Hive学习笔记2
概述
为什么使用hive
使用Hadoop MapReduce直接处理数据
人员学习成本太高 需要掌握java语言
mapReduce实现复杂查询逻辑开发难度太大
使用hive的好处
操作接口采用类sql语法,提供快速开发能力
避免直接写mapReduce,减少开发人员的学习成本
支持自定义函数,功能扩展方便
背靠hadoop,擅长存储分析海量数据
hive录用mapReduce查询分析数据,用hdfs存储数据
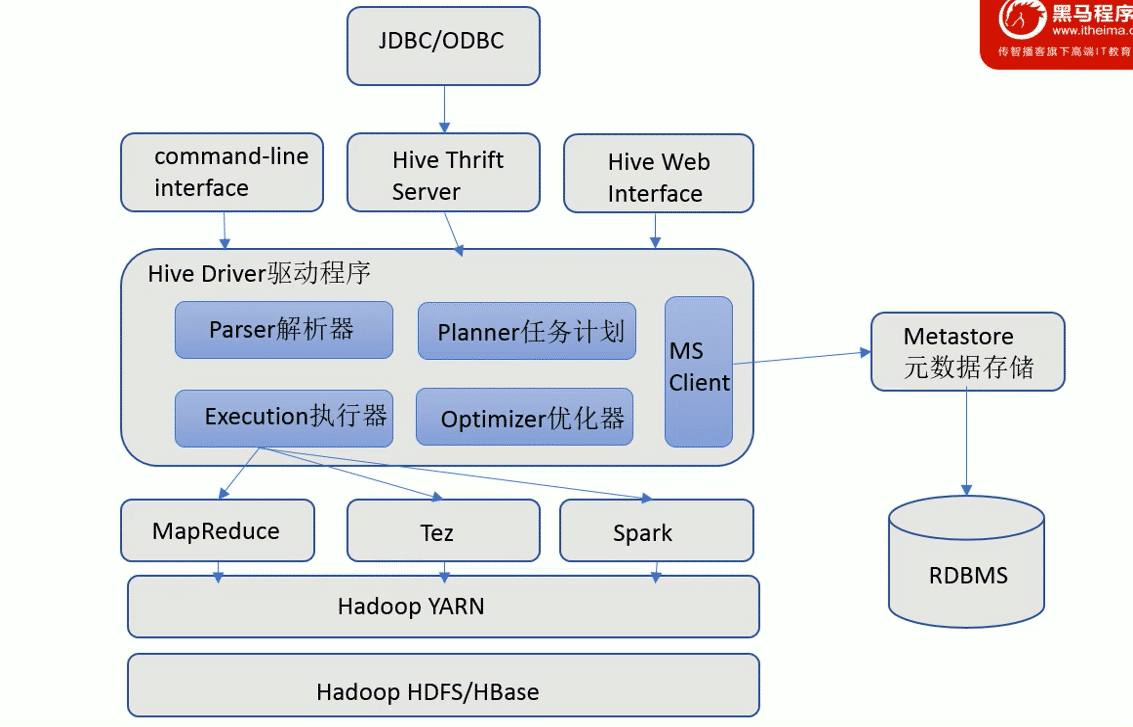
组件
用户接口
包括CLI,JDBC,WebGUIU,Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交换,类似于JDBC或ODBC协议.WebGui是通过浏览器访问Hive
元数据存储
通常是存储在关系型数据库mysql/derby中.hive中的元数据包括的表的名字,表的列和分区及其属性,表的属性(是否为外部表),表的数据所在目录等
Driver驱动程序
包括语法解析器,编译器,优化器,执行器
完成HQL查询语句从词法分析,语法分析,编译,优化以及查询计划的生成.生成的查询计划存储在HDFS中,并在随后又执行引擎调用执行
执行引擎
hive本身并不直接处理数据文件.而是通过执行引擎进行处理.当下hive支持mapReduce,TEZ,spark3种执行引擎
数据模型
数据模型:原来描述数据,组织数据对数据进行操作,是对现实世界数据特征的描述
hive的数据模型类似于RDBMS库表结构,此外还有自己特有的模型
hive中的数据在粒度级别上分为三类
- Table表
- partition 分区
- bucket 分桶
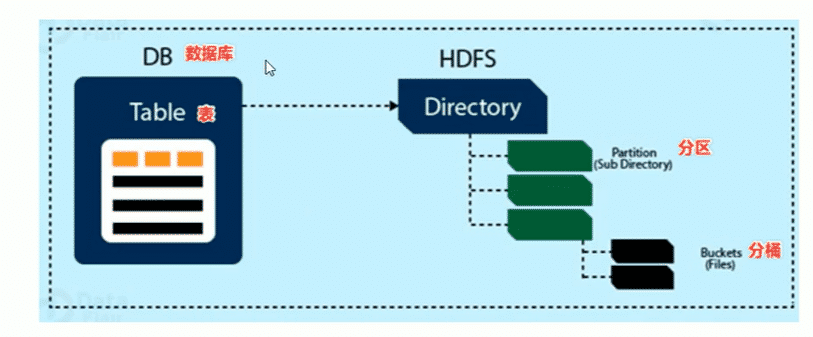
数据库
- hive作为一个数据库,在结构上积极向传统数据库看齐,也分数据库(Schema)每个数据库下面有各自的表组成.默认数据库default
- hive的数据都是存储在hdfs上的,默认有一个根目录,再hive-site.xml中,由参数hive.metastore.warehouse.dir指定.默认值为/user/hive/warehouse
- 因此hive中的数据库在hdfs上的存储路径为${hive.metastore.warehouse.dir}databasename.db
tables表
hive表语关系型数据库中的表相同.hive中的表对应的数据通常是存储在hdfs中,而表相关的元数据是存储在RDBMS中
hive中的表的数据在HDFS上的存储路径为
${hive.matastore.warehouse.dir}/database.db/tablename
partitions分区
partition分区是hive的一种优化查询手段.分区指根据分区列(如日期)的值将表划分为不同的分区.这样可以更快地对制定分区的数据进行查询
分区在存储上面的表现是table表目录下子文件夹的形式存在
一个文件夹表示一个分区.子文件命名标准:分区列=分区值
hive还支持分区下继续创建分区,所谓多重分区
分桶
bucket分桶表是hive的一种优化手段.分桶是根据表中字段(比如id)的值,经过hash计算规则将数据文件划分成指定的若干个小文件
分桶规则:hashfunc(字段)%桶个数,余数系统的分到同一个文件
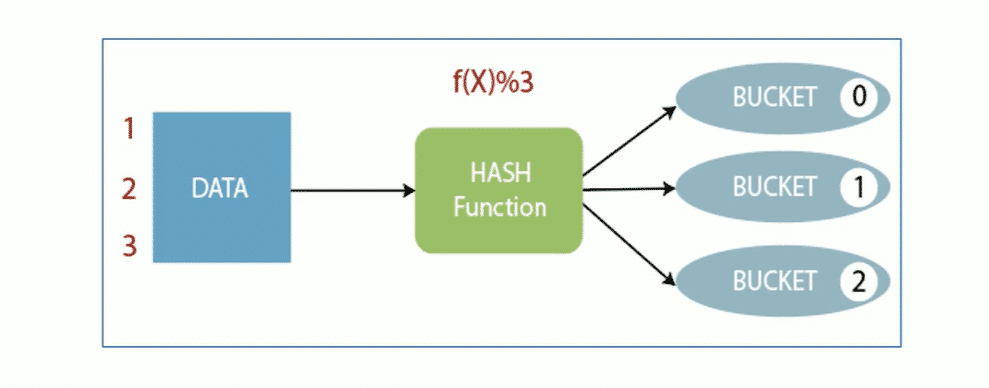
分桶的好处是可以优化join查询方便抽样查询
buket分桶在hdfs中表现为同一个目录下数据根据hash三列之后变成多个文件
元数据
元数据matadata,又称中介数据,为描述数据的数据(data about data)主要是描述数据属性的信息,用来支持指示存储位置,历史数据,资源查找,文件记录等功能
hive matadata即hive的元数据
包含用hive创建的database,table表的位置类型属性,字段顺序类型等元信息
元数据存储在关系型数据库中.如hive内置的derby,或者第三方如mysql中
hive matastore
即元数据服务,hive matastore服务的作用是管理matadata元数据,对外暴露地址,让各种客户端通过连接matastore服务,由matastore再去连接mysql数据库来存储元数据
有了matastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道mysql的用户名密码,只需要连接metastore服务即可.某种长度上也保证了hive元数据的安全
matastore服务由三种配置方式
内嵌模式,本地模式,远程模式
| 内嵌模式 | 本地模式 | 远程模式 | |
|---|---|---|---|
| metastore单独配置,启动 | 否 | 否 | 是 |
| metadata存储介质 | derby | mysql | mysql |
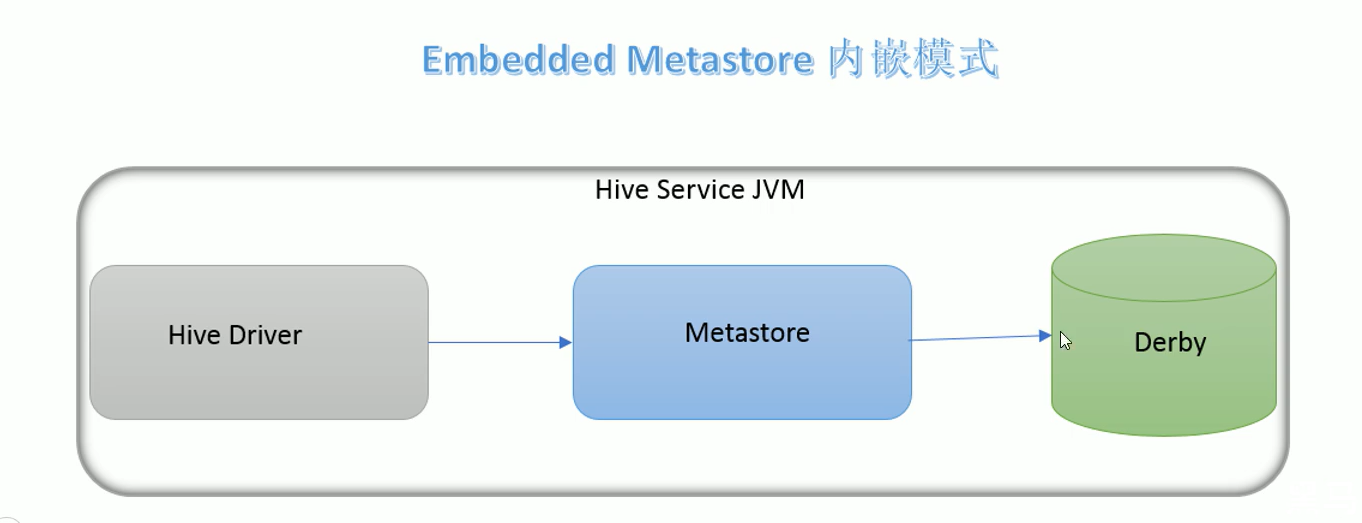
内嵌模式
内嵌模式是matastore默认的部署模式
此种模式下,元数据存储在内置的derby数据库,并且derby数据库和matastore服务都嵌入在主HiveServer进程中,当启动HiveServer进程时,Derby和matastore都会启动.不需要额外另起matastore服务
但是一次只能支持一个活动用户,适用于测试体验,不适用生产环境
本地模式
本地模式下,metastore服务于主hiveserver进程在同一进程中运行,但是存储元数据的数据库在单独的进程中运行,但是存储元数据的数据库在单独的进程中运行,并且可以在单独的主机上,matastore服务将通过JDBC于matastore数据库进行通信
本地模式采用外部数据库来存储元数据,推荐使用mysql
hive根据hive.metastore.uris参数值来判断,如果为空,则为本地模式
缺点是没启动一次hive服务都配置了一个metastore

远程模式
远程模式(Remote matastore)下,matastore在其单独的jvm上运行,而不再hiveserver的jvm中运行.如果其他进程希望与matastore服务器通信,则可以使用Thrift network api进行通信
远程模式下,需配置hive.metastore.uris参数来制定metastore服务运行的机器ip和端口,并且需要单独手动启动metastore服务.元数据采用外部数据库存储,推荐mysql
生产环境中建议用远程模式hive metastore.再这种情况下,其他依赖hive的软件都可以通过metastore访问hive.由于还可以屏蔽掉数据库层,因此带来了更好的客观理性,安全性
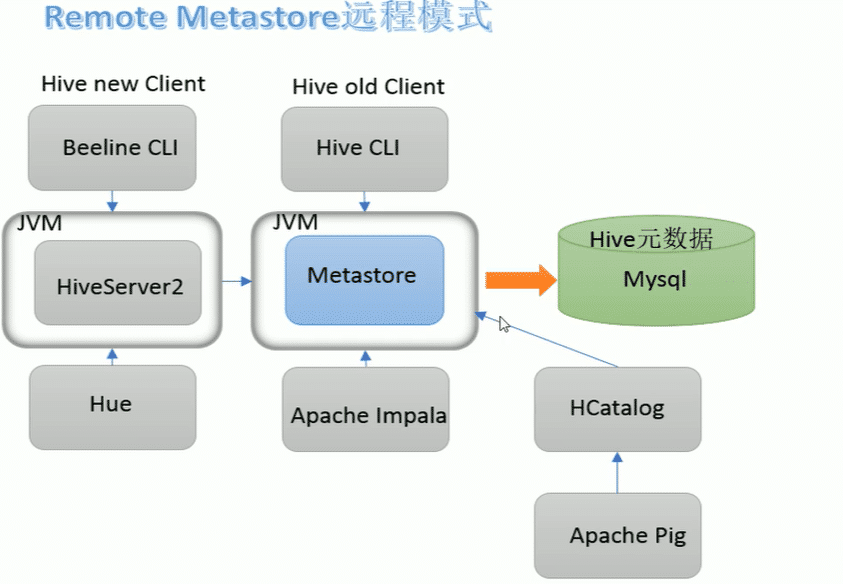
关系
hiveserver2通过matastore服务读写元数据,所以在远程模式下,启动hiveServer2之前必须先启动matastore服务
远程模式下,beeline客户端只能通过hiveserver2服务访问hive.而bin/hive是通过metastore服务访问的
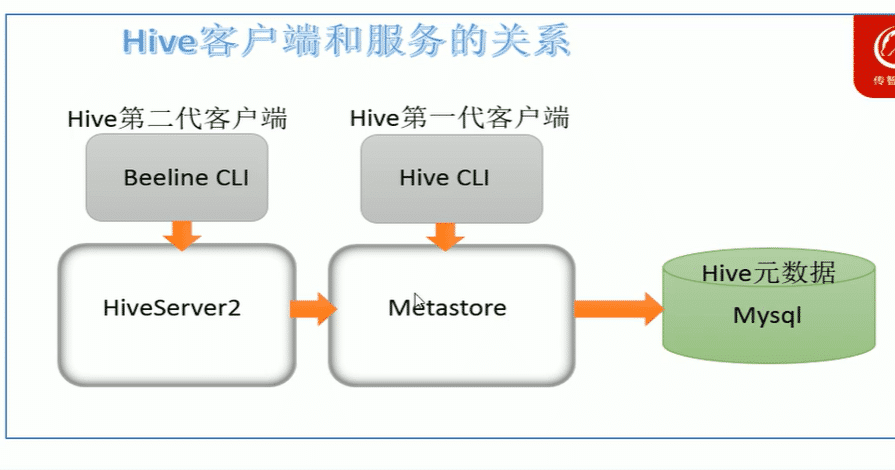
所以要先启动matastore再启动HiveServer2
使用体验
使用
再执行插入数据的时候,发现插入速度即慢,sql执行时间很长,插入一条数据30s之后才显示插入成功
- hive底层是通过mapreduce执行数据插入动作的,所以速度慢
- 如果数据量大这么一条条插入是不现实的
- hive具有自己特有的数据插入方式
如何才能将结构化数据映射为表?
想要在hive中创建表结构化文件映射成功,需要注意一下几个问题:
创建表时字段顺序,字段类型要和文件中保持一致
如果类型不一致hive会尝试转换,不保证转换成功.不成功显示null
缺点
hive底层是通过mapreduce执行引擎来处理数据的
执行完一个mapreduce程序需要的时间不短
如果是小数据集,适用hive分析将得不偿失,延迟很高
适合大数据集的分析,底层mapreduce分布式计算
文件读写机制
SerDe是Serializer,Deserializer的简称,目的是用于序列化和反序列化
序列化是对象转换成字节码的过程;反序列化是字节码转对象的过程
hive使用serDe包括FileFormat读取和写入表行对象.需要注意的是,key部分在读取时会被忽略,而在写入时key始终是常数.基本上行对象存储在value中
读取机制
首先调用inputFormat返回一条条kv键值对记录.然后调用serde的deserializer将一套记录中的value根据分隔符切分成各个字段
写文件机制
将Row写入文件时,调用SerDe(默认LazySimpleSerDe)的Serializer将对象转换成字节序列,然后调用OutputFormat将数据写入HDFS中
存储
内部表与外部表
内部表
内部版intertnal table也成为被hive拥有和管理的托管表(managed table)
默认情况下创建的表就是内部表,hive拥有该表的结构和文件.换句话说,hive完全管理表(元数据和数据)的生命周期,类似于RDBMS中的表
当删除内部表会删除数据以及表的元数据
外部表
外部表(External table)中的数据不是hive拥有或管理的,只管理表元数据的生命周期
要创建一个外部表,需要使用external语法关键字
删除外部表只会删除元数据,而不会删除实际数据,再hive外仍然可以访问实际数据
实际场景中,外部表搭配,location语法制定数据的路径,可以让数据更安全
差异
无论是内部表还是外部表,hive都在hive metastore中管理表定义,字段类型等元数据信息
分区分桶
分区
hive表对应数据量大,文件个数多时,为了避免查询时扫描全表数据,hive支持指定根据指定的字段对表进行分区,分区的字段可以是日期,地域,种类等具有标识意义的字段
比如把一年整的数据划分为12个月,后续就可以查询指定月份的数据尽可能避免了全表扫描
分桶
分桶表也叫做桶表
分桶表对应的数据文件在底层会被分解成若干份,通俗来说就是拆分成若干份独立的小文件
分桶时,要制定根据哪个字段分桶
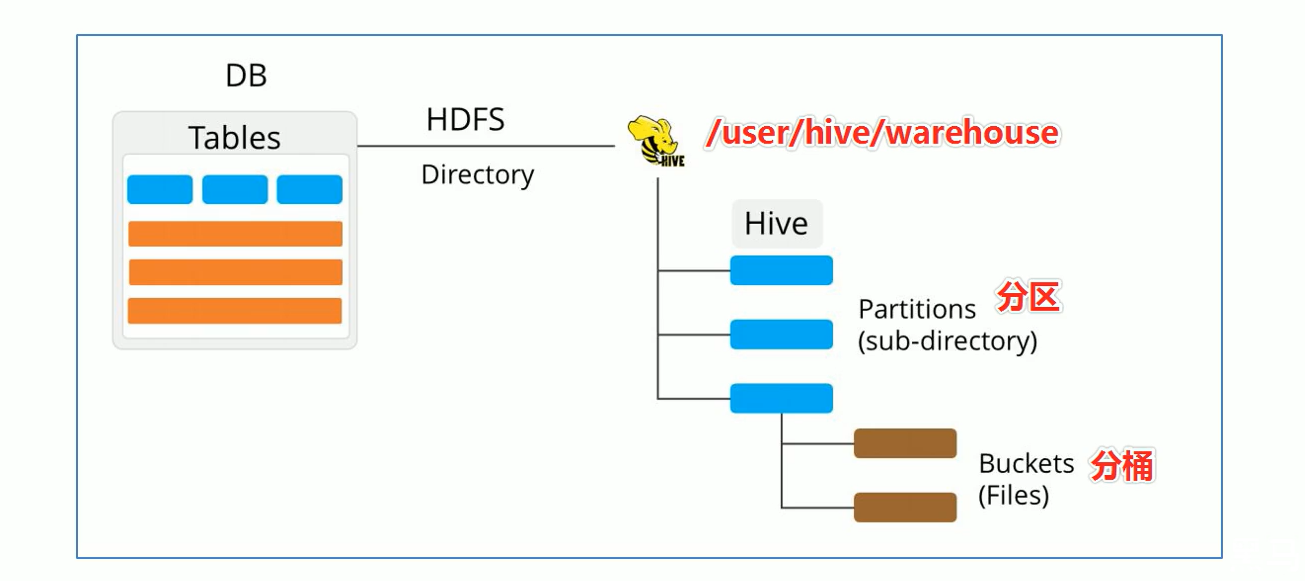
分桶规则:
编号相同的数据会被分到一个通中,具体取决于字段bucketing_column的类型
可以直接对int类型取模,或者对string的hashcode取模
查询指定分桶里面的数据,就可以查找出结果,此时是分桶扫描而不是全表扫描
事务表
hive设计之初是不支持事务的,因为hive的核心目标是将已经存在的结构化数据文件映射成为表,然后提供基于表sql分析处理,是一款面向分析的工具.并且映射的数据通常不存储在hdfs上,hdfs是不支持随机修改文件数据的
这个定位就意味着在早期的hive的sql语法中是没有update,delete操作的,也没所谓的支持事务了 ,因为都是select查询分析操作
从hive0.14版本开始具有acid语义的事务添加到hive中,以解决以下场景遇到的问题
流式传输数据
如使用apche Flume,kafka之类的根据将数据流式传输到hadoop集群中.虽然这些工具可以每秒百行或更多的行的速度写入数据,但是hive只能每隔15分钟添加一次分区.如果没分甚至每秒频繁添加分区很快会导致表中大量分区,并将许多小文件留在目录中,这将给NameNode带来压力
因此通常使用这些工具将数据流式传输到已有分区中,但这有可能会造成脏读,需要通过事务功能,允许用户获得一致性的视图避免过多小文件产生
尺寸变化缓慢
星型模式数据仓中,维度随着时间缓慢变化,例如零售商开设新商店,需要将其添加到商店表中,或者现有商店可能会更改其平方或某些其他跟踪的特征.这些更改导致都需要插入单个记录或更新单挑记录
数据重复
有时发现手机的数据不正确需要更正
局限性
虽然hive支持了acid语义的事务,但是使用起来并没有mysql中那样方便,有很多局限性.原因很简单,hive的设计目标不是为了支持事务操作,而是支持分析操作,并且最终基于hdfs的底层存储机制是的文件的增加删除操作需要懂一些小心思
- 上不支持begin ,commit和rollback 所有语言操作都是自动提交的
- 仅支持orc文件格式
- 默认情况下事务为关闭,需要配置参数开启使用
- 表必须是分桶表(Bucketed)才可以使用事务功能
- 表参数transactional必须为true
- 外部表不能成为acid表,不允许从非acid会话读取/写入acid表
物化视图
视图
hive中的视图是一种虚拟表,只保存定义不保存实际数据
通常从真实的物理表查询中创建生成视图,也可以从已存在的视图上创建新视图
创建视图时,将冻结视图的架构,如果删除或更改基础表,则视图将失败
视图是用来简化操作的,不缓冲记录,也没有提高查询性能
物化视图
物化视图是一个包括结果的数据库对象,可以用于预先计算保存表连接或聚集等耗时较多的操作结果,再执行查询时,就可以避免进行这些耗时操作,从而快速得到查询结构
物化视图的目的就是通过计算,提高查询性能,当然需要占用一定的存储空间
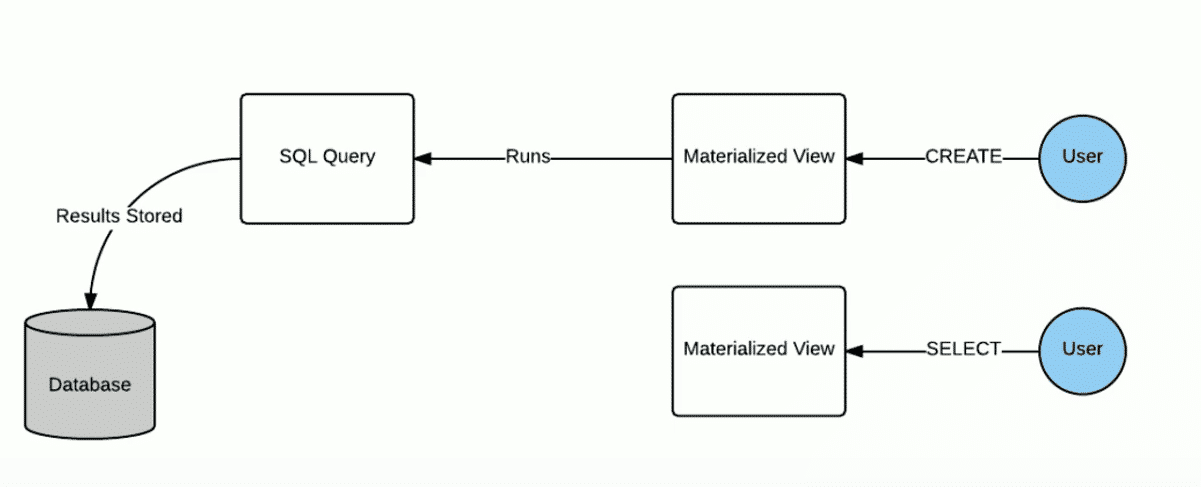
hive3.0开始引入物化视图
并提供对于物化视图的查询自动重写机制(通过apache calcite实现)
hive的物化视图还提供了物化视图存储选择机制,可以本地存储在hive,也可以通过用户自定义storage handlers存储在其他系统
hive引入物化视图就是为了优化数据查询访问效率,相当于从数据预处理的角度优化数据访问
hive从3.0丢弃了index无索引的语法支持,推荐使用物化视图和列式存储文件格式来加快查询速度
- 物化视图创建后,select查询执行数据自动落地,自动也即在query的执行期间,任何用户对该物化视图是不可见的,执行完毕后自动落地
- 默认情况下爱,创建好的物化视图可用于查询优化器optimizer查询重写,再物化视图创建期间可以通过bisable bewrite参数禁止使用
- 物化视图支持将数据存储在外部系统如druid
- 目前支持物化视图的drop和show操作,后续会增加其他操作
- 当数据变更(新数据inserted,数据修改,modified)物化视图也需要更新保证数据的一致性,目前需要用户主动触发rebuild重构
区别
视图是虚拟的逻辑存在的,只有定义存储数据
物化视图是真实的,物理存在的,里面存储着预计算的数据
物化视图能够缓存数据,再创建物化视图的时候就把数据缓存起来了,hive把物化视图当成一张表,将数据缓存,而视图只是一个虚表,只有表结构,没有数据,实际查询的时候再去写sql访问实际的数据表
视图的目的是简化降低查询的复杂度,而物化视图的目的是提高查询性能
materialized view物化视图
物化视图创建后即可用于相关查询的加速 ,即用户提交查询query,若该query经过重写后可以命中已经存在的物化视图,则直接通过物化视图查询数据返回结果
是否重写差U型你使用物化视图可以通过全局参数控制默认为true
用户可以选择性的控制指定的物化视图查询重写机制