故障恢复
简介
大量mysql主从出现故障,HA可用性切换能达到小时级
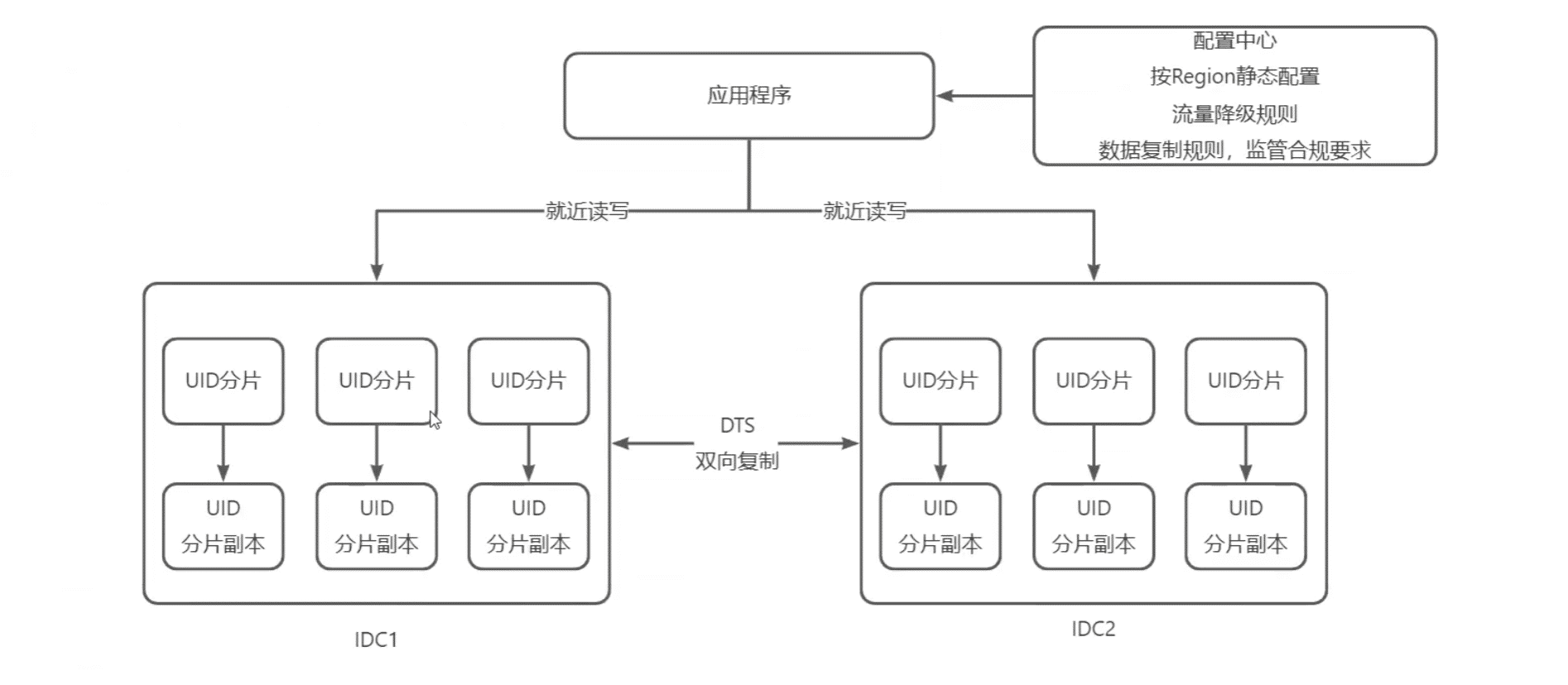
京东的DTS服务实现数据双向复制,就近读写,IDC内部CP方案MGR(mysql Group Replication组复制)
机房级别AP方案,异构双向互通
问什么不用mysql自带的主从模式实现同步
- 同步不可控
- 难以扩展
- CP模型效率低,AP模型难以保障一致性
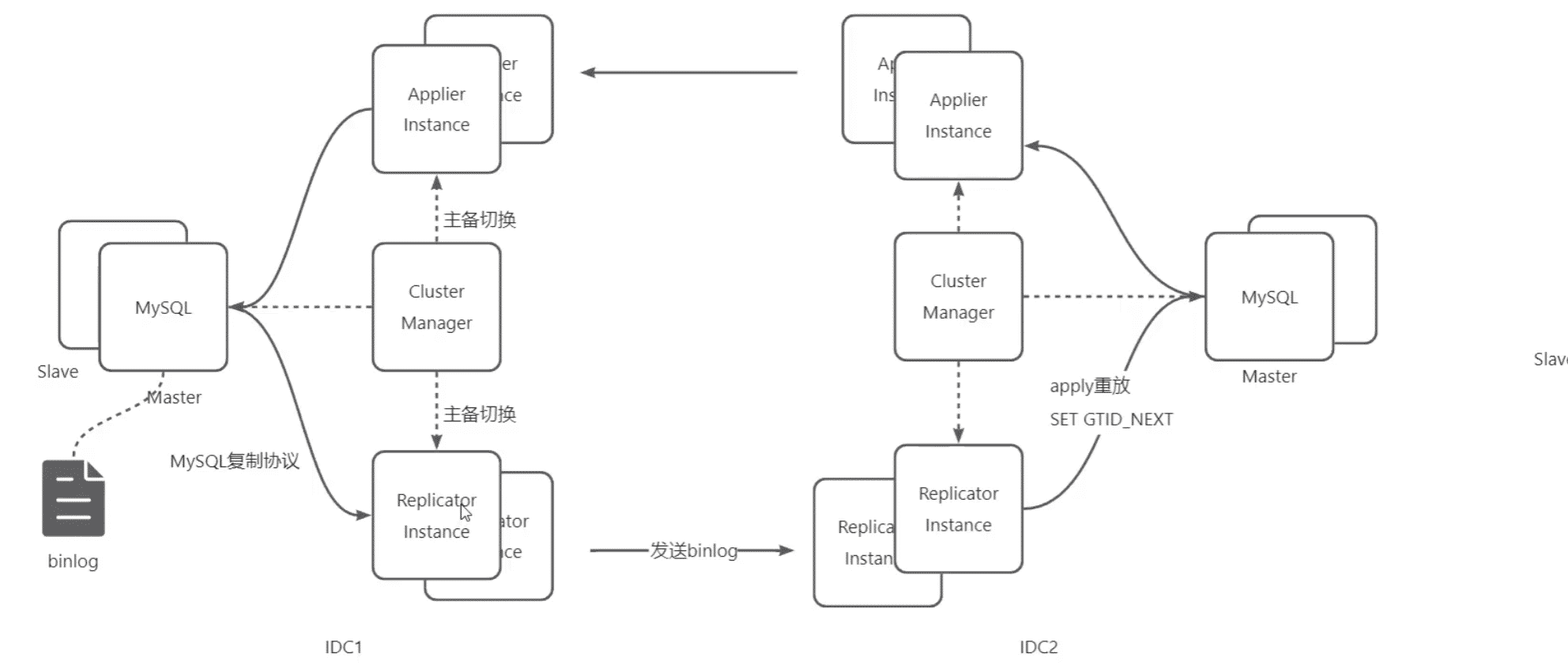
DTS技术架构
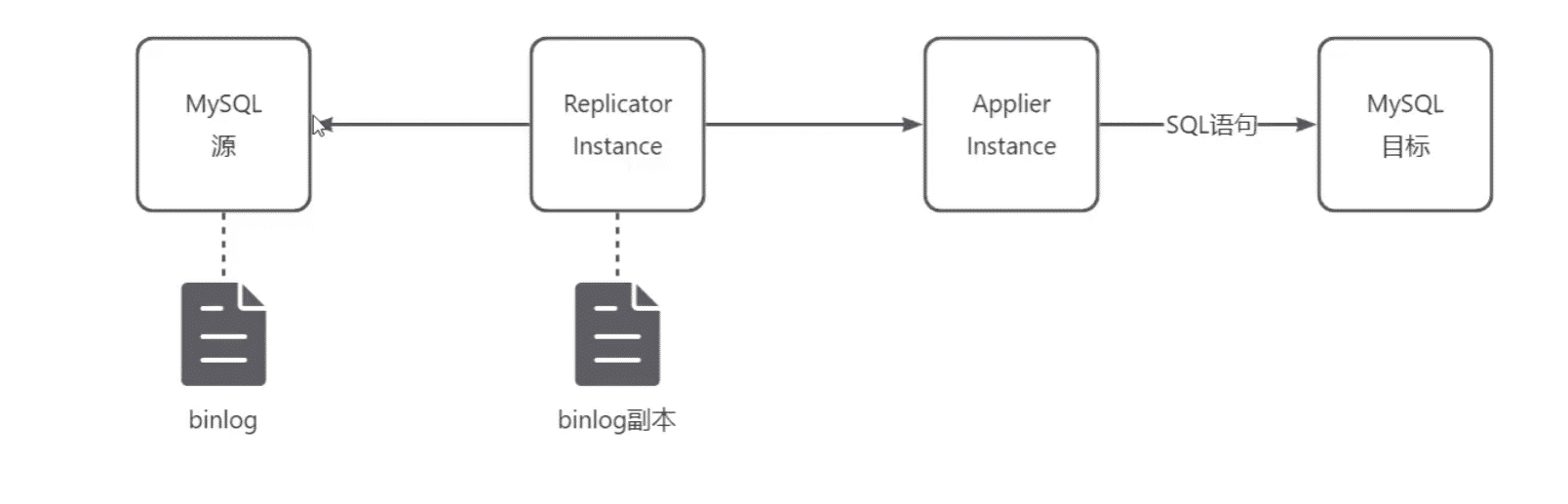
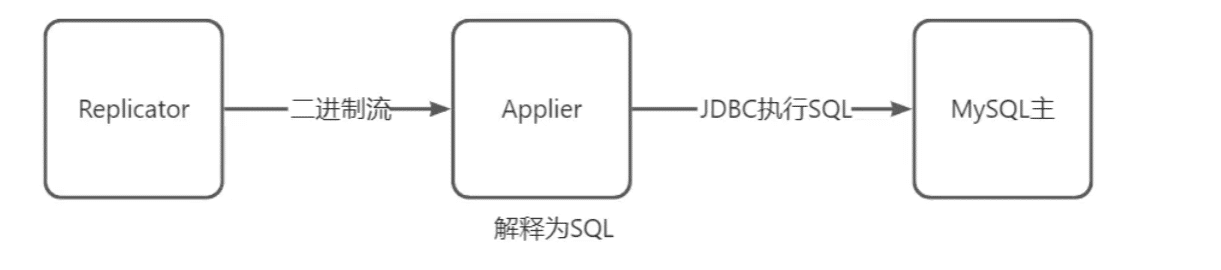
Replicator:拉取Binlog
Applier:解析binlog,复制到对端生成 SLQ
ClusterManager:负责集群Replicator/Applier可用性
问题
复制延迟,要求异构机房1S内完成数据同步
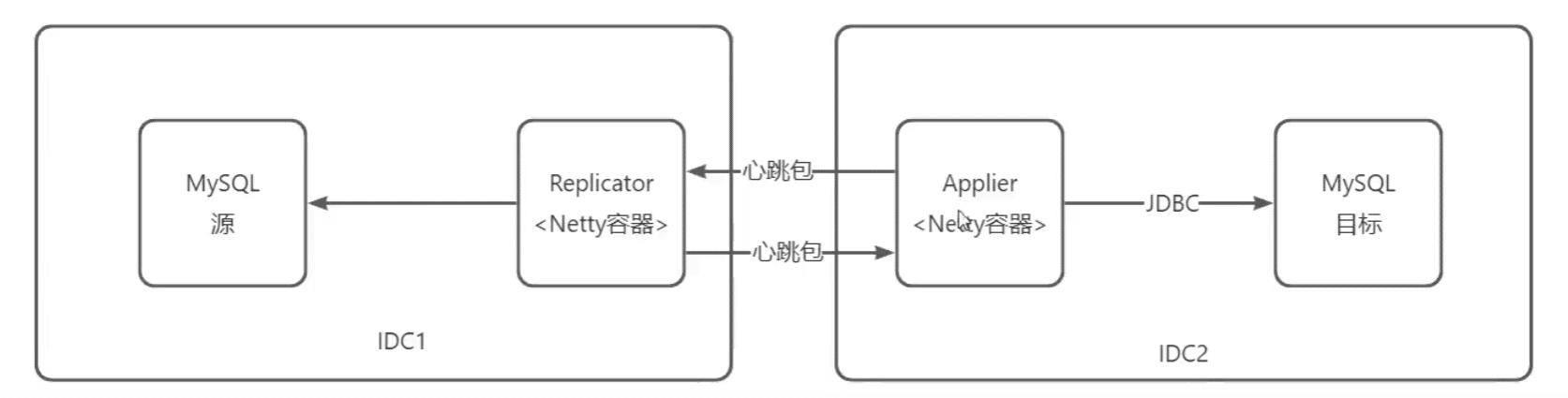
网络故障
通过netty NIO做心跳机制健康检查,3S发一个心跳包,连续三次心跳丢失断开重连
Replicator 高效处理IO
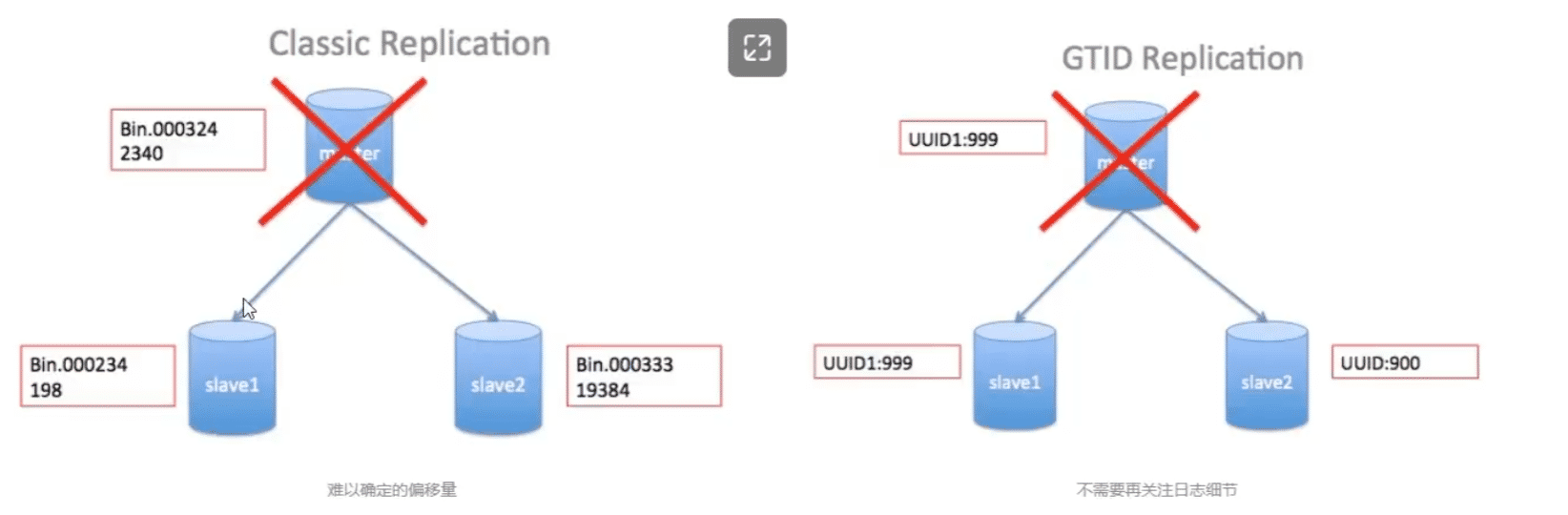
基于GTID实现复制
- 简化复制逻辑:GTID笑出了基于文件名和位置的复制拓扑管理。每个事务都有唯一的标识符,可以方便地跟踪和管理进行复制,而无需关注具体的文件和位置
- 简化故障服务:当主从复制中断或发生故障时,GTID可以更容易地进行故障恢复。通过记录已经执行的GTID集,可以准确确定从服务器复制的位置,并从断点处继续复制,而无需手动处理日志
- 避免重复复制:GTID可以确保服务器不会复制重复的事务。每个事务都有唯一标识符,从服务器可以轻易判断是否已经复制过该事物
当数据从底层设备读取到内核缓冲区时,操作系统会将数据复制到Direct ByteBuffer中
FileChannel提供了map()方法,该方法可以在一个打开的文件和MappedByteBuffer之间建立一个虚拟内存映射
binLog落盘:利用OSPageCache做文件写缓存,再通过异步线程做刷盘处理。过程如果OS宕机PageCache丢失也没问题,Replicator会通过源binlog从gtid set重新拉取即可
用java NIO进行零拷贝
接收端
解释SQL占用大量CPU,必须要进行限流防止任务积压。市场价限流8000
动态关闭autoread选项,内存属于处于低水位,自动开启,高水位自动关闭释放内存占用
mysql的autored时一个针对服务器参数的选项,用于控制mysql服务器在执行写操作(插入,更新,删除)后是否自动执行读操作5.x默认开启,8.x默认关闭
简单来说就是修改后写入查询缓存
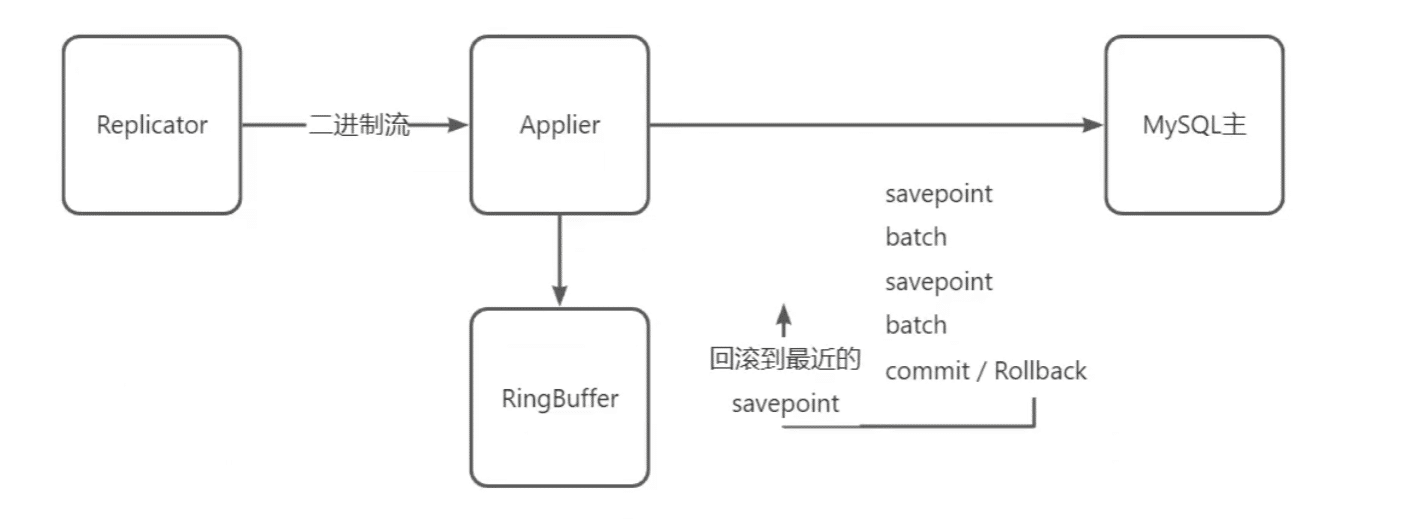
大事物的解决办法
RingBuffer固定存储1024个Event,按1024个Event切割为多个子事物,rollback,rollback也是回退到最近的savepoint,后尝试重做,如果所有均完成最终commit提交
数据一致性
主键冲突问题:应用分布式主键如snowFlack,生成全局唯一的分布式Id。禁用自增主键,因为可能会产生主键冲突问题
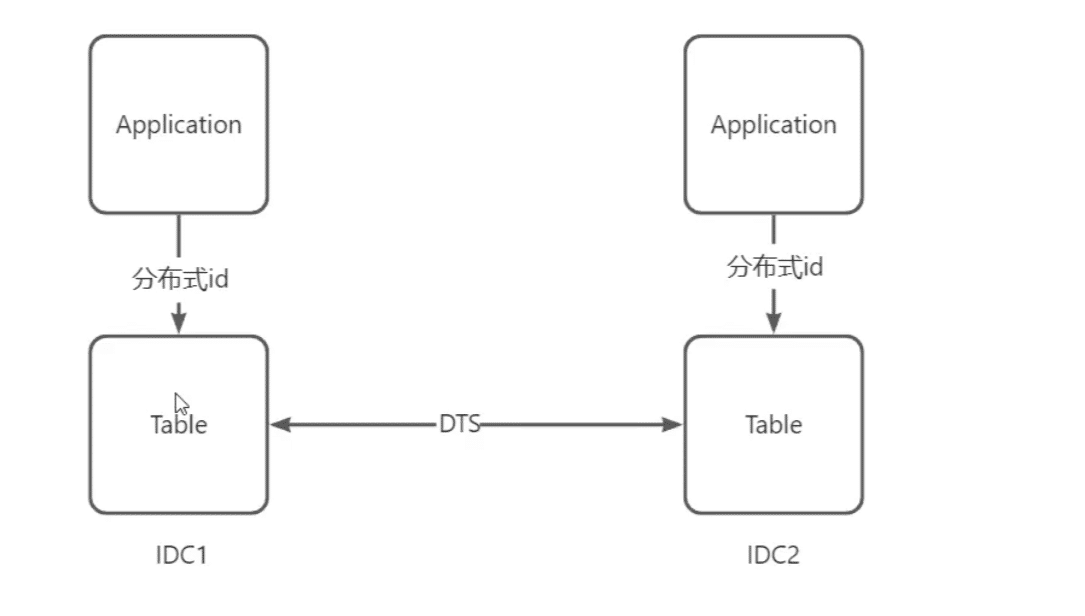
多机房对同一条数据做修改
尽量避免此类问题产生,采用hash稳定路由到同一个数据节点
业务改造:每张表增加last_update_time字段,以最新数据为准
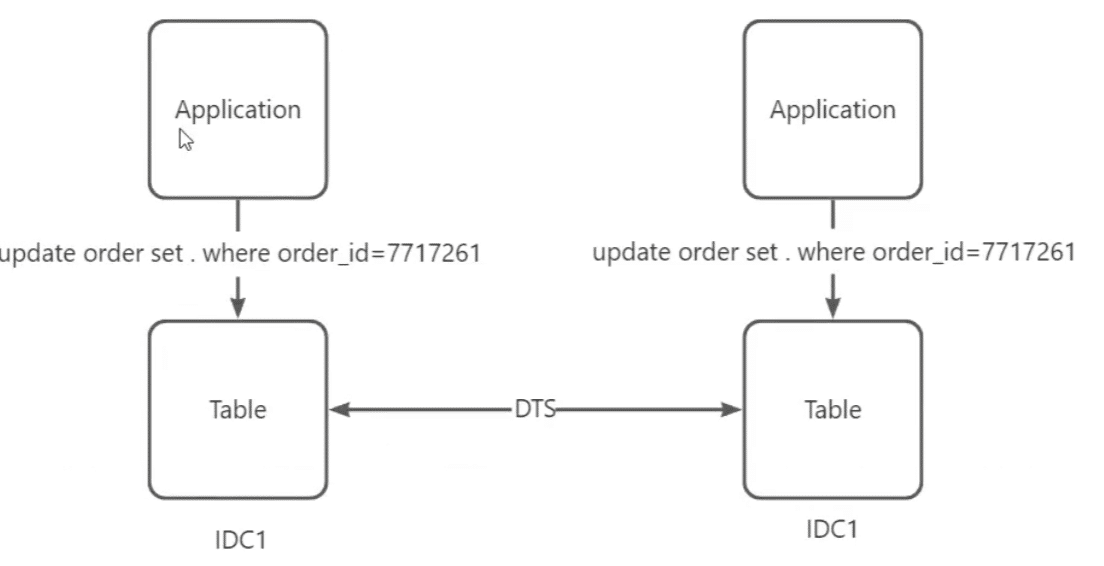
DDL数据一致性
binlog异步发送后,如何对比新旧表是否一致
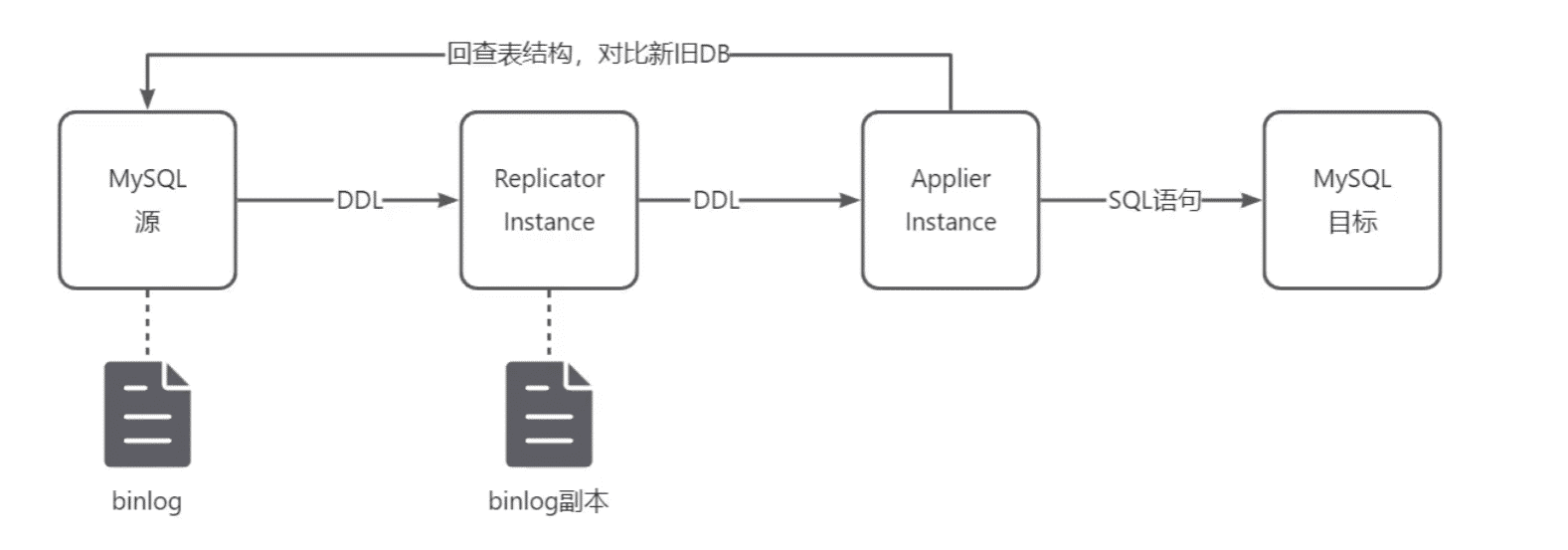
Appier消费速率不匹配,如Applier应用DDL期间,Mysql原又调整了3次结构,会导致回查不一致
在Repicator内置一个嵌入式mysql,只存储schama与表结构,不存数据,遇到DDL后应用,保证同IDC中一致,然后将embd-mysql的结构镜像写入到binlog,构建DDL快照,像Applier发送,Applier应用DDL后,在目标的MYSQL对比前后表结构是否一致
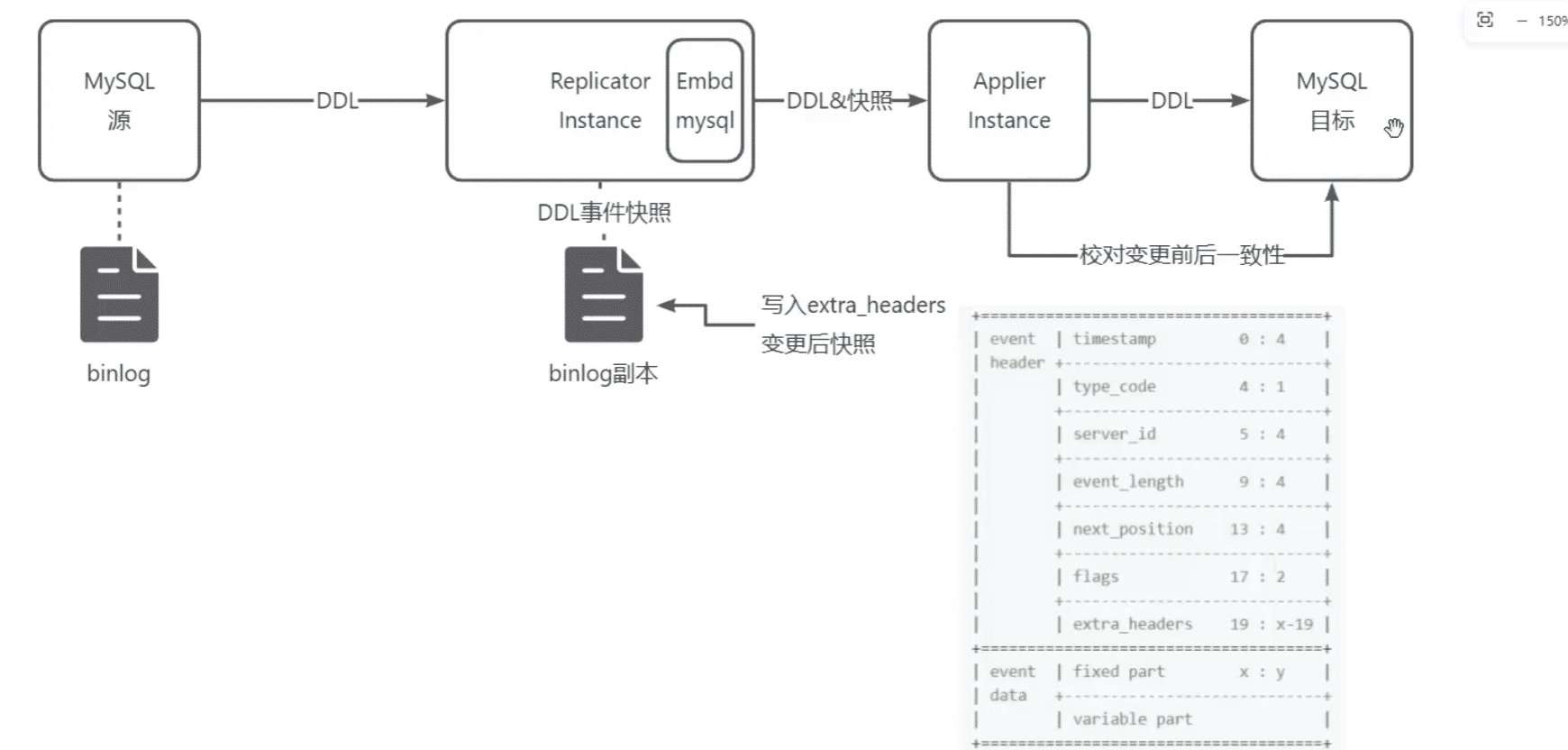
数据一致性
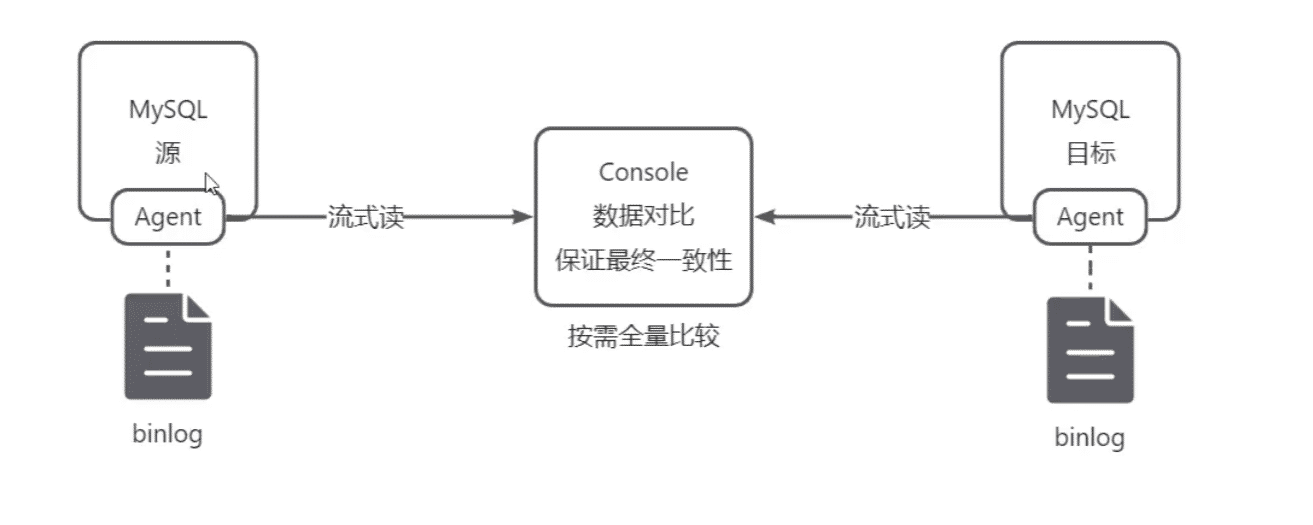
目标java Agent定时轮询,binlog推送至Console,Console根据GTID做事件对比,因为binlog是时序的,俩端binlog对其后对比效率极高
同城多活
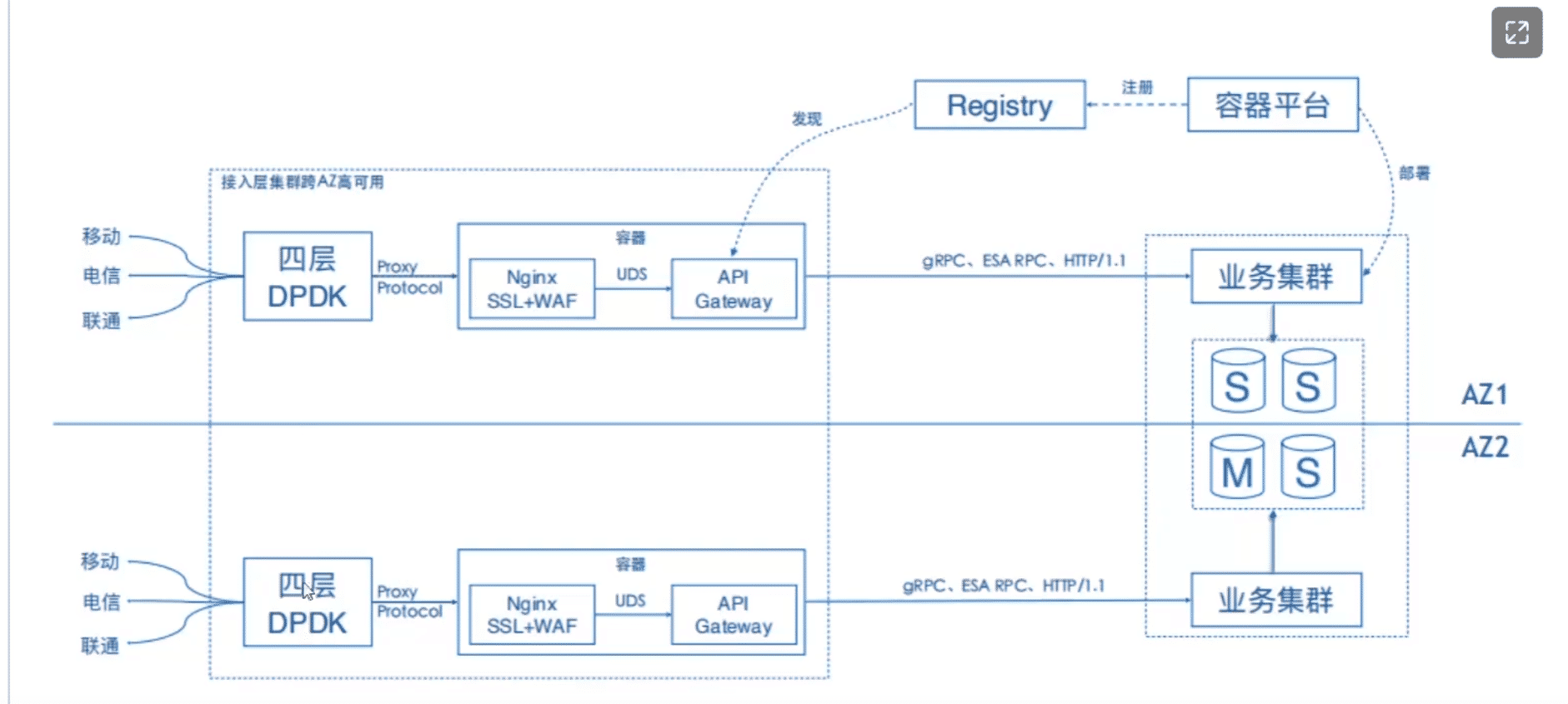
两地 = 本地 + 异地
三中心 = 本地中心 + 本地容灾中心 +异地备份中心
主备数据中心之间一般有热备、冷备、双活三种备份方式。
热备的情况下,只有主数据中心承担用户的业务,在不停机情况下对主数据中心进行备份。
冷备的情况下,也是只有主数据中心承担业务,在停机情况下对主数据中心进行备份。
双活是觉得备用数据中心只做备份太浪费了,所以让主备两个数据中心都同时承担用户的业务,此时,主备两个数据中心互为备份,并且进行实时备份。一般来说,主数据中心的负载可能会多一些,比如分担60~70%的业务,备数据中心只分担40%~30%的业务 。