,而是维护一个boolean类型的标记,标记值有修改,了解一下。
LockSupport详解
LockSupport用来创建锁和其他同步类的基本线程阻塞额原语.简而言之,当调用LockSupport.park时,表示当前线程将会等待,直到获得许可,当调用LockSupport.unpark时,必须把等待获得许可的线程作为参数进行传递,好让次线程继续运行
LockSpport源码分析
类的构造函数
// 私有构造函数,无法被实例化
private LockSupport() {}核心函数分析
在分析LockSupport函数之前,先引入sum.misc.Unsafe类中的park和unpark函数,因为LcokSupport的核心函数都是基于Unsafe类中定义的park和unpark函数
public native void park(booelan isAbsolute,long time);
public native void unpark(Thread thread);park函数,阻塞线程,并且该线程在下列情况之前都会被阻塞
- 调用unpark函数,释放该线程的许可
- 该线程被中断
- 设置的时间到了.并且当time为绝对时间时,isAbsolute为true,否则isAboslute为false.当time为0时,表示无限等待,直到unpark发生
- unpark函数,释放线程的许可,即激活调用park后阻塞的线程,这个函数是不安全的,调用这个 函数需要确保线程依旧存活
pakr函数
park函数有俩个重载版
public static void park();
public static void park(Object blocker);俩个函数的区别在于blocker,即设置线程的parkBlocker字段,park(Object)型函数如下
public static void park(Object blocker) {
// 获取当前线程
Thread t = Thread.currentThread();
// 设置Blocker
setBlocker(t, blocker);
// 获取许可
UNSAFE.park(false, 0L);
// 重新可运行后再此设置Blocker
setBlocker(t, null);
}说明:调用park函数时,首先获取当前线程,然后设置当前线程的parkBlocker字段,即调用setBlock函数,之后调用Unsafe类的park函数,只调用setBlocker函数.那么问题来了,为什么要中再此park函数中调用俩次setBlocker函数嗯?原因很简单,调用park函数时,当现场首先设置好parkBlocker字段,然后调用Unsafe的park函数,伺候,当前线程就已经阻塞了,等待改下次你哼的unpakr函数被调用,该线程获取许可后,就可以继续运行了,也就运行第二个setBlocker,把该线程的parkBlocker字段设置为null,就这样完成了整个park函数的逻辑.如果没有第二个setBlocker,那么只会没有调用park(Object blocker),而直接调用getBlockr函数得到的还是前一个park(Object blocker)设置的blocker,显然是不符合逻辑的.宗旨必须要保证在park(Object blocker)震撼函数执行完之后,该线程的parkBlocker字段又恢复为null.所以park(Object)要调用setBlocker函数俩次.setBlocker方法如下
private static void setBlocker(Thread t, Object arg) {
// 设置线程t的parkBlocker字段的值为arg
UNSAFE.putObject(t, parkBlockerOffset, arg);
}说明: 此方法用于设置线程t的parkBlocker字段的值为arg。
另外一个无参重载版本,park()函数如下。
public static void park() {
// 获取许可,设置时间为无限长,直到可以获取许可
UNSAFE.park(false, 0L);
}说明:调用了park函数后,会禁用当前线程,除非许可可用,在以下三种情况之一发生之前,当前线程都将处于休眠状态,即下列情况发生 时,当前线程会忽的许可,可以继续运行.
- 其他某个线程将当前线程作为目标调用unpark
- 其他某个线程中断当前线程
- 该调用不合逻辑地(即毫无理由地)返回
parkNanos函数
此函数表示在许可可用钱禁用当前线程,并最多等待指定的时间,
public static void parkNanos(Object blocker, long nanos) {
if (nanos > 0) { // 时间大于0
// 获取当前线程
Thread t = Thread.currentThread();
// 设置Blocker
setBlocker(t, blocker);
// 获取许可,并设置了时间
UNSAFE.park(false, nanos);
// 设置许可
setBlocker(t, null);
}
}该函数也是调用了俩次setBlocker函数,nanos参数表示相对时间,表示等待多长时间
pakrUntil
此函数表示在指定的时限禁用当前线程除非许可可用
public static void parkUntil(Object blocker, long deadline) {
// 获取当前线程
Thread t = Thread.currentThread();
// 设置Blocker
setBlocker(t, blocker);
UNSAFE.park(true, deadline);
// 设置Blocker为null
setBlocker(t, null);
}该函数也调用了俩次setBlocker函数
unPark函数
此函数表示如果给定线程的许可尚不可用,则使其可用.如果线程在park上受阻,则它讲解除其闭塞状态.否则保证,下一次调用aprk不会受阻塞.如果给定线程尚未启动,则无法保证此操作有任何效果
public static void unpark(Thread thread) {
if (thread != null) // 线程为不空
UNSAFE.unpark(thread); // 释放该线程许可
}释放许可,指定线程可以继续运行
AQS详解
AQS是一个用来构建锁和同步器的框架,使用AQS能简单切高效地构造出应用广泛的大量的同步器 ,.比如ReentrantLock,Semaphore,其他诸如ReentrantReadWriteLock,SynchronousQueue,FutureTask等等皆是基于AQS的.当然我们也能利用AQS非常轻松地构造出符合我们自己需求的同步器.
AQS简介
AQS核心思想
AQS核心思想是,如果请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并将共享资源设置为锁定状态.如果请求的共享资源被占用,那么就需要一套线程阻塞以及北环线时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程假如到队列中.
CLH(Craig,Landin,And Hagersten)队列是一个虚拟机的双向队列(虚拟机的双向队列即不存在队列实例,仅存在节点之间的关联关系).AQS是将每条请求共享资源的线程封装成一个CLH锁队列的一个节点(Node)来实现锁的分配
AQS使用一个int成员变量来表示同步状态,通过内置的FIFO队列来完成获取资源线程的排队工作。QAS使用CAS对该同步状态进行原子操作实现对其值的修改.
private volatile int state;//共享变量,使用volatile修饰保证线程可见性状态通过procted类型的getState,setState,compareAndSetAndSetState进行操作
//返回同步状态的当前值
protected final int getState() {
return state;
}
// 设置同步状态的值
protected final void setState(int newState) {
state = newState;
}
//原子地(CAS操作)将同步状态值设置为给定值update如果当前同步状态的值等于expect(期望值)
protected final boolean compareAndSetState(int expect, int update) {
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}AQS对资源共享的方式
AQS定义俩种资源共享方式
Exclusive(独占)只有一个线程能执行,如ReentrantLock.又可分为公平锁和非公平锁
- 公平锁:按照线程在队列中的排队顺序,先到者先拿到锁
- 非公平锁:当多个线程要获取到锁时,舞狮队列顺序直接抢锁,谁抢到就是谁的
- Share(共享)多个现场可同时执行,Semaphore/CountDownLatch。Semaphore、CountDownLatCh、 CyclicBarrier、ReadWriteLock
ReentrantWriteLock可以看成是组合式,因为ReentrantReadWriteLock也就是读写锁允许多个线程对某一个资源进行读
不同的自定义同步器争用共享资源的方式也不同。自定义同步器实现是只需要实现共享资源state的获取与释放即可,至于线程等待队列的维护(如获取资源失败入队、唤醒出队等)AQS已经在上层帮我们实现好了
AQS底层使用了模板方法模式
同步器的设计是基于模板方法模式的,如果需要自定义同步器一般的方式是这样的(模板方法模式很经典的一个应用)
使用者继承ABstractQueuedSynchronizer并重写指定的方法.(这些重写方法很简单,无非是对于共享资源state的获取和释放)将AQS组合在自定义同步组件的视线中,并调用其模板方法,而这些模板方法会调用使用者重写的方法.
isHeldExclusively()//该线程是否正在独占资源.只有用到condition才需要实现它
tryAcquire(int)//独占方式.尝试获取资源,成功返回true,失败返回false
tryRelease(int)//独占方式,尝试释放资源,成功返回true,失败返回false
tryAcquieShared(int)//共享方式.尝试获取资源,负数表示失败;0表示成功,但没有生育可用资源;证书表示成功且有剩余资源
tryReleaseShared(int)//共享方式尝试释放资源n,成功返回true,失败返回false默认情况下,每个方法都抛出unsupptedOperationException.这些方法的实现必须是内部线程安全的,并且通常应该简单而不是阻塞.AQS类中的其他方法都是final,所以无法被其他类使用,只有这几个方法可以被其他类使用.
以reentrantLock为例,state初始化为0,表示未锁定状态.A线程Lock时,会调用tryAcquire()独占锁并将state+1.此后,其他线程再tryQcquire时就会失败,直到A线程unlock()到state=0(即释放锁)为止,其它线程才有机会获取该锁.当然释放锁之前,A线程自己是开源重复获取此锁的(state会累加),这就是可重入的概念.但是要注意获取多少次就压哦释放多少次,这样才能保证state是能回到零态的.
ABstractQueuedSynchronizer数据结构
AbstractQueuedSynchronizer类底层的数据结构是用CLH队列.AQS是将每条请求共享资源的线程封装成一个CLH锁队列的一个节点Node来实现锁分配的.其中cyncQueue同步队列,是双向链表,包括head节点和tail节点,head节点主要作用后续的调度,而Conditionqueue不是必须的.,其是一个单向链表,只有当使用Condition时,才会存在此单向链表,并且可能会有多个Condition queue
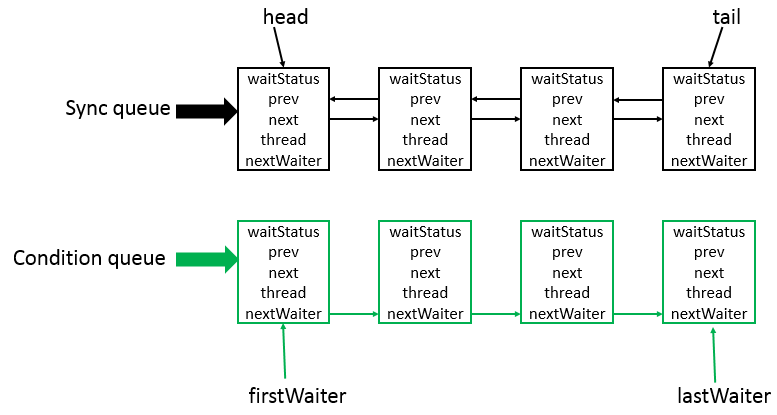
ReentrantLock详解
类的内部关系
ReentrantLock继承了Lock接口 ,Lock接口中定义了lock与unlock相关操作,并且还存在newCondition方法表示生成一个条件
public class ReentrantLock implements Lock, java.io.Serializable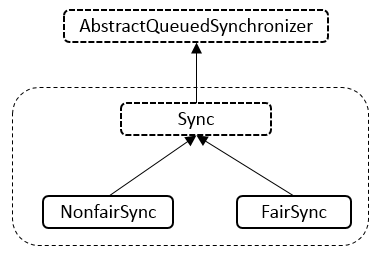
ReentrantLock总共有三个内部类,并且三个内部类是紧密相关的,下面先看三个内部类的关系
ReentrantLock内部存在SyncNotifairSync,FirSync三个类,NofairSync与FairSync都继承自Sync类,Sync类继承自AbstractQueuedSynchronizer抽象类.
Sync类
存在如下方法和作用
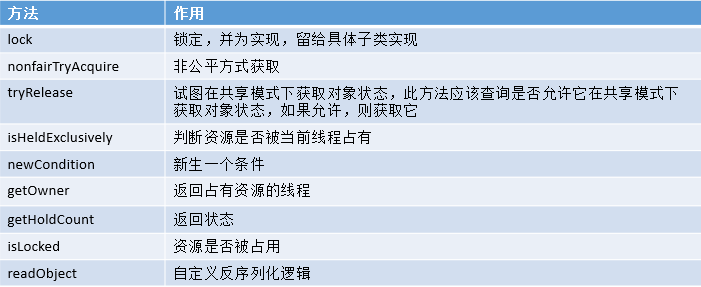
NonfairSync类
继承了Sync类,表示采用非公平策略获取锁,其实现了Sync类中抽象的Lock方法
// 非公平锁
static final class NonfairSync extends Sync {
// 版本号
private static final long serialVersionUID = 7316153563782823691L;
// 获得锁
final void lock() {
if (compareAndSetState(0, 1)) // 比较并设置状态成功,状态0表示锁没有被占用
// 把当前线程设置独占了锁
setExclusiveOwnerThread(Thread.currentThread());
else // 锁已经被占用,或者set失败
// 以独占模式获取对象,忽略中断
acquire(1);
}
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
}说明: 从lock方法的源码可知,每一次都尝试获取锁,而并不会按照公平等待的原则进行等待,让等待时间最久的线程获得锁。
FairSync类
FairSync类,表示采用非公平策略获取锁,其实现了Sync类中的抽象方法
// 公平锁
static final class FairSync extends Sync {
// 版本序列化
private static final long serialVersionUID = -3000897897090466540L;
final void lock() {
// 以独占模式获取对象,忽略中断
acquire(1);
}
/**
* Fair version of tryAcquire. Don't grant access unless
* recursive call or no waiters or is first.
*/
// 尝试公平获取锁
protected final boolean tryAcquire(int acquires) {
// 获取当前线程
final Thread current = Thread.currentThread();
// 获取状态
int c = getState();
if (c == 0) { // 状态为0
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) { // 不存在已经等待更久的线程并且比较并且设置状态成功
// 设置当前线程独占
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) { // 状态不为0,即资源已经被线程占据
// 下一个状态
int nextc = c + acquires;
if (nextc < 0) // 超过了int的表示范围
throw new Error("Maximum lock count exceeded");
// 设置状态
setState(nextc);
return true;
}
return false;
}
}说明: 跟踪lock方法的源码可知,当资源空闲时,它总是会先判断sync队列(AbstractQueuedSynchronizer中的数据结构)是否有等待时间更长的线程,如果存在,则将该线程加入到等待队列的尾部,实现了公平获取原则。其中,FairSync类的lock的方法调用如下,只给出了主要的方法。
可以看出来只要资源被其他线程占用,该线程就会添加到syncqueue中的尾部,而不会先尝试获取资源.这也是和Nonfair最大的区别.Nonfair每一次都会去尝试获取资源,如果此时该资源恰好被释放,则会被当前线程获取到这就操作成了不公平现象,当获取不成功,再加入尾部
ReentrantLock类的sync非常重要,对ReentrantLock类的操作大部分都直接转化为对Sync和AbstractQueuedSynchronizer类的操作。
public class ReentrantLock implements Lock, java.io.Serializable {
// 序列号
private static final long serialVersionUID = 7373984872572414699L;
// 同步队列
private final Sync sync;
}类的构造函数
默认采用的是非公平策略获取锁
public ReentrantLock() {
// 默认非公平策略
sync = new NonfairSync();
}也可以传入参数表示是否是非公平锁,为true表示非公平策略,否则采用公平策略
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}分析
通过分析ReentrantLock的源码,可知对其操作都转换为Sync对象的操作,由于Sync继承了AQS,所以基本上可以转化为对AQS的操作.讲ReentrantLock的lock函数转换为对Sync的lock函数的调用,二聚体会采用策略(如公平策略或者非公平策略)的不同而调用到不同的sync子类
所以在ReentrantLock的背后是AQS对其服务提供了支持.
ReentrantReadWriteLock
ReentrantReadWriteLock底层是基于ReentrantLock和AbstractQueuedSynchronizer,所以ReentrantReadWriteLock的数据结构也依托于AQS的数据结构
源码分析
继承关系
public class ReentrantReadWriteLock implements ReadWriteLock, java.io.Serializable {}说明: 可以看到,ReentrantReadWriteLock实现了ReadWriteLock接口,ReadWriteLock接口定义了获取读锁和写锁的规范,具体需要实现类去实现;同时其还实现了Serializable接口,表示可以进行序列化,在源代码中可以看到ReentrantReadWriteLock实现了自己的序列化逻辑。
ReentrantReadWriteLock有五个内部类,五个内部类之间也是相互关联的。内部类的关系如下图所示。
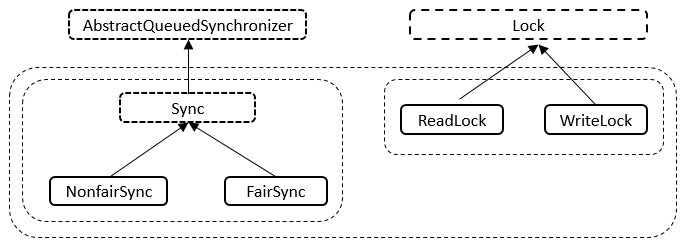
如上图所示,Sync继承自AQS,NonfairSync继承自Sync类;readLock实现了Lock接口,WriteLock也实现了Lock接口
Sync类
Sync类存在俩个内部类,分别为HoldCounter和ThreadLocalHoldCounter,其中HoldCounter主要与读锁配套使用
// 计数器
static final class HoldCounter {
// 计数
int count = 0;
// Use id, not reference, to avoid garbage retention
// 获取当前线程的TID属性的值
final long tid = getThreadId(Thread.currentThread());
}Hold
Counter主要有俩个属性,count和tid,其中count代表某个线程读线程重入的次数,tid表示该线程的tid字段的值,该字段可以用来唯一标识一个线程.
// 本地线程计数器
static final class ThreadLocalHoldCounter
extends ThreadLocal<HoldCounter> {
// 重写初始化方法,在没有进行set的情况下,获取的都是该HoldCounter值
public HoldCounter initialValue() {
return new HoldCounter();
}
}ThreadLocalHoldCounter重写了ThreadLocal的initValue方法,ThreadLocal类可以将线程与对象相关联,在没有set的情况下,get到的值均是initalValue里面生成的那个GolderCounter对象
abstract static class Sync extends AbstractQueuedSynchronizer {
// 版本序列号
private static final long serialVersionUID = 6317671515068378041L;
// 高16位为读锁,低16位为写锁
static final int SHARED_SHIFT = 16;
// 读锁单位
static final int SHARED_UNIT = (1 << SHARED_SHIFT);
// 读锁最大数量
static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1;
// 写锁最大数量
static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1;
// 本地线程计数器
private transient ThreadLocalHoldCounter readHolds;
// 缓存的计数器
private transient HoldCounter cachedHoldCounter;
// 第一个读线程
private transient Thread firstReader = null;
// 第一个读线程的计数
private transient int firstReaderHoldCount;
}改属性中包括了读锁,血锁线程的最大量,本地线程计数器等
构造函数
Sync() {
// 本地线程计数器
readHolds = new ThreadLocalHoldCounter();
// 设置AQS的状态
setState(getState()); // ensures visibility of readHolds
}在Sync的构造函数中设置了本地线程计数器和aqs的状态state
构造函数
public ReentrantReadWriteLock() {
this(false);
}会调用另外一个有残的构造函数
著作权归https://pdai.tech所有。
链接:https://www.pdai.tech/md/java/thread/java-thread-x-lock-ReentrantReadWriteLock.html
public ReentrantReadWriteLock(boolean fair) {
// 公平策略或者是非公平策略
sync = fair ? new FairSync() : new NonfairSync();
// 读锁
readerLock = new ReadLock(this);
// 写锁
writerLock = new WriteLock(this);
}可以指定设置公平策略或者非公平策略,并且该构造函数中生成了读锁和写锁俩个对象
锁升降级
什么是锁升降级?
升降级指的是写锁降级成为读锁.如果当前线程拥有写锁,然后将其释放,最后再获取读锁,这种分段完成的过程不能称之为锁降级.
所降级指把持住当前的写锁,再获取到读锁,随后释放之前有的写锁的过程
接下来看一个锁降级的示例。因为数据不常变化,所以多个线程可以并发地进行数据处理,当数据变更后,如果当前线程感知到数据变化,则进行数据的准备工作,同时其他处理线程被阻塞,直到当前线程完成数据的准备工作,如代码如下所示:
public void processData() {
readLock.lock();
if (!update) {
// 必须先释放读锁
readLock.unlock();
// 锁降级从写锁获取到开始
writeLock.lock();
try {
if (!update) {
// 准备数据的流程(略)
update = true;
}
readLock.lock();
} finally {
writeLock.unlock();
}
// 锁降级完成,写锁降级为读锁
}
try {
// 使用数据的流程(略)
} finally {
readLock.unlock();
}
}上述事例中,当数据发生变更后,update变量(布尔值切volatile修饰)被设置为false,此时所有访问processData()方法的线程都能感知到变化,但只有一个线程能够获取到写锁,其他线程会被阻塞在读锁和写锁的lock上.当前线程完成数据准备之后,再获取读锁,随后释放写锁,完成锁降级
锁降级中读锁的获取是否必要呢,答案是必要的.主要是为了保证数据的可见性,如果当前线程不获取读锁,而是直接释放写锁,假设刺客另一个线程(T)获取了写锁并修改了数据,那么当前线程无法感知线程T的数据更新.如果当前线程获取读锁,即遵循锁降级的步骤,啧线程T将会被阻塞,知道当前线程使用数据并释放读锁之后,线程T才能获取写锁进行数据更新
RentrantReadWriteLock不支持锁升级(把持读锁,获取写锁,最后释放读锁的过程).目的也是保证数据的可见性,如果读锁多已被多个线程虎丘,其中仍有任意线程成功获取了写锁并更新了数据,啧其更新对其他读锁的线程是不可见的