LSM树
简介
Log Stuctured Merge Tree(结构化合并树)简称sm.目前LSM被很多存储产品作为存储结构,比如Apache HBASE,Apache Cassandra,MongoDB
简单地说,LSM的设计目的是提供比传统B+树更好的写性能.LSM通过将磁盘的随机写转化为顺序写来提高性能,而付出的代价就是牺牲部分读性能,写放大(B+树同样也有写放大的问题)LSM
LSM存储引擎
和B树存储引擎一样,同样支持增、删、读、改、顺序扫描操作。而且通过批量存储技术规避磁盘随机写入问题。当然凡事有利有弊,LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。
LSM树的思想非常朴素,就是将堆数据的修改增量保持在内存中,达到指定大小限制后,将这些操作批量写入磁盘(由此提升了写性能),是一种基于硬盘的数据结构,与B-tree相比,能显著地减少硬盘磁盘臂的开销.读取时需要合并磁盘中历史数据和内存汇总最近的修改操作,读取时可能需要先看是否命中内存,否则需要访问较多的磁盘文件(存储在磁盘中的是许多小批量数据,由此降低了部分读性能.但是磁盘中会定期做merge操作,合并成一颗大树,以优化读性能).LSM树的优势在于有效规避了磁盘随机写入的问题,但读取时可能需要访问较多的磁盘文件
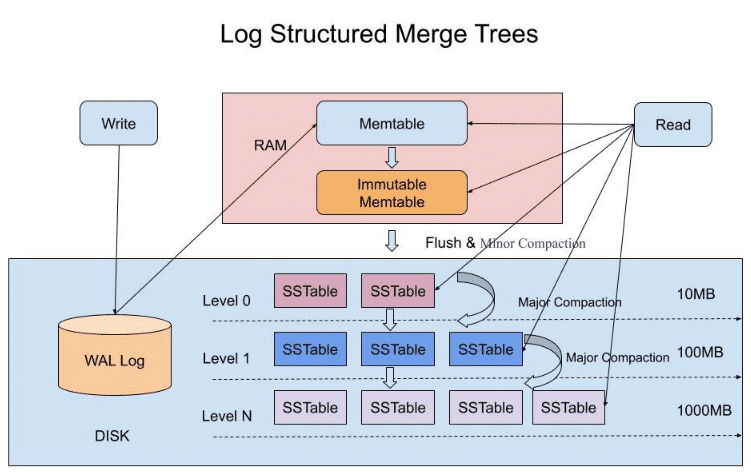
LSM tree核心特点
将索引分为内存和磁盘俩部分,并在内存达到阈值时启动树合并(Merge Trees)
用批量写入代替随机写入,并且用预写日志WAL技术(ElasticSerach中为translog事务日志)保证内存数据,在系统崩溃后可以被恢复
数据采取类似日志追加的方式写入Log Structured磁盘,一顺序写的方式提高效率
ES中的segment写入机制
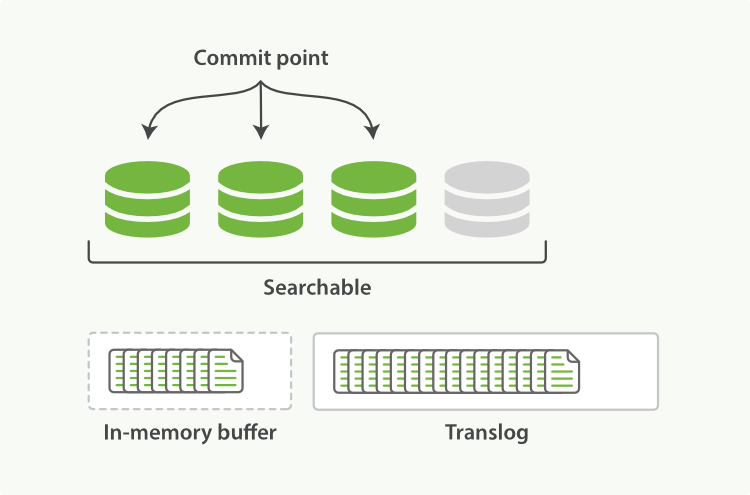
一个文档被索引之后,就会被添加到内存缓冲区,并且追加到了translog中。
索引分片(shard)每秒被刷新(refresh)一次:
这些在内存缓冲区的文档被写入到一个新的段中,且没有进行 fsync 操作。
这个段被打开,使其可被搜索。
内存缓冲区被清空。
Segment在被refresh之前,数据保存在内存中,是不可被搜索的,这也就是为什么 ES 被称为提供近实时而非实时查询的原因。
这个进程继续工作,更多的文档被添加到内存缓冲区和追加到事务日志
每隔一段时间,例如 translog 变得越来越大,索引被刷新(flush);一个新的 translog 被创建,并且一个全量提交被执行:
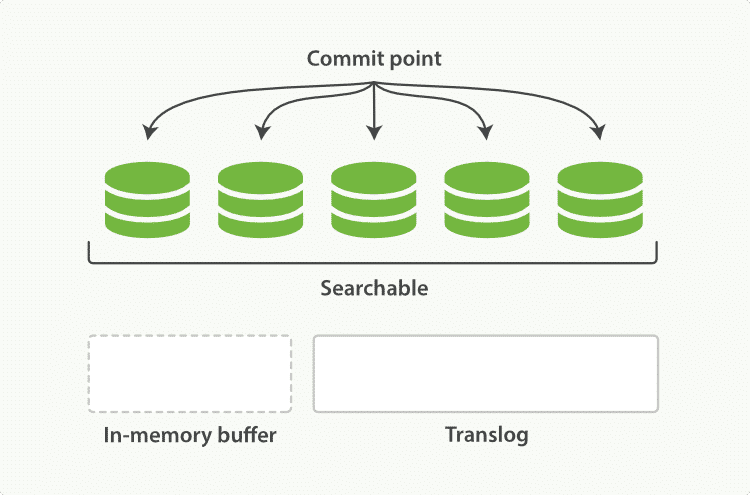
所有在内存缓冲区的文档都被写入一个新的段。
缓冲区被清空。
一个提交点被写入硬盘。
文件系统缓存通过 fsync 被刷新(flush)。
老的 translog 被删除。
数据先写入到内存中,通过定时refresh机制写入到一个segment中,ES后台会进行segment merge(段合并)操作,将多个小的segment合并大的segment。
如上这种机制避免了随机写,数据写入都是 Batch 和 Append,能达到很高的吞吐量。同时为了提高写入的效率,利用了文件缓存系统和内存来加速写入时的性能,并使用translog日志来防止数据的丢失。
对比LSM,ES的这种segment分段写,再合并的机制,和LSM的思想是一致的。
结构
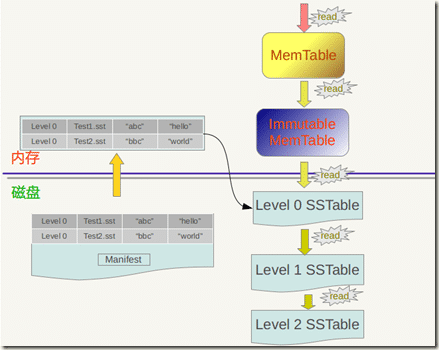
MemTable
memTable是在内存中的数据结构,用于保存最近更新的数据,会按照Key有序组织这些数据,LSM对于具体如何组织有序的数据并没有明确的定义(如常用的红黑树,跳表等).
因为数据暂时保存在内存中,内存并不是可靠存储,如果断电会丢失数据,因此通常会通过WAL(Write-ahead-logging,预写日志)的方式来保证数据的可靠性
immutable MemTable
当MemTable达到一定大小后悔转换成Immutable MemTable.Immutable MemTable是将MemTable变为SSTable的一种中间状态,它其实就相当于一个只读的MemTable,不在允许数据写入,因此写操作由心的MemTable处理
Immutable MemTable不会无限占用内存,在后台有一个线程不断地将ImmutableMemTable复制到磁盘文件中,然后释放内存,而这些写入的磁盘文件,其实就是SSTABLE
WAL
从前面我们看到,MemTable和Immutable memTable都存储在内存当中,如果机器断电或者服务器崩溃,这是不就导致数据永久丢失了吗?为了解决这个问题,LSM引入了WAL(write Ahead Log,预写日志技术)
WAL的核心就是预先将数据写入Log文件进行备份,同时在处理完成后生成检查点,确保数据不会丢失.其核心流程如下
- 内存中的程序在处理数据时,会先将数据的修改醉卧一条记录,顺序写入磁盘的log文件作为备份
- 系统周期性检查内存中的数据是否被处理完,并生成对应的checkPoint(检查点)记录在磁盘中
- 当系统崩溃重启时,我们只需要从磁盘中读取出检查点,就知道最后一次成功处理的数据在log文件中的位置.紧接着我们需要把这个位置之后的未被处理的数据从log文件中读取到内存中即可
SSTable
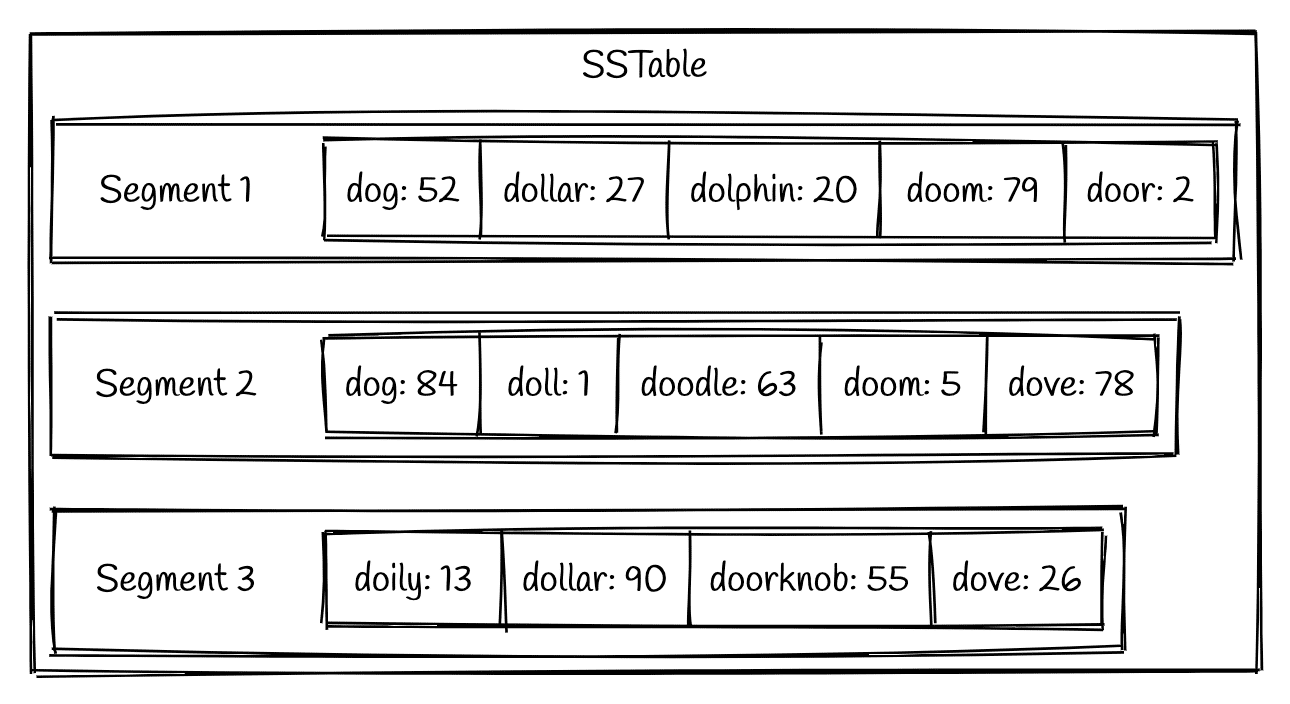
immutable memTable持久化到硬盘上之后的机构称为Sorted Strings Table(SSTable).顾名思义SStable保存了排序后的数据(实际上是按照key排序的key-value对).
每个SSTable可以包含多个存储的文件,称为segment,每个segment内部都是有序的,但不同的segment之间没有顺序关系,一个segment一旦生成便不再修改(immutable)
介绍完了LSM的核心组成后,下面来看看如何利用这些结构来完成高性能的写入,查询合并.
核心流程
写入
LSM之所以具有那么高的写性能,原因就是俩点 1.顺序写,2.批量写
由于外部的数据是无序到来,为确保顺序写入,LSM会在内存中利用Metable(红黑树,跳表)来维护数,确保数据的有序,同时为了减少随机写入的次数,其不会每次都降数据写入到磁盘中,而是当memtable的数据量达到一定阈值后,将其转换为immutable memTable的同事会触发其flush操作,将所有排好序的数据一次性,批量顺序写入磁盘中,生成一个segment
查询数据
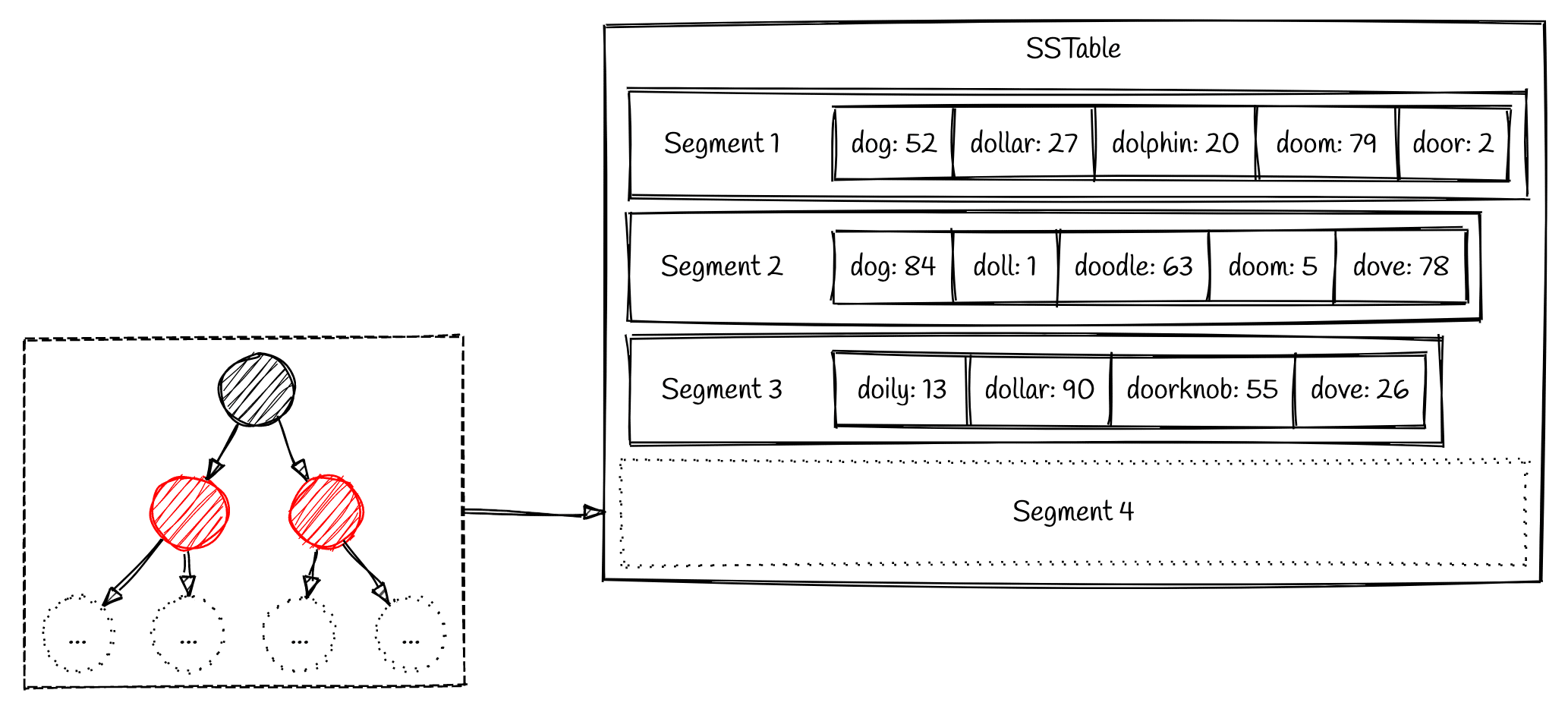
LSM在查找数据是采用的是分层查找的逻辑
- 首先去内存中查找MemTable和immutableMemTable
- 然后按照顺序在磁盘的每一层SSTable文件中去找(从最新层开始找,越是最近的数据越可能被用户查询)
- 如果SSTable添加了布隆过滤器索引,则在布隆过滤器中查找key是否存在,由于布隆过滤器具有假阳性,只要找不到,就说明当前SSTable不存在该数据,直接跳过,减少不必要的磁盘扫描
- 由于SSTable本身是有序的,为了避免全表扫描,通过稀疏索引读入内存中,录用二分查找来快速定位key在哪一块数据中,最终只需要读取指定偏移量的数据就可以获取最终结果
段合并(Compaction)
随着数据的不断写入,SSTable中会产生越来越多的segment,每一个segment都会消耗文件句柄,内存和cpu的运行周期.更重要的是,每个查询请求必须轮流检查每个segment,所以段越多,查询也就越慢.
为了解决这个问题,LSM引入了Compaction机制,会定期执行合并逻辑,将多个segment合并为一个较大的segment,同时由于每个segment中的数据是有序的,因此只需要通过归并排序的逻辑,就可以高效完成合并
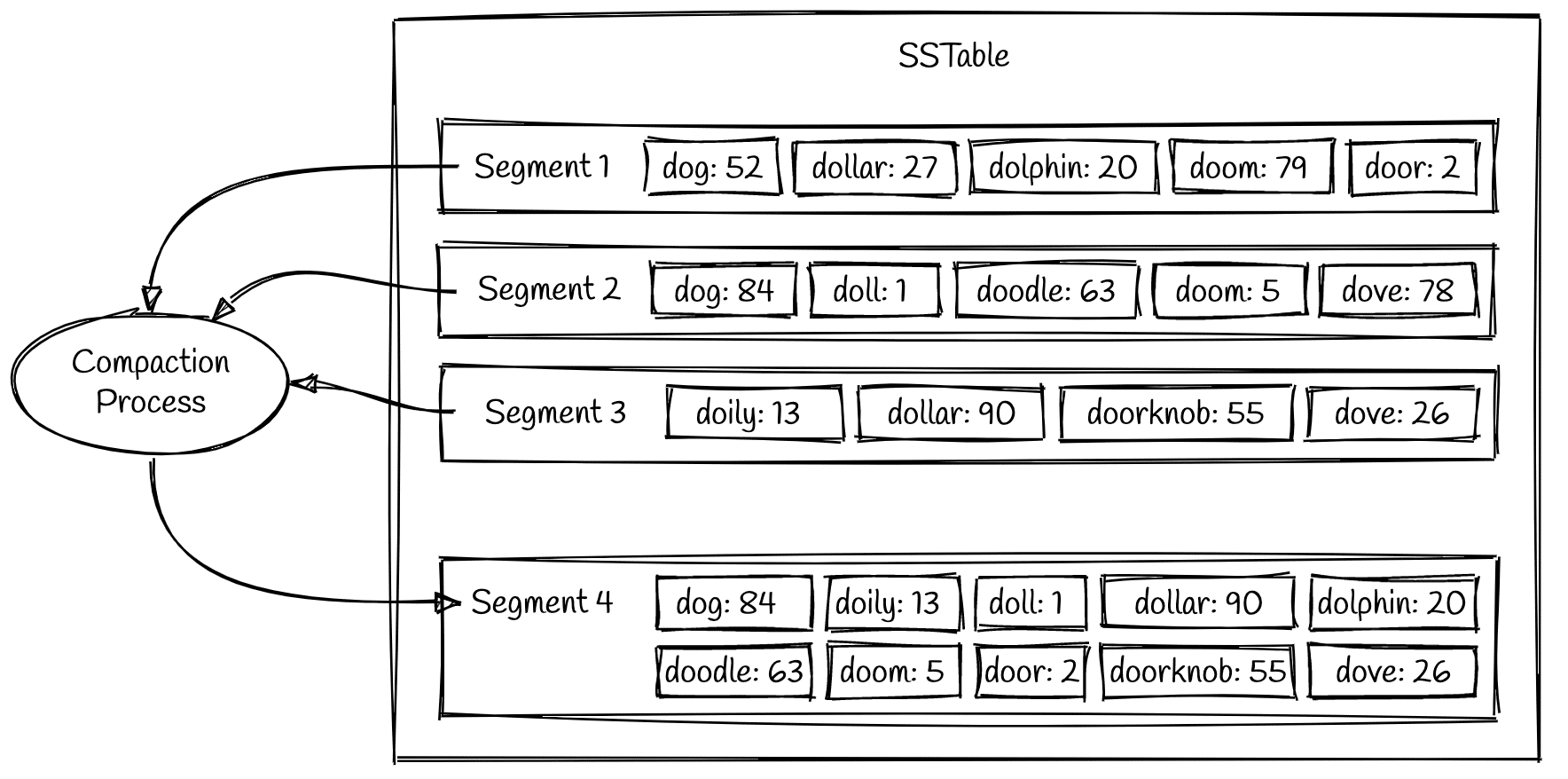
在Compaction的过程中,在之前标记为删除的数据不会被写入新的segment中,且在合并结束后,所有旧的sement的数据将从硬盘上被彻底删除掉
对比
| 区别 | LSM-Tree | B+ Teee |
|---|---|---|
| 应用场景 | K-V数据库、日志数据库(频繁写) | 关系型数据库(频繁读) |
| 写入性能 | 批量顺序写,且采用追加写(不需更新),写入性能高 | 单条随机写入,且索引需要更新,写入性能低 |
| 查找性能 | 存在读放大,查询性能低O(N),经过索引、缓存优化后可以O(LogN) | 查找性能极高,O(LogN) |
| 删除与修改 | 追加写入,标记删除,在compaction阶段才能真正删除 | 原地更新与删除 |
| 存储方式 | 内存+硬盘 | 硬盘 |