Mysql存储原理
简介
mysql Innodb数据由B+树来组织,数据记录存储在B+树数据页page中,每个数据页16kb,数据页包括
- 页头
- 虚记录
- 记录堆
- 自由空间链表
- 未分配空间
- slot区
- 页尾
七部分组成
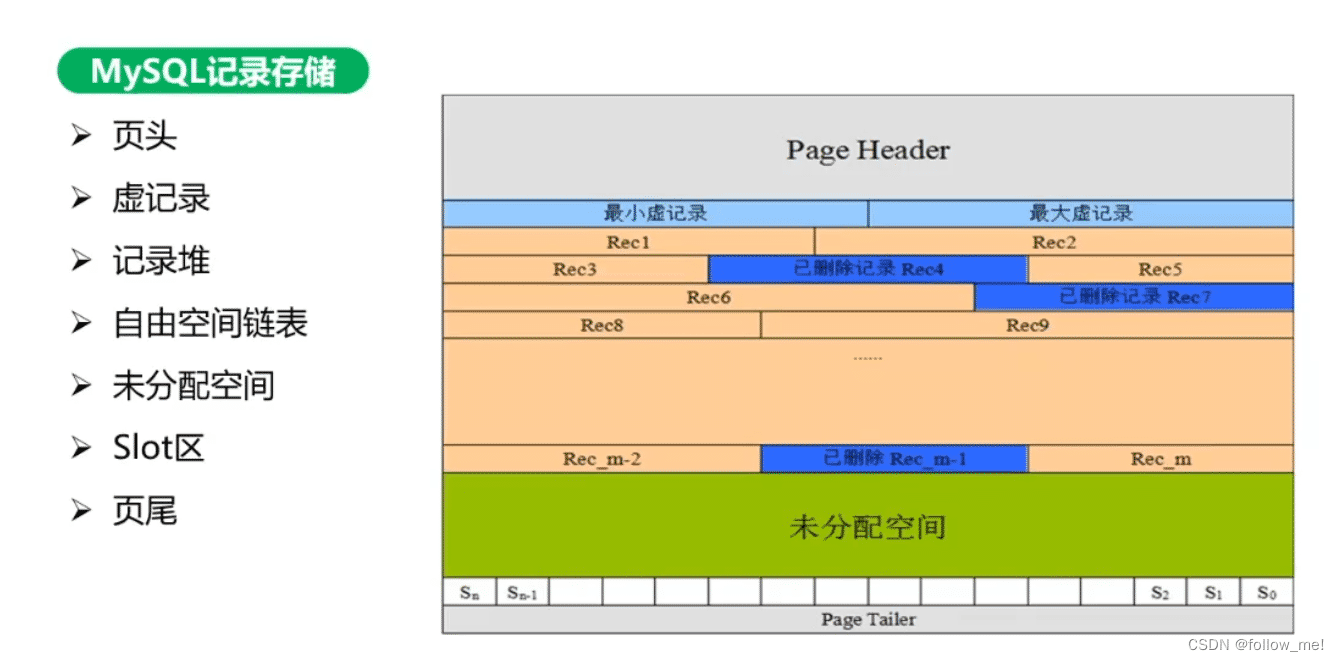
- 页头
56个字节,记录本页的信息,包括页的的左右兄弟页指针(双向列表,可使用此双向链表遍历数据,会比遍历链表快),页面使用情况等 - 虚记录
包括最小虚记录(比页内最小的主键还小),最大虚记录(比页内最大主键还大),表示本页key的数据范围 - 记录堆
本页已存储的数据记录,包括有效记录,已删除记录 - 自由空间链表
本页被删除的数据(逻辑删除)会用的链表,称为自由空间列表,以便后续能再次利用 - 未分配空间
本页未被使用的空间 - slot区
(槽位)用于页内的快速查询,Slot区为等值的数组,可进行二分查找 - 页尾
8个字节,主要存储本页的检验信息(有无发生过错误)
页内记录维护
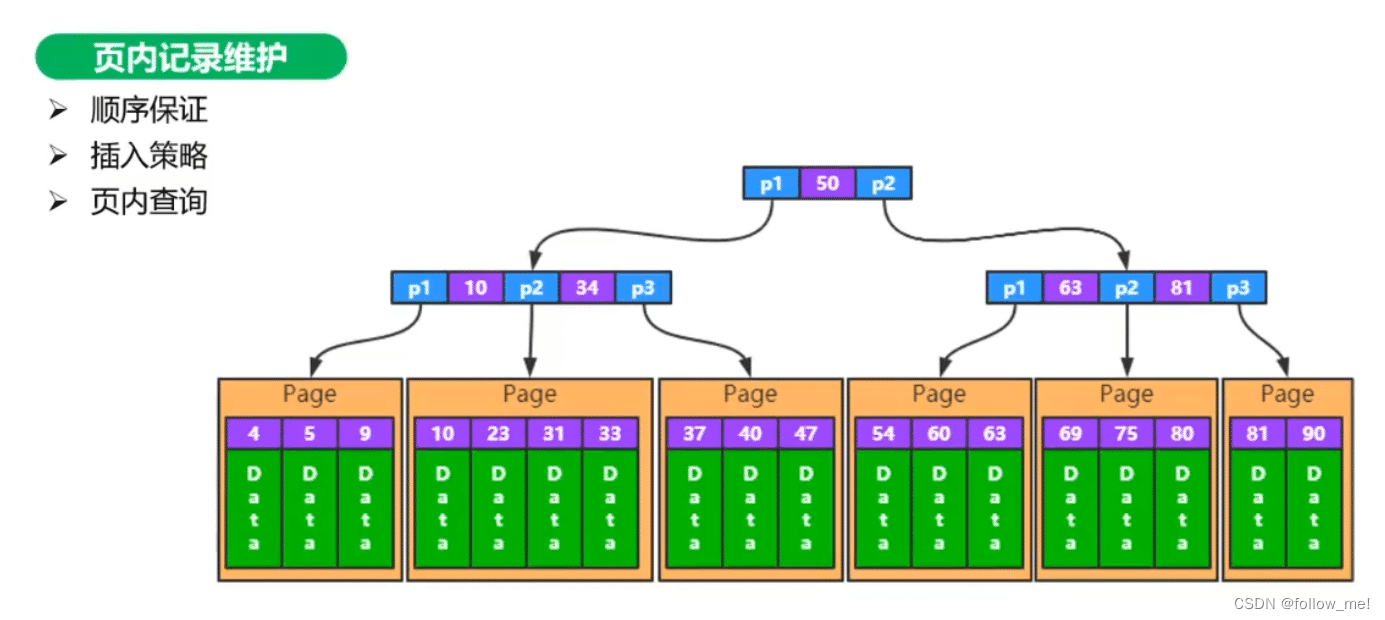
页内顺序
逻辑连续。页之间有双向链表,页内也有链表,双向链表可以提供范围查询使用
采用什么方式存储,主要考量读写性能。物理连续,每次插入可能涉及数据移动,写入性能低,查询效率页无法向数组一样使用二分查找,数组的数据类型一致,数据长度一致,但记录数据的长度因存在变长字段而不定。
逻辑连续,写入不涉及数据移动性能高,查询需要利用slot区优化,不优化需要遍历整个链表,优化后只需要遍历subList

变长数据

字段:长度+内容,mysql varchar类型的字段默认给的长度问什么是255,而非256,因为255时,长度用1个字节就可以了
每个pageSize 16kb,每页至少存2条数据,页内单行数据最大8kb,超出8kb后会存在溢出表,超出部分放到溢出页中(称之为行溢出)当某一行数据过大,导致数据页存放不下时,我们把这种情况叫做溢出,简单的解决方式就是把记录存储在溢出页(磁盘其他空暇的地方中)
- 若列的长度小于255字节,则用1字节表示
- 若大于255字节,则用2字节表示
- 边长字段的长度最大不可超过俩字节,这是因为varchar类型最大的长度限制是65545(2^16-1)
索引使用优化
主键选择
- 自增主键:顺序写入,写入效率高,步长位1,但是容易暴露商业信息,或者每次查询走二级索引
- 随机主键:如UUID容易造成页分裂,写入效率低
- 业务主键:如雪花算法,写入查询的效率都很高,可直接使用一级索引
- 联合主键:影响索引大小,不易维护,不建议使用
Innodb内存管理
InnoDB会在内存中申请一片内存(内存池),数据是以数据页为最小单位(16kb)通过映射关系加载到内存,加载到内存的数据页分为空数据页,冷数据页,热数据页,脏数据页。如果过数据页被使用完毕,InnoDB会通过LRU,LFU等方式映射关系进行数据内外存置换,淘汰冷数据,加载新数据,脏数据固化等
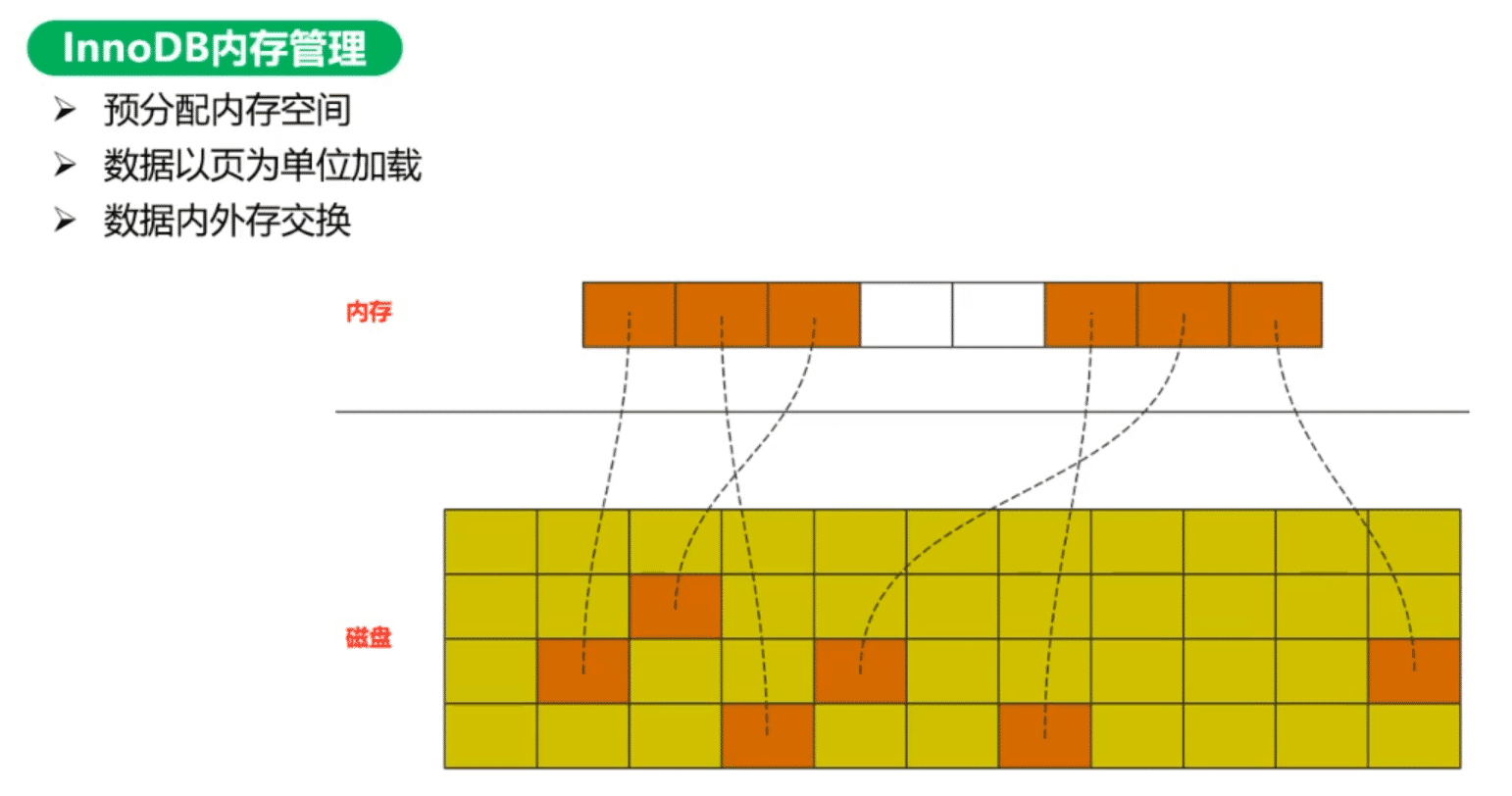
lru
LRU是least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。但是LRU全表扫描时一次性加载大量数据,可能会将内存池完全更新一遍,无论原来内存池中有多少热数据都会被淘汰,所以innoDB在LRU的基础上进行了优化,避免数据被淘汰
优化:避免热数据被淘汰(访问时间+频率)(价格LRU表,一个热数据的LRU表,一个冷数据的LRU表,只能淘汰冷数据的LRU表,热数据转冷,冷数据转热)
LRU和LFU区别:LRU是淘汰最常时间没有被使用的页面,LFU是淘汰一段时间内,使用次数最少的页面
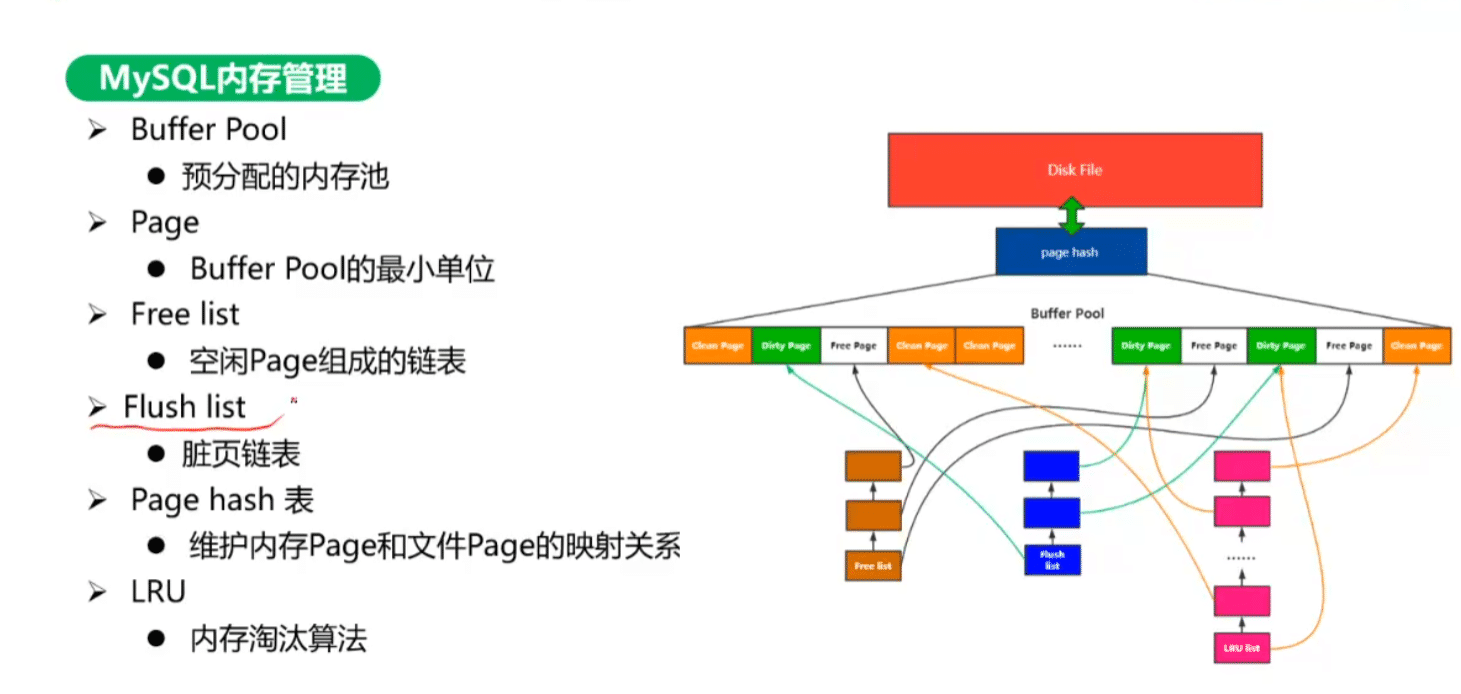 Buffer Pool:
Buffer Pool:
预分配的内存。
Page:
16k,Buffer Pool的最小单位。
Free List:
空闲的Page组成的链表。
Flush list:
脏数据页,被改动的数据,需要持久化的数据。
Page hash表:
维护内存Page与文件Page的映射关系。
LRU:
内存淘汰算法,包括脏数据页、净数据页,净数据分为冷数据表与热数据表,中间用Midpoint,冷数据5/8,热数据3/8,冷热分离

页面状态
- 页面状态:磁盘数据到内存,首先从空闲链表取出空闲页,将数据放入,然后将此空闲页(此时已经为非空闲页)连接到LRU的old部分;但是如果没有空闲页的话,就会启动页面淘汰。
- 页面淘汰:首先从LRU的尾部淘汰冷数据,如果数据被锁淘汰不了,就LRU flush,如果降低一个脏页刷盘【1】,先放到LRU尾部【2】再放到freeList【3】还是直接放到freeList
mysql最早经历123步,后来13,再优秀的产品也是一步一步迭代过来的。
位置移动
select from table 时,如果用LFU算法(使用频率)来LRU,那么select from table 全表扫描时,会将某page加载到内存,然后逐条遍历数据,那么短时间内此page会高频次被使用,那么此页就会称为热数据,当大量的页成为热数据时,原来的热数据就会被误淘汰。
old到new:
LRU_old中的数据被使用就会放到LRU_old表头,如果某数据在LRU_old中存活时间超过某值innodb_old_block_time,就有机会进入L RU_new,放于LRU_new的head。
new到old:
LRU_new的数据再老默认也比LRU_old中的数据新,所以LRU_new中淘汰的数据会放在LRU_old的head;实现方式是,移动Midpoint,保证Midpoint始终指向5/8的位置。
LRU_new的操作
如果每次使用到的数据页都移动至LRU_new的head,但由于在多线程,存在LOCK,可能会串行移动,效率低。MySql的设计思路是减少移动次数, freed_page_clock: Buffer Pool淘汰的页数,如果总淘汰数a减去当前page上次处于head时的Buffer Pool淘汰的页数b,大于LRU_new的1/4时,开启淘汰。
freeList
维护空闲数据页,在数据库刚启动时,buffer pool中的数据页是空闲的,mysql会将这些空闲的数据 页添加到一个链表中,即Free List;
Mysql启动后,BufferPool就会被初始化,在你没有执行任何查询操作之前,BufferPool中的缓存页都是一块块空间的内存,未被使用也没有任何数据保存在里面。
而且你也知道了通过缓存页的描述信息可以直接且唯一的找到它只想的缓存页。
那你也没用想过,我们从磁盘里读出来的数据页,应该放到哪个缓冲页中去呢?
这个问题就引入除了freeList
其实FreeList是BufferPool中基于缓存页描述信息组织起来的双向链表。换言之,FreeList中的每一个节点都是缓存页对应对应描述信息。并且通过描述信息可以找到制定的缓存页
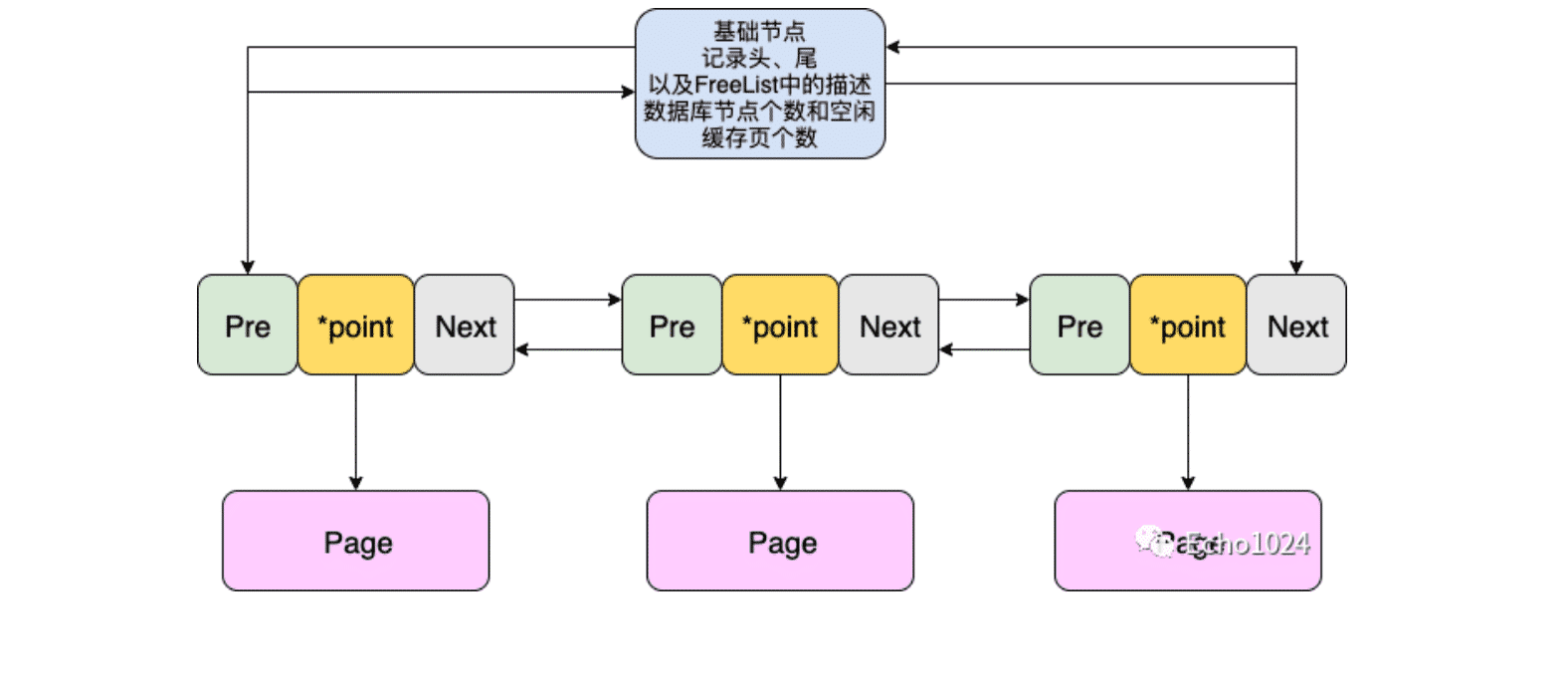
InnoDB设计Free List的初衷就是为了解决上面说的问题。
如果这个缓存页中没有存储任何数据,那么它对应的描述信息就会被维护进Free List中。这时当你想把从磁盘中读取出一个数据页放入缓存页中的话,就得先从Free List中找一个节点(Free List中的所有节点都会指向一个从未被使用过的缓存页),那接着就可以把你读取出来的这个数据页放入到该节点指向的缓存页中。
相应的:当数据页中被放入数据之后。它对应的描述信息块会被从Free List中移出。
三、如何判断数据页有没有在缓存中?
你会不会纳闷MySQL怎么知道刚读取出来的这个数据页有没有在缓存页中呢?
这个功能的实现依托于另一个数据结构:hash table
key = 表空间号+数据页号
value = 缓存页地址
如果存在于hash table中,那就说明该数据页已经存在于Buffer Pool中了,优先使用Buffer Pool中的缓存页。相信你肯定能想到为啥优先使用Buffer Pool中的缓存页吧!首先免去了磁盘的随机IO,其次缓存页中的数据可能是已经被修改了的脏数据。