Sharding Sphere
简介
apache ShardingSphere 是一套开源分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC,Sharding-Proxy和Sharding-Sidercar(规划中)
这三款互相独立,却又能够混合部署配合使用的产品组成.它们提供标准化的分片数据,分布式事务和数据库治理功能,可适用于java同构,异构语言等各种多样化应用场景.
shardingsphere定位为关系型数据库中间件,目的是充分合理的在分布式场景下利用关系型数据库的计算存储能力,而非实现一个全新的关系型数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架
Sharding JDBC
- 适用于任何基于JDBC的ORM框架,如JPA,Mybatis,SpringJDBC Template,或者直接使用JDBC
- 支持任何第三方数据库连接池如DBCP,C3PO,Druid,等
- 支持任意实现JDBC规范的数据库比如Mysql,Oracle,SqlSErver,Pgsql以及遵循SQL92标准的数据库
sharding-proxy
定位为透明化的数据库代理端,提供了封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持.目前提供mysql/PostgreSql版本,它可以使用任何兼容Mysql/PostgreSql协议访问客户端(如,Mysql Command Client,Mysql WorkBeanch,navicat等)操作数据库,对DBA更加友好
- 向应用程序完全透明,可以直接当做Mysql/PostSql使用
- 适用于任何兼容Mysql/PostgreSql协议的客户端
分库分表
拿商品查询的案例举例子
垂直分表
用户在列表中查看商品的时候,通常是不会显示商品信息的,只有感兴趣才会点击去访问商品详情,因此商品信息中商品具体内容访问频次较低,占用空间较大,可以将商品信息独立存放一张表,访问频次较高的基本信息单独放在一张表中
讲一个字段按照字段分成多表,每个表存储其中一部分字段
水平分表
单品表存商品存储问题超出了预估,这时候可以尝试水平分表将ID为单数的和双数的Id的用户放在俩个表中
垂直分库
磁盘空间不够的时候,由于商品信息与商品描述耦合度较高,因此放在一个数据库,而店铺信息相对独立,因此被单独存放在另一个数据库中.
垂直分库通过将表按照业务分类,然后分布在不同的数据库,并且可以将这些数据库部署在不同的服务器上,达到多个服务器共同分担压力的效果
水平分库
单品库存商品存储问题超出了预估,这时候可以尝试水平分表将ID为单数的和双数的Id的用户放在俩个表中,与水平分表类似
真正分表比较少,大部分都是分库,分表大多数情况下可以用分区来代替
场景与问题
在数据库设计时,就要考虑到分库分表
随着数据库数据量增加,不要考虑马上做水平切分,首先考虑缓存处理,读写分离,使用索引等等方式,如果这些方式不能根本解决问题,再去考虑做分库分表
问题:
- 跨节点连接查询问题
- 多数据源管理问题
Sharding JDBC
实例
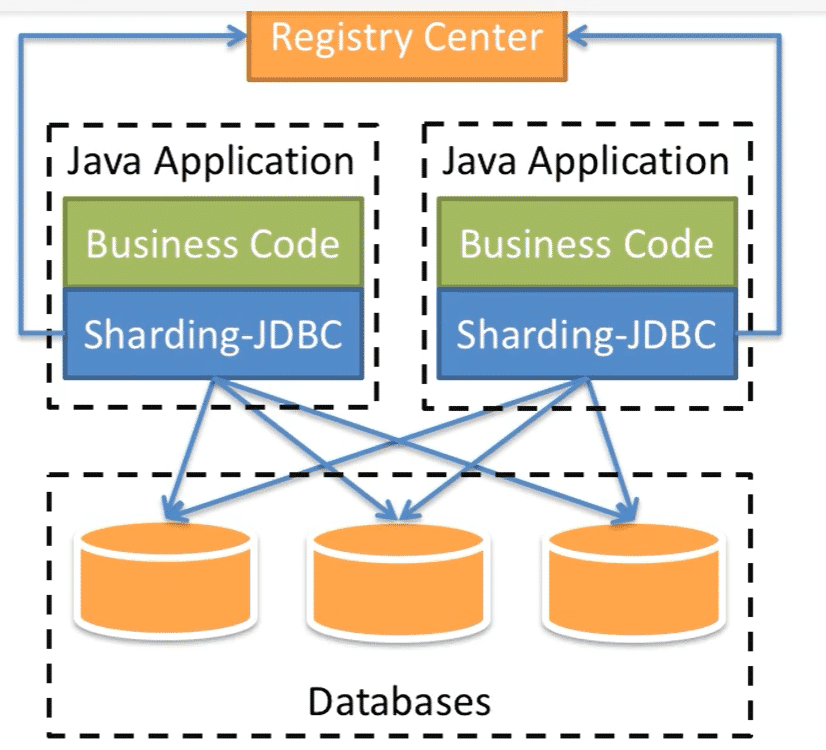
Sharding Jdbc并不是做分库分表
主要做的是俩个功能:数据分片(也叫水平分表)和读写分离
主要目的是:简化对分库分表之后数据相关的操作
#一个实体类对应俩张表
spring.main. allow-bean-definition-overriding=true
#配置数据源,给数据源起名
spring.shardingsphere.datasource.names=ds-0,ds-1
#配置数据源具体内容,包含连接池,驱动,地址,用户名密码
spring.shardingsphere.datasource.ds-0.jdbc-url=jdbc:mysql://localhost:3306/demo_ds_0?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.ds-0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds-0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds-0.username=root
spring.shardingsphere.datasource.ds-0.password=
spring.shardingsphere.datasource.ds-1.jdbc-url=jdbc:mysql://localhost:3306/demo_ds_1?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8
spring.shardingsphere.datasource.ds-1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds-1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds-1.username=root
spring.shardingsphere.datasource.ds-1.password=
#指定表的分布情况,配置表在哪个数据库里面,表名称都是什么
#t_order代表的是表名称,行表达式可以使用${...}或者$->{...}但前者与 Spring 本身的属性文件占位符冲突,因此在 Spring 环境中使用行表达式标识符建议使用$->{...},以下就代表了俩张表ds_1与ds_2库下的t_oder_1和t_order_2这几张表
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=ds-$->{0..1}.t_order_$->{0..1}
#指定course表里主键生成策略
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.column=order_id #主键名称
spring.shardingsphere.rules.sharding.tables.t_order.key-generate-strategy.key-generator-name=snowflake #雪花算法
#指定分片策略 ,order_id为主键,根据奇数偶数像其中加数据
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_id
spring.shardingsphere.rules.sharding.sharding-algorithms.database-inline.props.algorithm-expression=ds-$->{user_id % 2}以下是官网解释
spring.shardingsphere.datasource.names= # 省略数据源配置,请参考使用手册
# 标准分片表配置
spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes= # 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况
# 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
# 用于单分片键的标准分片场景
spring.shardingsphere.rules.sharding.tables.<table-name>.database-strategy.standard.sharding-column= # 分片列名称
spring.shardingsphere.rules.sharding.tables.<table-name>.database-strategy.standard.sharding-algorithm-name= # 分片算法名称
# 用于多分片键的复合分片场景
spring.shardingsphere.rules.sharding.tables.<table-name>.database-strategy.complex.sharding-columns= # 分片列名称,多个列以逗号分隔
spring.shardingsphere.rules.sharding.tables.<table-name>.database-strategy.complex.sharding-algorithm-name= # 分片算法名称
# 用于 Hint 的分片策略
spring.shardingsphere.rules.sharding.tables.<table-name>.database-strategy.hint.sharding-algorithm-name= # 分片算法名称
# 分表策略,同分库策略
spring.shardingsphere.rules.sharding.tables.<table-name>.table-strategy.xxx= # 省略
# 自动分片表配置
spring.shardingsphere.rules.sharding.auto-tables.<auto-table-name>.actual-data-sources= # 数据源名
spring.shardingsphere.rules.sharding.auto-tables.<auto-table-name>.sharding-strategy.standard.sharding-column= # 分片列名称
spring.shardingsphere.rules.sharding.auto-tables.<auto-table-name>.sharding-strategy.standard.sharding-algorithm-name= # 自动分片算法名称
# 分布式序列策略配置
spring.shardingsphere.rules.sharding.tables.<table-name>.key-generate-strategy.column= # 分布式序列列名称
spring.shardingsphere.rules.sharding.tables.<table-name>.key-generate-strategy.key-generator-name= # 分布式序列算法名称
spring.shardingsphere.rules.sharding.binding-tables[0]= # 绑定表规则列表
spring.shardingsphere.rules.sharding.binding-tables[1]= # 绑定表规则列表
spring.shardingsphere.rules.sharding.binding-tables[x]= # 绑定表规则列表
spring.shardingsphere.rules.sharding.broadcast-tables[0]= # 广播表规则列表
spring.shardingsphere.rules.sharding.broadcast-tables[1]= # 广播表规则列表
spring.shardingsphere.rules.sharding.broadcast-tables[x]= # 广播表规则列表
spring.shardingsphere.rules.sharding.default-database-strategy.xxx= # 默认数据库分片策略
spring.shardingsphere.rules.sharding.default-table-strategy.xxx= # 默认表分片策略
spring.shardingsphere.rules.sharding.default-key-generate-strategy.xxx= # 默认分布式序列策略
spring.shardingsphere.rules.sharding.default-sharding-column= # 默认分片列名称
# 分片算法配置
spring.shardingsphere.rules.sharding.sharding-algorithms.<sharding-algorithm-name>.type= # 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.<sharding-algorithm-name>.props.xxx= # 分片算法属性配置
# 分布式序列算法配置
spring.shardingsphere.rules.sharding.key-generators.<key-generate-algorithm-name>.type= # 分布式序列算法类型
spring.shardingsphere.rules.sharding.key-generators.<key-generate-algorithm-name>.props.xxx= # 分布式序列算法属性配置分片策略
分片策略包含分片键和分片算法,由于分片算法的独立性,讲其独立抽离.真正可用于分片操作的是分片键+分片算法,也就是分片策略.目前提供五种分片策略
标准分片策略
对应StandardShardingStrategy。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。RangeShardingAlgorithm是可选的,用于处理BETWEEN AND, >, <, >=, <=分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
复合分片
对应ComplexShardingStrategy。复合分片策略。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
表达式分片
对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: t_user_$->{u_id % 8} 表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7。
Hint
对应HintShardingStrategy。通过Hint指定分片值而非从SQL中提取分片值的方式进行分片的策略。
不分片策略
对应NoneShardingStrategy。不分片的策略
Sharding-Proxy
定位为透明的数据库代理端,提供了封装二进制协议的服务端版本,用于完成对异构语言的支持
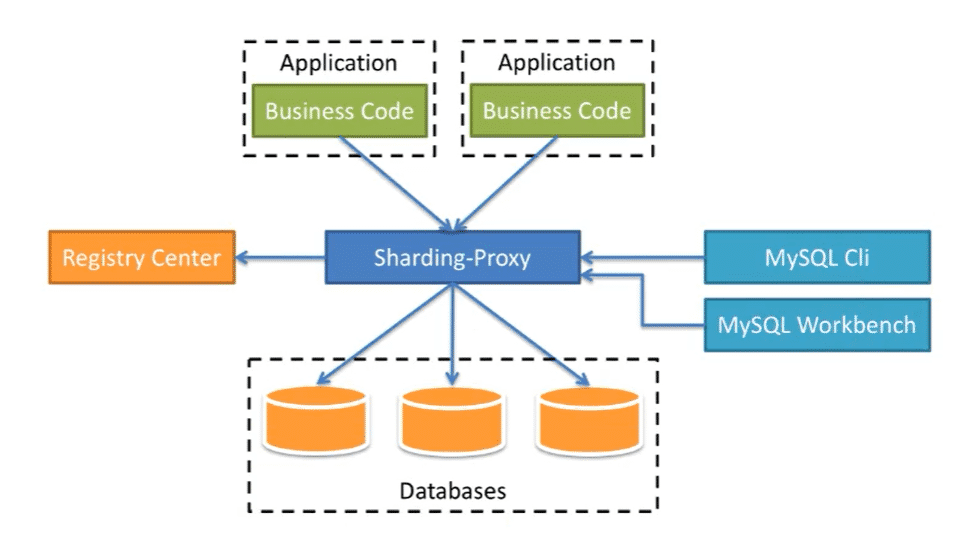
独立使用sharding-Proxy独立应用,使用安装服务,进行分库分表或者读写分离配置,启动使用
server.yaml
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
######################################################################################################
# 如果你想使用mysql,要复制驱动到目录中
# If you want to configure orchestration, authorization and proxy properties, please refer to this file.
#
######################################################################################################
#
#orchestration:
# name: orchestration_ds
# overwrite: true
# registry:
# type: zookeeper
# serverLists: localhost:2181
# namespace: orchestration
#
authentication:
users:
root:
password: root
sharding:
password: sharding
authorizedSchemas: sharding_db
props:
max.connections.size.per.query: 1
acceptor.size: 16 # The default value is available processors count * 2.
executor.size: 16 # Infinite by default.
proxy.frontend.flush.threshold: 128 # The default value is 128.
# LOCAL: Proxy will run with LOCAL transaction.
# XA: Proxy will run with XA transaction.
# BASE: Proxy will run with B.A.S.E transaction.
proxy.transaction.type: LOCAL
proxy.opentracing.enabled: false
query.with.cipher.column: true
sql.show: false
打开最下面的注释
如果你想使用mysql,要复制驱动到lib目录中
在bin目录下运行start,默认端口号3307
打开cmd窗口连接Sharding-Proxy,连接方式和连接mysql一样
分库
配置在cnfig下的config-sharding文件
创建数据库后,会自动根据配置的规则生成多个库和表