高可用系统设计
简介
什么是高可用?可用性的判断标准是啥?
高可用描述的是一个系统在大部分时间都是可用的,可以为我们提供服务的。高可用代表系统即使在发生硬件故障或者系统升级的时候,服务仍然是可用的。
一般情况下,我们使用多少个 9 来评判一个系统的可用性,比如 99.9999% 就是代表该系统在所有的运行时间中只有 0.0001% 的时间是不可用的,这样的系统就是非常非常高可用的了!当然,也会有系统如果可用性不太好的话,可能连 9 都上不了。
除此之外,系统的可用性还可以用某功能的失败次数与总的请求次数之比来衡量,比如对网站请求 1000 次,其中有 10 次请求失败,那么可用性就是 99%。
冗余设计
对于服务器来说,冗余的思想就是相同的服务部署多份,如果正在使用的服务突然挂掉的话,系统可以很快切换到服务上,大大减少系统不可用时间
对于数据来说,冗余的思想就是相同的数据备份多份,这样就可以很简单地提高数据的安全性。
实际上,日常生活中就有非常多的冗余思想的应用。
拿我自己来说,我对于重要文件的保存方法就是冗余思想的应用。我日常所使用的重要文件都会同步一份在 Github 以及个人云盘上,这样就可以保证即使电脑硬盘损坏,我也可以通过 Github 或者个人云盘找回自己的重要文件。
高可用集群(High Availability Cluster,简称 HA Cluster)、同城灾备、异地灾备、同城多活和异地多活是冗余思想在高可用系统设计中最典型的应用。
高可用集群 : 同一份服务部署两份或者多份,当正在使用的服务突然挂掉的话,可以切换到另外一台服务,从而保证服务的高可用。
同城灾备 :一整个集群可以部署在同一个机房,而同城灾备中相同服务部署在同一个城市的不同机房中。并且,备用服务不处理请求。这样可以避免机房出现意外情况比如停电、火灾。
异地灾备 :类似于同城灾备,不同的是,相同服务部署在异地(通常距离较远,甚至是在不同的城市或者国家)的不同机房中
同城多活 :类似于同城灾备,但备用服务可以处理请求,这样可以充分利用系统资源,提高系统的并发。
异地多活 : 将服务部署在异地的不同机房中,并且,它们可以同时对外提供服务。
高可用集群单纯是服务的冗余,并没有强调地域。同城灾备、异地灾备、同城多活和异地多活实现了地域上的冗余。
同城和异地的主要区别在于机房之间的距离。异地通常距离较远,甚至是在不同的城市或者国家。
和传统的灾备设计相比,同城多活和异地多活最明显的改变在于“多活”,即所有站点都是同时在对外提供服务的。异地多活是为了应对突发状况比如火灾、地震等自然或者人为灾害。
光做好冗余还不够,必须配合上故障转移才可以!所谓故障转移,简单来说就是实现不可用服务快速且自动地切换到可用服务,整个过程不需要人为干涉
举个例子:哨兵模式的 Redis 集群中,如果 Sentinel(哨兵) 检测到 master 节点出现故障的话, 它就会帮助我们实现故障转移,自动将某一台 slave 升级为 master,确保整个 Redis 系统的可用性。整个过程完全自动,不需要人工介入。
再举个例子:Nginx 可以结合 Keepalived 来实现高可用。如果 Nginx 主服务器宕机的话,Keepalived 可以自动进行故障转移,备用 Nginx 主服务器升级为主服务。并且,这个切换对外是透明的,因为使用的虚拟 IP,虚拟 IP 不会改变。
服务限流
针对软件系统来说,限流就是对请求的速率进行限制,避免瞬时的大量请求击垮软件系统。毕竟,软件系统的处理能力是有限的。如果说超过了其处理能力的范围,软件系统可能直接就挂掉了。
限流可能会导致用户的请求无法被正确处理,不过,这往往也是权衡了软件系统的稳定性之后得到的最优解。
现实生活中,处处都有限流的实际应用,就比如排队买票是为了避免大量用户涌入购票而导致售票员无法处理。
常见的限流算法
固定窗口计数算法
固定窗口其实就是时间窗口,固定窗口计数算法规定了我们单位时间处理的请求数量
假如我们规定某个接口一分钟只能访问33次的话,使用固定窗口计数算法的实现思路如下
给定一个变量 counter 来记录当前接口处理的请求数量,初始值为 0(代表接口当前 1 分钟内还未处理请求)。
1 分钟之内每处理一个请求之后就将 counter+1 ,当 counter=33 之后(也就是说在这 1 分钟内接口已经被访问 33 次的话),后续的请求就会被全部拒绝。
等到 1 分钟结束后,将 counter 重置 0,重新开始计数。
这种限流算法无法保证限流速率,因而无法保证突然激增的流量。
就比如说我们限制某个接口 1 分钟只能访问 1000 次,该接口的 QPS 为 500,前 55s 这个接口 1 个请求没有接收,后 1s 突然接收了 1000 个请求。然后,在当前场景下,这 1000 个请求在 1s 内是没办法被处理的,系统直接就被瞬时的大量请求给击垮了。
滑动窗口计数器算法
滑动窗口计数器算法 算的上是固定窗口计数器算法的升级版。
滑动窗口计数器算法相比于固定窗口计数器算法的优化在于:它把时间以一定比例分片 。
例如我们的接口限流每分钟处理 60 个请求,我们可以把 1 分钟分为 60 个窗口。每隔 1 秒移动一次,每个窗口一秒只能处理 不大于 60(请求数)/60(窗口数) 的请求, 如果当前窗口的请求计数总和超过了限制的数量的话就不再处理其他请求。
很显然, 当滑动窗口的格子划分的越多,滑动窗口的滚动就越平滑,限流的统计就会越精确。
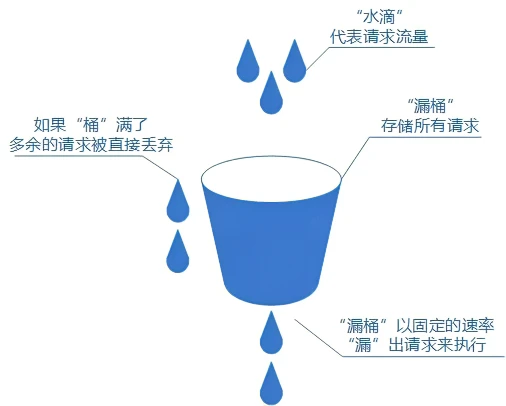
漏桶算法
我们可以把发请求的动作比作成注水到桶中,我们处理请求的过程可以比喻为漏桶漏水。我们往桶中以任意速率流入水,以一定速率流出水。当水超过桶流量则丢弃,因为桶容量是不变的,保证了整体的速率。
如果想要实现这个算法的话也很简单,准备一个队列用来保存请求,然后我们定期从队列中拿请求来执行就好了(和消息队列削峰/限流的思想是一样的)。
令牌桶算法
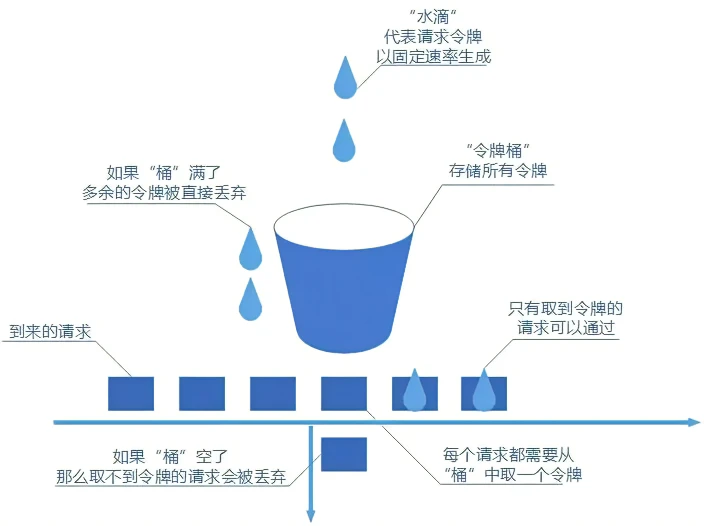
令牌桶算法也比较简单。和漏桶算法算法一样,我们的主角还是桶(这限流算法和桶过不去啊)。不过现在桶里装的是令牌了,请求在被处理之前需要拿到一个令牌,请求处理完毕之后将这个令牌丢弃(删除)。我们根据限流大小,按照一定的速率往桶里添加令牌。如果桶装满了,就不能继续往里面继续添加令牌了。
超时设置
由于网络问题、系统或者服务内部的 Bug、服务器宕机、操作系统崩溃等问题的不确定性,我们的系统或者服务永远不可能保证时刻都是可用的状态。
为了最大限度的减小系统或者服务出现故障之后带来的影响,我们需要用到的 超时(Timeout) 和 重试(Retry) 机制。
想要把超时和重试机制讲清楚其实很简单,因为它俩本身就不是什么高深的概念。
虽然超时和重试机制的思想很简单,但是它俩是真的非常实用。你平时接触到的绝大部分涉及到远程调用的系统或者服务都会应用超时和重试机制。尤其是对于微服务系统来说,正确设置超时和重试非常重要。单体服务通常只涉及数据库、缓存、第三方 API、中间件等的网络调用,而微服务系统内部各个服务之间还存在着网络调用。
超时机制
超时机制说的是当一个请求超过指定的时间比如1S.还没有被处理的话,这个请求就会直接被取消抛出指定的异常或者错误
我们平时接触到的超时可以简单分为俩种:
- 连接超时(ConnectTimeout)客户端与服务端建立的最长等待时间
- 读取超时(ReadTimeout):客户端和服务器端已经建立连接,客户端等待服务器端处理完请求的最长时间.实际项目中,我们关注比较多的还是读取超时
如果没有设置超时的话,就看会导致服务端连接数爆炸大量请求堆积的问题.
这些堆积的链接和请求都会消耗系统资源,影响新接收到的请求.严重的情况下,甚至会拖垮整个系统或者服务.
我之前在实际项目就遇到过类似的问题,整个网站无法正常处理请求,服务器负载直接快被拉满。后面发现原因是项目超时设置错误加上客户端请求处理异常,导致服务端连接数直接接近 40w+,这么多堆积的连接直接把系统干趴了。
超时时间应该如何设置?
超时到底设置多长时间是一个难题!超时值设置太高或者太低都有风险。如果设置太高的话,会降低超时机制的有效性,比如你设置超时为 10s 的话,那设置超时就没啥意义了,系统依然可能会出现大量慢请求堆积的问题。如果设置太低的话,就可能会导致在系统或者服务在某些处理请求速度变慢的情况下(比如请求突然增多),大量请求重试(超时通常会结合重试)继续加重系统或者服务的压力,进而导致整个系统或者服务被拖垮的问题。
通常情况下,我们建议读取超时设置为 1500ms ,这是一个比较普适的值。如果你的系统或者服务对于延迟比较敏感的话,那读取超时值可以适当在 1500ms 的基础上进行缩短。反之,读取超时值也可以在 1500ms 的基础上进行加长,不过,尽量还是不要超过 1500ms 。连接超时可以适当设置长一些,建议在 1000ms ~ 5000ms 之内。
没有银弹!超时值具体该设置多大,还是要根据实际项目的需求和情况慢慢调整优化得到。
重试机制
什么是重试机制
重试机制一般配合超机制一起使用,指的是多次发送相同的请求来避免瞬态故障和偶然性故障.
瞬态故障可以简单理解为某一瞬间系统偶然出现的故障,并不会持久。偶然性故障可以理解为哪些在某些情况下偶尔出现的故障,频率通常较低。
重试的核心思想是通过消耗服务器的资源来尽可能获得请求更大概率被成功处理。由于瞬态故障和偶然性故障是很少发生的,因此,重试对于服务器的资源消耗几乎是可以被忽略的.
重试的次数如何设置?
重试的次数不宜过多,否则依然会对系统负载造成比较大的压力。
重试的次数通常建议设为 3 次。并且,我们通常还会设置重试的间隔,比如说我们要重试 3 次的话,第 1 次请求失败后,等待 1 秒再进行重试,第 2 次请求失败后,等待 2 秒再进行重试,第 3 次请求失败后,等待 3 秒再进行重试。
重试幂等
超时和重试机制在实际项目中使用的话,需要注意保证同一个请求没有被多次执行。
什么情况下会出现一个请求被多次执行呢?客户端等待服务端完成请求完成超时但此时服务端已经执行了请求,只是由于短暂的网络波动导致响应在发送给客户端的过程中延迟了。
举个例子:用户支付购买某个课程,结果用户支付的请求由于重试的问题导致用户购买同一门课程支付了两次。对于这种情况,我们在执行用户购买课程的请求的时候需要判断一下用户是否已经购买过。这样的话,就不会因为重试的问题导致重复购买了。