RocksDB
译:一文科普 RocksDB 工作原理 - 知乎 (zhihu.com)
导语
近几年,RocksDB 的采用率急速上升,俨然成为内嵌型键值存储(以下简称 kv 存储)的不二之选。
目前,RocksDB 在 Meta、Microsoft、Netflix 和 Uber 等公司的生产环境上运行。在 Meta,RocksDB 作为 MySQL 部署的存储引擎,为分布式图数据库(TAO)提供支持存储服务。
大型科技公司并非 RocksDB 的仅有用户,像是 CockroachDB、Yugabyte、PingCAP 和 Rockset 等多个初创企业都构建在 RocksDB 基础之上。
RocksDB是什么
RocksDB是一种持久化的、内嵌型kv存储。它是为了存储大量的key以及对应value设计出来的数据库。可以基于这种简单的kv数据结构来构建倒排索引、文档数据库、SQL数据库、缓存系统和消息代理等复杂系统。
RocksDB是2012年从Google的LevelDB fork出来的分支,并针对跑在SSD上的服务进行了优化。目前,RocksDB由Meta开发和维护。
RocksDB使用C++编写,因此除了支持C和C++之外,还能通过C binding的形式嵌入到其他语言编写的应用中,例如Rust、GO或Java。
如果你之前用过SQLite,你肯定知道什么是内嵌式数据库。在数据库领域,特别是RocksDB的上下文中,内嵌意味着:
- 该数据库没有独立进程,而是被继承进应用中,和应用共享内存资源,从而避免了跨进程通信的开销
- 它没有内置服务器,无法通过网络进行远程访问。
- 它不是分布式的,这意味着它不提供容错性、冗余或分片机制。
如有必要,需依赖应用层来实现上述功能。
RocksDB 以kv对集合的形式存储数据,key和value是任意长度的字节数组(byte array),因此都是没有类型的。RocketDB提供给了很少的几个用于修改kv集合的函数底层接口:
put(key, value):插入新的键值对或更新已有键值对merge(key, value):将新值与给定键的原值进行合并delete(key):从集合中删除键值对
通过点查来获取key关联的value:
get(key)
通过迭代器可以进行范围扫描——找到特定的 key,并按顺序访问该 key 后续的键值对:
iterator.seek(key_prefix); iterator.value(); iterator.next()
Log-structured merge-tree
RocksDB的核心数据结构被称为日志结构合并树(LSM-Tree)。它是一种树形的数据结构,由多个层级组成,每层的数据按key有序。LSM-Tree主要设计用来应对写入密集型工作负载,并于 1996 年在同名论文 The Log-Structured Merge-Tree (LSM-Tree) 被大家所知。
LSM-Tree 的最高层保存在内存中,包含最近写入的数据。其他较低层级的数据存储在磁盘上,层数编号从 0 到 N 。第 0 层 L0 存储从内存移动到磁盘上的数据,第 1 层及以下层级则存储更老的数据。通常某层的下个层级在数据量上会比该层大一个数量级,当某层数据量变得过大时,会合并到下一层。
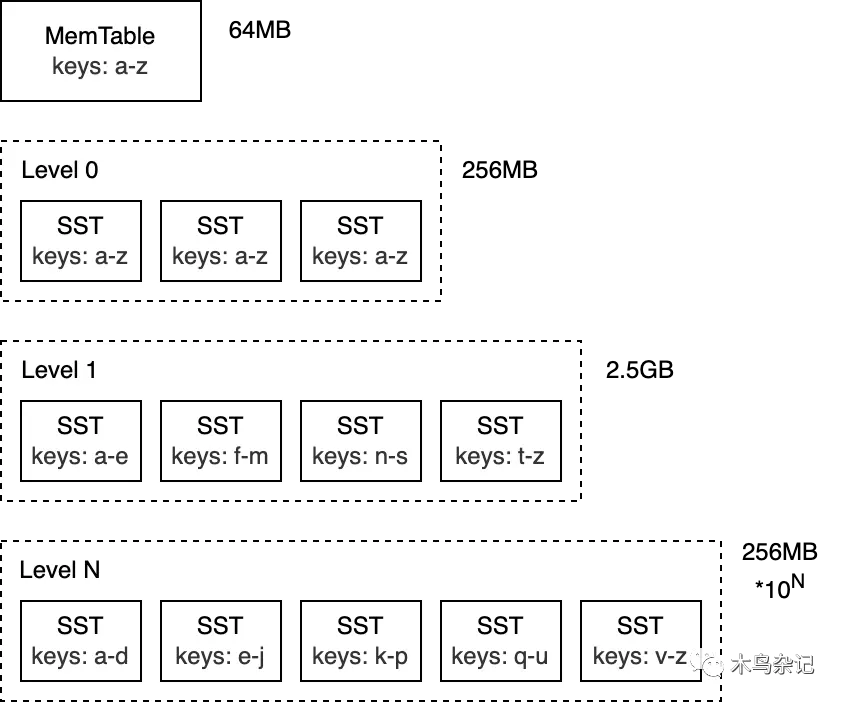
注:虽然本文主要讨论 RocksDB,但涉及 LSM-Tree 的概念适用于大多数底层采用此技术实现的数据库(例如 Bigtable、HBase、Cassandra、ScyllaDB、LevelDB 和 MongoDB WiredTiger)。
为了更好地理解 LSM-Tree 的工作原理,下面我们将着重剖析它的写 / 读路径。
写路径
MemTable
LSM-Tree的顶层被称为MemTable。MemTable是一个内存缓冲区,在键值对写入磁盘之前,Memtable会缓存住这些键值对。所有插入和更新操作都会过MemTable。当然也包括删除操作:不过:RocksDB并不会直接原地修改键值对,而是通过 插入墓碑记录(tombstone)来进行标记删除。
MemTable具有可配置的字节数限制。当一个MemTable变满时,就会切到一个新的MemTable,同时原MemTable变为不可修改状态。
注:MemTable的默认大小为64MB
db.put("chipmunk", "1")
db.put("cat", "2")
db.put("raccoon", "3")
db.put("dog", "4")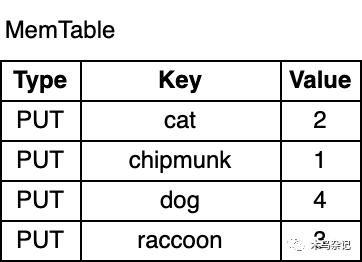
如上图所示,MemTable中键值对是按key有序排列的。尽管chipmunk是最先插入的,但由于MemTable是按key有序的,因此chipmunk排在cat之后。这种排序对于范围扫描是必须的,它也会让某些操作更加高效。
预写日志
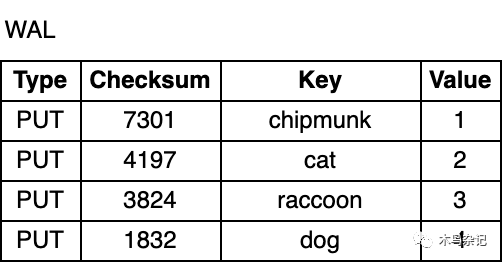
无论是在进程以外崩溃退出还是计划内重启时,其内存中的数据丢失。为了防止数据丢失,保证数据持久化,除了MemTable之外,RocksDB会将所有更新写入到磁盘上的预写日志(WAL,Write-ahead log)中,这样在重启后,数据库可以放回日志,进而恢复MemTable的原始状态。
WAL是一个只允许追加的文件,包含一组更改记录序列。每个记录包含键值对、记录类型(Put、Merge、Delete)和校验和(checksum)。与MemTable不同,在WAL中,记录不按key有序,而是按照请求到来的顺序被追加到WAL中。
Flush
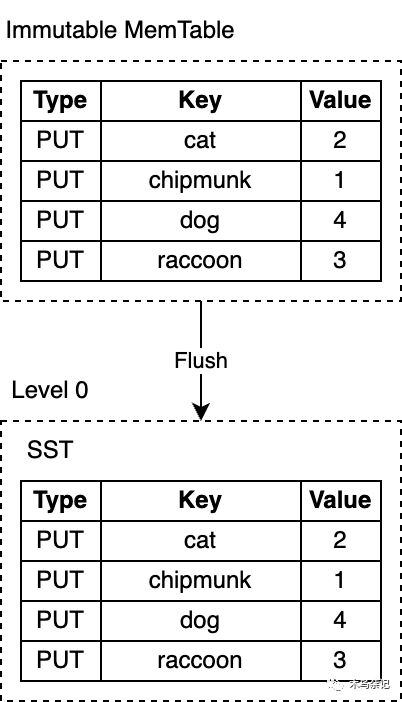
RocksDB 使用一个专门的后台线程定期地把不可变的 MemTable 从内存持久化到磁盘。一旦刷盘(flush)完成,不可变的 MemTable 和相应的 WAL 就会被丢弃。RocksDB 开始写入新的 WAL、MemTable。每次刷盘都会在 L0 层上产生一个新的 SST 文件。该文件一旦写入磁盘后,就不再会修改。
RocksDB的MemTable的默认基于跳表实现。该数据结构是一个具有额外采样层的链表,从而允许快速,有序地查询和插入数据。有序性使得MemTable刷盘时更搞笑,因为可以直接按顺序迭代键值对对顺序写入磁盘。将随机写变为顺序写是LSM-Tree的核心设计之一。
RocksDB高度可配,因此你可以给MemTable配置其他实现方案,RocksDB中大部分组件都是如此。在其他的基于LSM实现的数据库中,使用自平衡二叉搜索树来实现MemTable并不鲜见。
SST
SST文件包括从MemTable刷盘而来的键值对,并且使用一种对查询友好的数据格式来存储。SST是static Sorted Table的缩写(其他数据库也称为Sorted String Table)。它是一种基于块(block)的文件格式,会将数据切成固定大小的块(默认4kb)进行存储。RocksDB 支持各种压缩 SST 文件的压缩算法,例如 Zlib、BZ2、Snappy、LZ4 或 ZSTD 算法。与WAL的记录类似,每个数据块中都包含用于检测数据是否损坏的校验和。每次从磁盘读取时,RocksDB都会使用这些校验和进行校验。
SST文件由几个部分组成:首先是数据部分,包含一系列有序的键值对。Key的有序性可以让我们对其进行增量编码,也即,对于相邻的key,我们可以只存其差值而非整个key。
尽管SST中的kv对是有序的,我们也并非总能进行二分查找,尤其是数据块在压缩后,会使得查找很低效。RocksDB使用索引来优化查询,存储在紧邻之后的索引块。Index会把每个block数据中最后一个key映射到它在磁盘上的对应偏移量。同样地,index中的key也是有序的,因此我们可以通过二分搜索快速找到某个key。
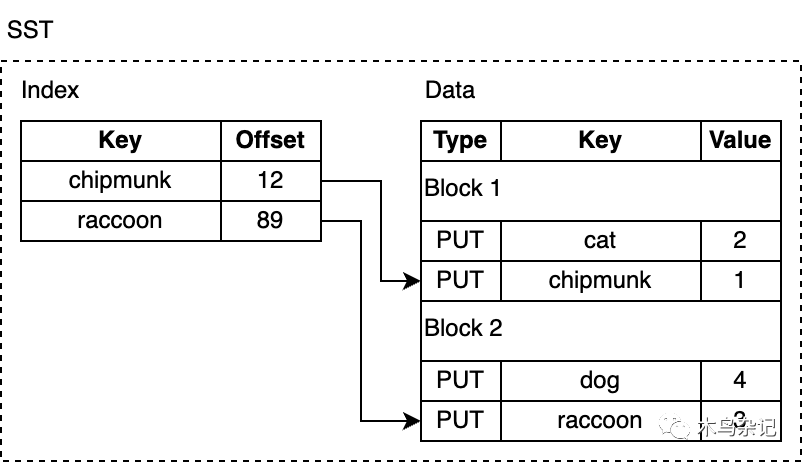
例如,我们在查找 lynx,索引会告诉我们这个键值对可能在 block 2,因为按照字典序,lynx 在 chipmunk 之后,但在 raccoon 之前。
但其实 SST 文件中并没有 lynx,但我们仍然需要从磁盘加载 block 以进行搜索。RocksDB 支持启用布隆过滤器,一种具有高效空间利用率的概率性数据结构,可以用来检测某个元素是否在集合中。布隆过滤器保存在 SST 文件中过滤器部分,以便能够快速确定某个 key 不在 SST 中(从而省去摸硬盘上的数据块的开销)。
此外,SST 还有其他几个不太有趣的部分,比如元数据部分。
Compaction
到现在为止,一个功能完备的键值存储引擎讲完了。但如果这样直接上生产环境,会有一些问题:
空间放大(space amplifications)和读放大(read amplifications)。空间放大是存储数据所用的实际空间与逻辑上数据大小的比值。假设一个数据库需要 2 MB 磁盘空间来存储逻辑上的 1 MB 大小的键值对是,那么它的空间放大率是 2。类似地,读放大用来衡量用户执行一次逻辑上的读操作,系统内所需进行的实际 IO 次数。作为一个小练习,你可以尝试推演下什么是写放大。
现在,让我们向数据库添加更多 key 并删除当中的一些 key:
db.delete("chipmunk")
db.put("cat", "5")
db.put("raccoon", "6")
db.put("zebra", "7")
// Flush triggers
db.delete("raccoon")
db.put("cat", "8")
db.put("zebra", "9")
db.put("duck", "10")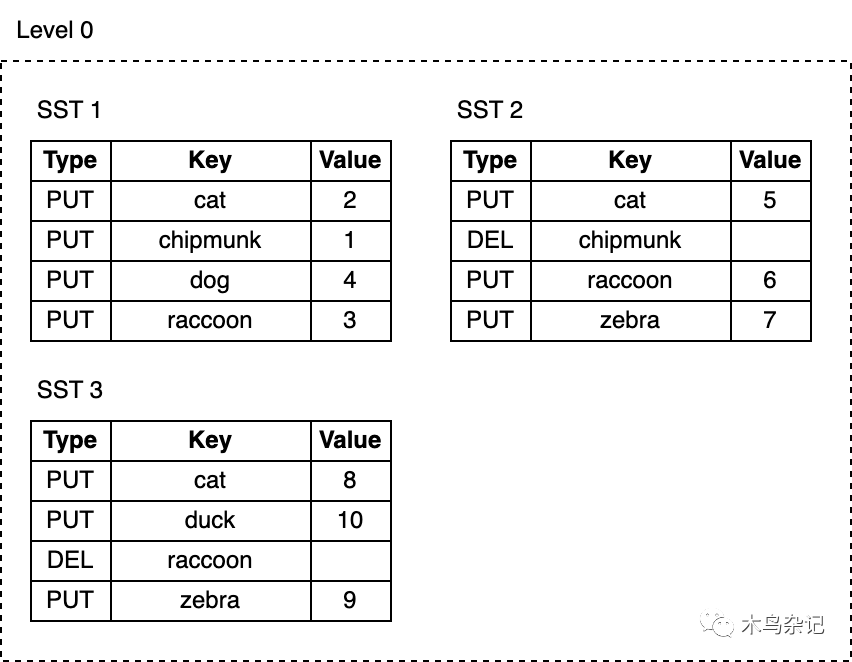
随着我们不断写入,MemTable不断被刷到磁盘,L0上的SST文件数量也在增长:
- 删除或更新key所占用的空间永远不会被回收。例如,cat这个key的三次更新记录分别在SST1,SST2和SST3中,而chipmink在SST1中有一次更新记录,在SST2中有一次删除记录,这些无用记录仍然占用额外磁盘空间。
- 随着L0上SST文件数量的增加,读取变得越来越慢。每次查找都要逐个检查所有SST文件。
RocksDB引入了压实(Compaction)机制,可以降低空间放大和读放大,但代价是更高的写放大。Compaction会将某层的SST文件同下一层的SST文件合并,并在这个过程中丢弃和删除和被覆盖的无效的key。Compaction会在后台专用线程池中运行,从而保证了RocksDB可以再做Compaction时能够正常处理用户读写请求。
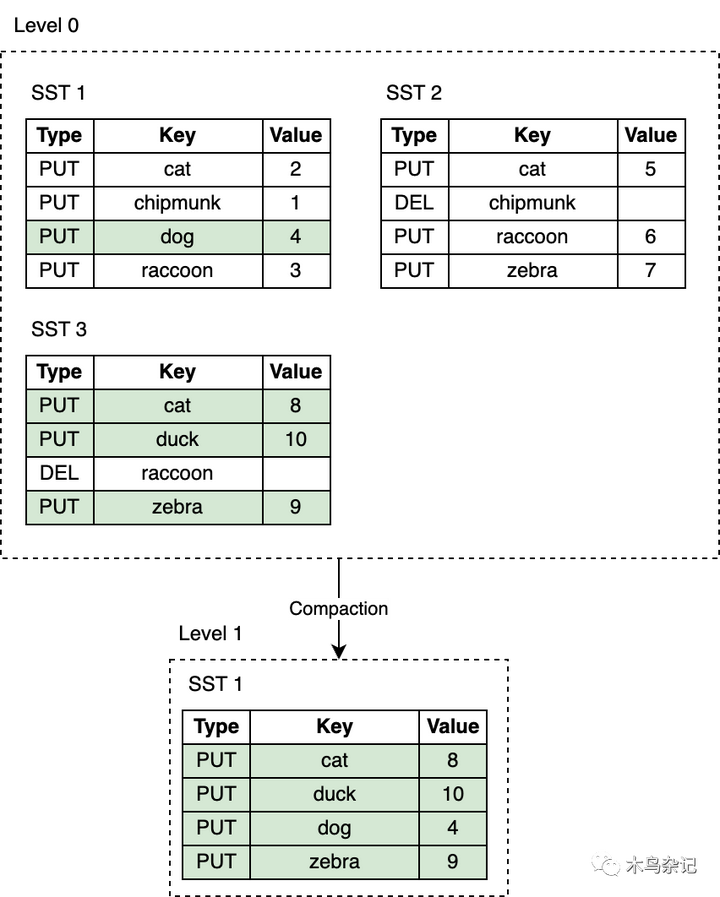
Leveled Compaction是RocksDB中默认的Compaction策略。使用Leveled Compaction,L0层集中不同SST文件键范围会重叠。L1层及以下层会被组织为多个SST文件序列,并保证同层级内所有SST在键范围上没交叠,且SST文件之间有序。Compaction时,会选择性地将某层的SST文件与下一层的key范围有重叠SST文件进行合并。
举例来说,如下图所示,在 L0 到 L1 层进行 Compaction 时,如果 L0 上的输入文件覆盖整个键范围,此时就需要对所有 L0 和 L1 层的文件进行 Compaction。
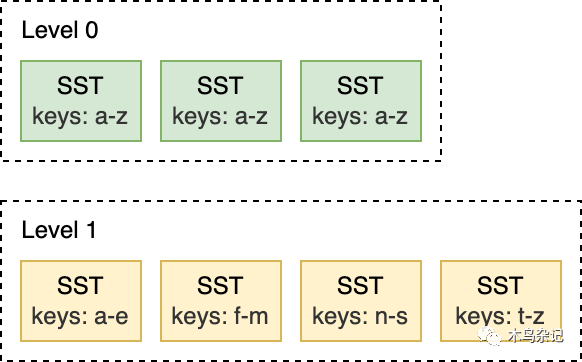
而像是下面的这种 L1 和 L2 层的 Compaction,L1 层的输入文件只与 L2 层的两个 SST 文件重叠,因此,只需要对部分文件进行 Compaction 即可。
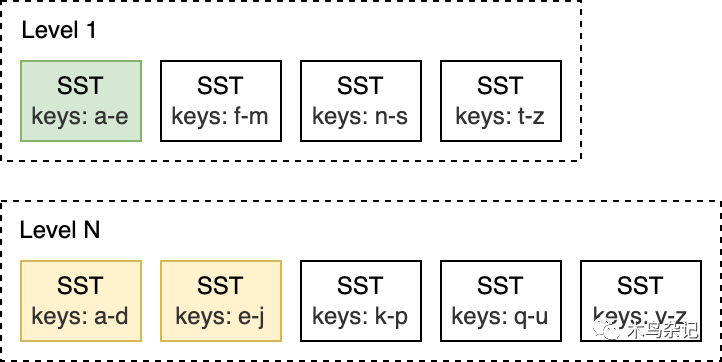
当 L0 层上的 SST 文件数量达到一定阈值(默认为 4)时,将触发 Compaction。对于 L1 层及以下层级,当整个层级的 SST 文件总大小超过配置的目标大小时,会触发 Compaction 。当这种情况发生时,可能会触发 L1 到 L2 层的 Compaction。从而,从 L0 到 L1 层的 Compaction 可能会引发一直到最底层级联 Compaction。在 Compaction 完成之后,RocksDB 会更新元数据并从磁盘中删除 已经被 Compcated 过的文件。
注:RocksDB 提供了不同 Compaction 策略来在空间、读放大和写放大之间进行权衡。
看到这里,你还记得上文提过 SST 文件中的 key 是有序的吗?有序性允许使用 K 路归并算法逐步合并多个 SST 文件。K 路归并是两路归并的泛化版本,其工作方式类似于归并排序的归并阶段。
K路归并算法是一种用于合并多个有序序列的算法。它的目标是将K个有序序列合并成一个有序序列。
读路径
使用持久化在磁盘上不可变的SST文件,读路径要比写路径简单很多。要找寻某个key,只需自顶而下遍历LSM-TREE。从MemTable开始,下探到L0,然后继续向更低层级查找,直到该key或者检查完所有SST文件为止。
以下是查找步骤:
- 检索MemTable
- 检索不可变MemTables
- 检索最近Flush过的L0层中的所有SST文件。
- 对L1层以下层级,首先找到可能包含单个key的单个SST文件,然后在文件内进行搜索。
搜索SST文件涉及
- (可选)探测布隆过滤器
- 查找index来找到可能包含这个key的block所在的位置
- 读取block文件并尝试在其中找到key。
这就是全部所需步骤了!看看这个 LSM-Tree:
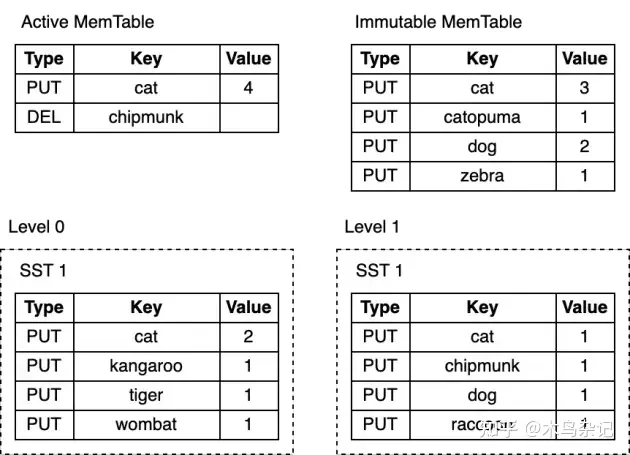
根据待查找的 key 的具体情况,查找过程可能在上面任意步骤提前终止。例如,在搜索 MemTable 后,key “cat” 或 “chipmunk” 的查找工作会立即结束。查找 “raccoon” 则需要搜索 L1 为止,而查找根本不存在的 “manul” 则需要搜索整个树。
Merge
RocksDB 还提供了一个同时涉及读路径和写路径的功能:合并(merge)操作。假设,你在数据库中存了一个整数列表,偶尔需要扩展该列表。为了修改列表,你需要从数据库中读取其现有值,在内存中更新该列表,最后把更新后的值写回数据库。
上面整个操作序列被称为 “Read-Modify-Write” 循环:
db = open_db(path)
// 读取 Read
old_val = db.get(key) // RocksDB stores keys and values as byte arrays. We need to deserialize the value to turn it into a list.
old_list = deserialize_list(old_val) // old_list: [1, 2, 3]
// 修改 Modify
new_list = old_list.extend([4, 5, 6]) // new_list: [1, 2, 3, 4, 5, 6]
new_val = serialize_list(new_list)
// 写回 Write
db.put(key, new_val)
db.get(key) // deserialized value: [1, 2, 3, 4, 5, 6]上面这种方式能达到目的,但存在一些缺陷:
- 非线程安全——两个尝试更新相同的 key 的不同线程,交错执行,会出现更新丢失。
- 存在写放大——随着值变得越来越大,更新成本也会增加。例如,在含有 100 个数的列表中追加一个整数需要读取 100 个整数并将 101 个整数写回。
除了 Put 和 Delete 写操作之外,RocksDB 还支持第三种写操作 Merge。Merge 操作需要提供 Merge Operator——一个用户定义函数,负责将增量更新组合成单个值:
funcmerge_operator(existing_val, updates) {
combined_list = deserialize_list(existing_val)
for op in updates {
combined_list.extend(op)
}
return serialize_list(combined_list)
}
db = open_db(path, {merge_operator: merge_operator})
// key's value is [1, 2, 3]
list_update = serialize_list([4, 5, 6])
db.merge(key, list_update)
db.get(key) // deserialized value: [1, 2, 3, 4, 5, 6]上面的 merge_operator 将传递给 Merge 调用的增量更新组合成一个单一值。当调用 Merge 时,RocksDB 仅将增量更新插入到 MemTable 和 WAL 中。之后,在 flush 和 compaction 时,RocksDB 调用 merge_operator() ,在条件允许时,将若干更新合并成单个更新或者单个值。在用户调用 Get 或扫描读取数据时,如果发现任何待 merge 的更新,也会调用 merge_operator 向用户返回一个经过 merge 而得到的值。
Merge 非常适合于需要持续对已有值进行少量更新的写入密集型场景。那么,代价是什么?读将变得更加昂贵——读时的合并值没有写回。对该 key 的查询需要一遍又一遍地执行相同的合并过程,直到触发 flush 和 compaction 为止。与 RocksDB 其他部分一样,我们可以通过限制 MemTable 中 merge 对象的数量、降低 L0 中 SST 文件数量来优化读行为。
总结
如果你的应用对性能非常敏感,那么使用 RocksDB 面临的最大挑战是需要针对特定工作负载来进行配置调优。RocksDB 提供了非常多的可配置项,但对其进行合理调整通常需要理解数据库内部原理并深入研究 RocksDB 源代码:
从零开始写一个生产级别的 kv 存储是非困难的:
- 硬件和操作系统随时都有可能丢失或损坏数据。
- 性能优化需要大量时间投入。
RocksDB 解决了上述两个问题,从而让你可以专注于上层业务逻辑实现。这也使得 RocksDB 成为构建数据库的优秀模块。