agent学习笔记
https://xiaolinnote.com/ai/agent/
ageng是什么?
agent本质是是一个能自主完成目标的AI系统,和传统AI核心区别在于自主性和能行动。
普通语言模型在被训练完毕之后知识就被冻结。本质上就是一个文字输出器。 并且每次都会忘记之前做过什么。
感知->规划->行动->再感知。
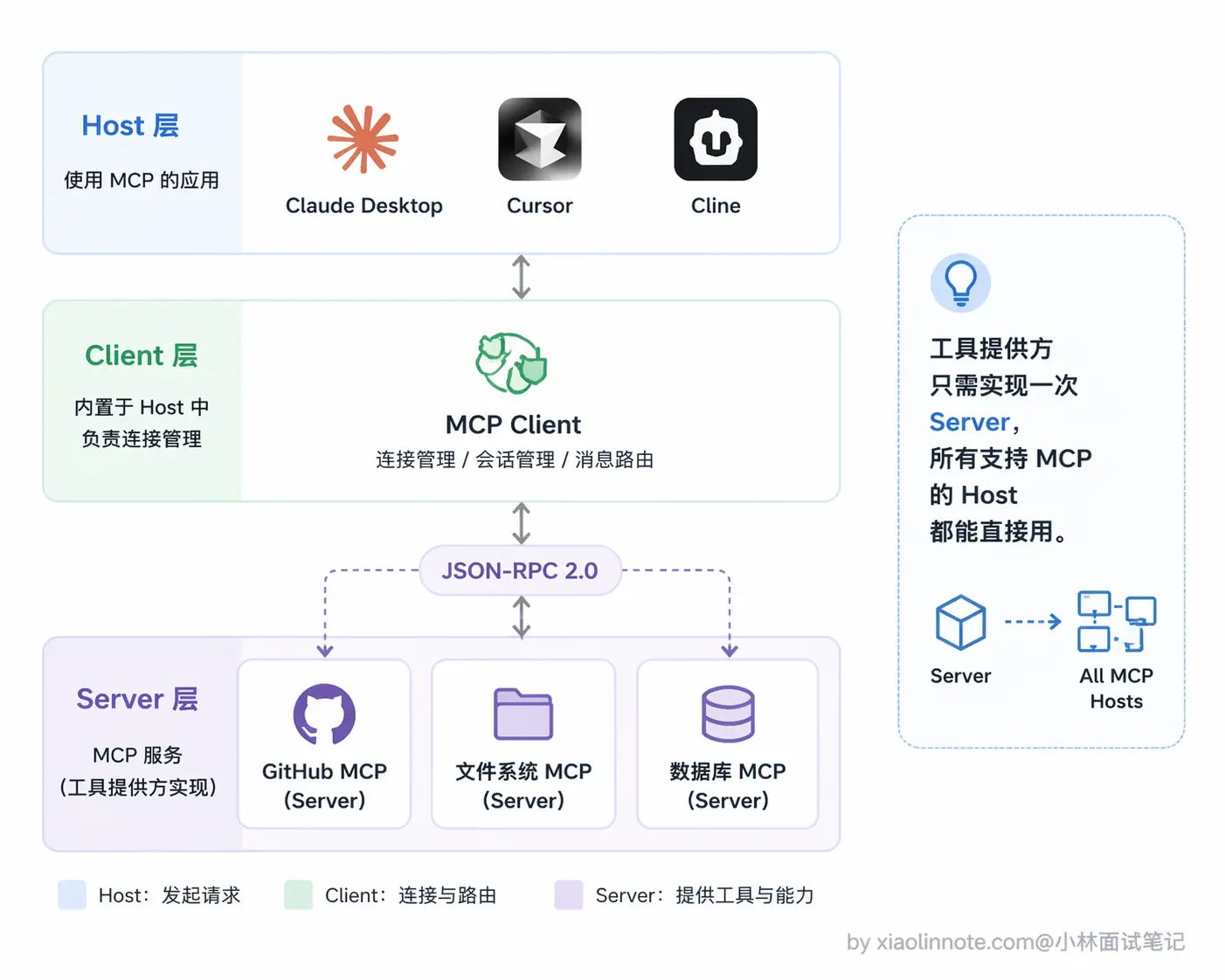
Anthropic 在 2024 年底提出的 MCP(Model Context Protocol,模型上下文协议)
然后是谷歌在2025年四月退出的agent2agent,解决了agent和agent之间的写作问题。
agent的组成部分
LLM+工具系统+记忆系统+规划
记忆
这里记忆系统分长短期记忆。
短期记忆是当前这轮上下文中的对话内容,是在context window里的。
长期记忆使用向量数据库来实现,把重要的信息embeddig之后存起来,下次用语义检索的时候可以拿回来。
短期记忆的挑战是上下文窗口的限制,每次工具有大量文本,上下文很快就满了。这时候要恶魔摘要压缩(把前面的步骤浓缩成关键信息)要么滑动窗口,只保留最近的几步详细内容。但不管哪种方式都会丢失信息,怎么在记住够多和不撑爆上下文中间做取舍,是记忆刚才里最核心的设计问题。
长期记忆的挑战在什么该存,什么不该存。存的太多会产生噪音,存的太少又失去长期上下文的意义。
比如三个月前客服处理的问题现在通常是不重要的。常用的指数衰减公式:
规划
规划决定了agent能否应对复杂任务。
比如任务是克隆一个写竞品分析报告,它就需要搜索资料,整理相关数据,对比分析,撰写报告。
最基础的是(chain of thought)COT,思维连,核心思想是让模型把思考过程写出来,而不是直接输出最终答案。
为什么这么简单一句话就能提升效果?因为 LLM 的 token 生成是逐步进行的,每一步推理的输出会成为下一步推理的输入,把中间步骤写出来,等于给了模型更多的「思考空间」。
在此基础上还有Tree of thoughts(ToT)思维数。它不是走一条线性的推理链,而是在每个推理节点上展开多个可能的分支,然后评估每个分支的质量,选出最优的路径继续往下走。
- 一种是先规划后执行,也就是plan and execute模式,先让LLM输出一个完整的步骤列表
- ReAct模式,每走一步就工具当前结果重新思考下一步该做什么。不提前指定计划。好处是灵活性高。
总的来说agent的节奏很简单:规划 决策 执行 结果存入记忆 再决策。
workflow agent Tools分别是什么?
Tools
tools是整个体系里最简单,最底层的概念,本质是是一个按定制格式暴露给LLM的函数:普通函数是给程序员调用的,Tool是给LLM调用的。所以要配一份LLM才能看得懂的schema(名字、描述、参数类型)
工具本身没有决策能力,它甚至不知道自己应该在什么时候被使用。
工具的设计要职责单一,描述精确,错误信息要清晰。Anthropic 在2024年提出的MCP,就是把工具的注册,描述调用做成一套标准的协议。
Agent
Tools就是拿着工具的角色。
Agent的运行方式是Thought、Action、Observation反复循环的模式。
WorkFlow
假设要做一个客服系统,大致流程就是先判断用户问的是什么问题。再去知识库里检索相关内容 生成一个回答。这些步骤分支完全可以在代码里写死。
Workflow 最大的优点是可预测、可控、好调试。你在代码里看到什么,它就做什么,不会有任何「惊喜」。生产环境里出了问题,你可以打断点逐步追,精确定位是哪个节点出了故障。这种确定性在线上系统里非常珍贵。
Anthropic 在他们的 Agent 工程实践中总结了几种常见的 Workflow 编排模式,值得了解一下。
• 第一种叫「Prompt Chaining」(提示链),就是把一个大任务拆成多个小步骤,前一步的输出作为后一步的输入,像流水线一样串起来。
• 第二种叫「Routing」(路由),先用一个 LLM 做分类判断,然后根据分类结果把请求分发到不同的处理分支,前面客服系统的例子就是典型的路由模式。
• 第三种叫「Parallelization」(并行化),把可以同时进行的子任务并行执行,最后汇总结果,这在需要多维度分析的场景下特别有用,比如同时从多个数据源检索信息。
• 第四种叫「Orchestrator-Workers」(编排者-工人),一个中央编排者负责分配任务,多个 Worker 各自完成子任务,适合任务可以分解但子任务之间相互独立的场景。
另一个非常实用的模式是evaluator-optimizer 评估者优化者模型。
一个 LLM 负责生成输出,另一个 LLM(或者同一个模型换一个角色)负责评估这个输出的质量,如果评估不通过就把反馈给回生成者,让它改进后重新输出,如此循环直到评估通过或者达到最大重试次数。
Agent是让llm自己决定下一步该干什么,WorkFlow是把流程写死,每一步怎么走都是确定的。
Agent的推理模式
推理模式,本质是是从直接输出答案变成一步一步推导答案。就像在数学题写的时候把过程写出来了。
COT就是在prompt里加一句,让我们一步一步思考,LLM就会把推理的过程写出来。
COT有俩种方式
第一种叫 Zero-shot CoT,做法非常简单,直接在 prompt 末尾加上「让我们一步步思考」这句话就行了,LLM 会自己展开推理过程,不需要你提供任何示例。这种方式的优势是零成本、即插即用,缺点是 LLM 的推理格式和深度完全靠它自己发挥,不太稳定,有时候会写得很详细,有时候又跳步。
• 第二种叫 Few-shot CoT,你需要在 prompt 里给几个带有完整推理过程的例子,让 LLM 照着这个格式来模仿。比如你先写一道数学题,把每一步怎么算、最后得出什么结论都写清楚,LLM 看到这个模板之后就会按照同样的格式展开推理。Few-shot 的效果更稳定,特别适合输出格式要求比较固定的场景,代价是需要你提前准备高质量的示例,而且示例本身也会占用 token。
React
ReAct是Reasoning and Acting的缩写,在思维连里面插入真实的行动。
ReAct的效果比纯CoT或者纯Act-only效果来的好。纯CoT推理的再好也拿不到真实数据。纯Act-only走的是另一个极端,让LLM直接输出工具调用序列,不写任何思考过程。
ReAct 的精妙之处就在于把推理和行动交织在一起:Thought 帮助 LLM 分析当前局势、决定下一步该做什么,Action 让它把决策落地为真实操作,Observation 把外部世界的反馈带回来,三者互补形成闭环。推理为行动提供方向,行动为推理提供事实,这才是 ReAct 比前两种方案都好用的根本原因。
假设你问 Agent「2024 年苹果公司和谷歌的市值谁更高?差多少?」,如果只靠 CoT,LLM 只能说出它训练时知道的数字,可能已经不准了。但用 ReAct,整个过程会是这样的:
Thought: 这道题需要两家公司的实时市值数据,我得先查苹果的市值
Action: search
Action Input: 苹果公司 2024 年市值
Observation: 苹果公司 2024 年市值约为 3.5 万亿美元
Thought: 好,苹果的数字有了,再查谷歌的
Action: search
Action Input: 谷歌 2024 年市值
Observation: 谷歌 2024 年市值约为 2.1 万亿美元
Thought: 两个数字都有了,苹果 3.5 万亿,谷歌 2.1 万亿,苹果更高,差距是 1.4 万亿
Final Answer: 苹果公司 2024 年市值约 3.5 万亿美元,谷歌约 2.1 万亿美元,苹果更高,差距约 1.4 万亿美元Plan-and-execute
你可以把 ReAct 和 Plan-and-Execute 的区别,类比成「边走边问路」和「先看地图再出发」的区别。
reflection
在ReAct、Plan-and-Execute额外加了一层自我检查自我修正的环节。
replan
用来解决定死计划中途遇到的意外该怎么处理。
动态 Replan 的做法是在每个步骤执行完之后,把当前结果和剩余计划一起交给规划模块,让它判断「原来的计划还合理吗,需不需要调整」。如果需要,就生成一份新的剩余步骤计划,替换掉原来的。
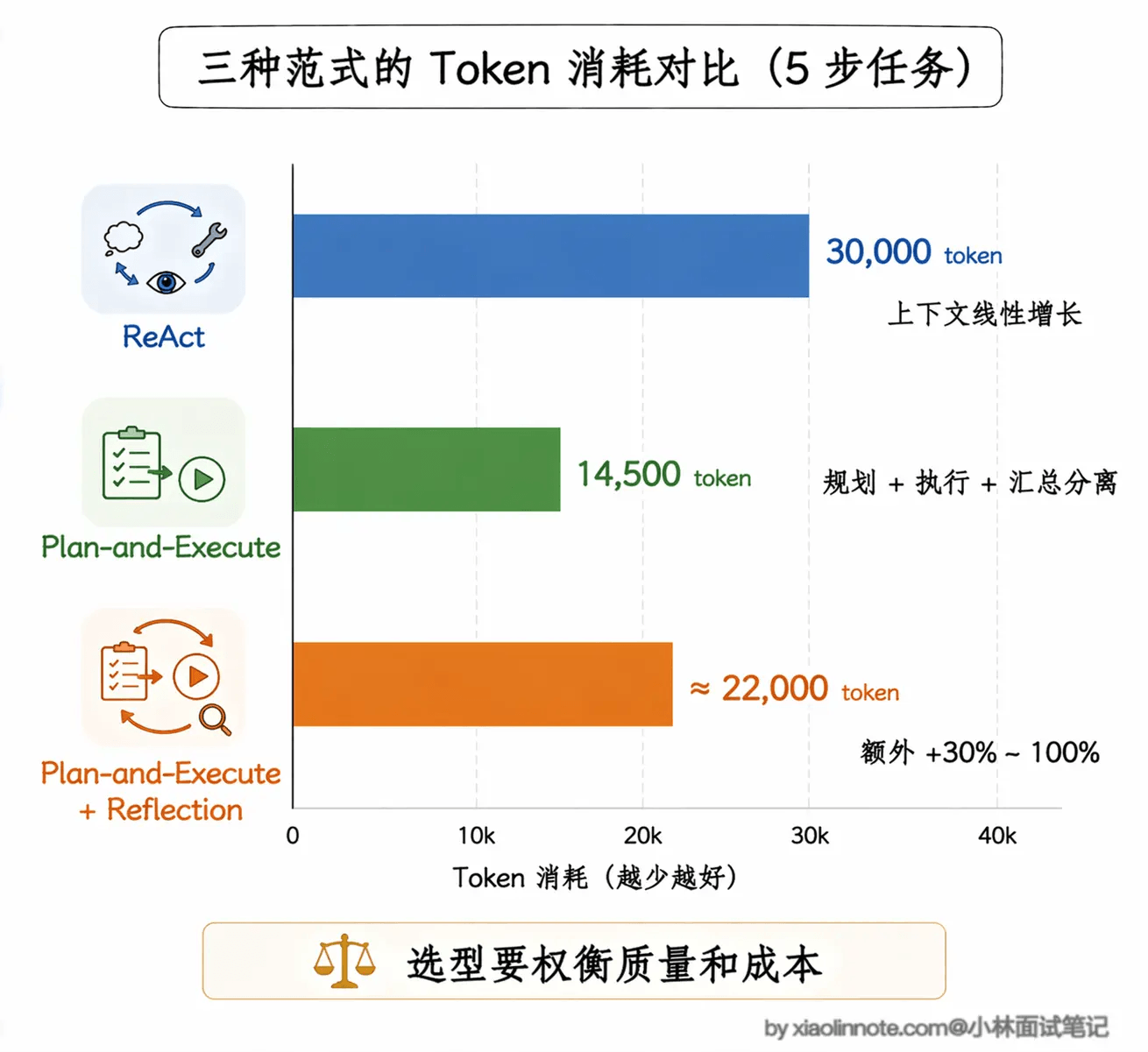
这样既保留了 Plan-and-Execute「先规划再执行」的结构优势,又不会因为计划太僵硬而在意外情况下翻车。代价是每步都多了一次「重新评估计划」的 LLM 调用,token 消耗会增加。
任务拆分
任务拆分是因为一次性处理太复杂的任务很容易出错,把大人物拆成小任务,每步聚焦一件事情准确率就会明显提升。
分俩种,一种是静态拆分,一种是动态拆分。
静态拆分就是设计任务流程,规定乘一个确定的workflow,每一步干什么按什么顺序执行,全部写死。比如写技术博客,固定拆成手机资料,整理大纲,撰写,润色校对。好处是行为可预测,出问题方便排查。坏处是灵活性低,遇到没设计到的情况就容易卡主。
动态拆分是把任务拆解这件事情本身也交给LLM来做。也就是plan-and-execute核心思想。
任务的粒度把控很重要。太细导致LLM调用次数变多,总token消耗上升。 事情负责的太多也会导致出错的概率上升。
更好的做法是,不要在开始的时候就把所有步骤的粒度定死,而是根据每一步实际难度调整。核心逻辑就是先尝试完成任务,做的好就继续做,作品不啊哈哦就拆分。先试 不好就拆。
好的任务拆分应该满足三个条件
- 完备性:所有步骤加在一起能不能覆盖原始需求。
- 独立性:每个步骤的职责边界是不是清晰,职责有没有重叠
- 可验证性:每个步骤执行完了之后能否用简单的标注判断是不是作对了。
开源框架
mem0是最火的agent记忆框架之一,核心思路是把记忆做成服务层,可以使用memory.add()存记忆、memory.search()查记忆。底层的embedding 去重冲突消除全部都做好了。 mem0特别适合个性化记忆的场景,比如记住每个用户的偏好和习惯,按不同user_id做记忆隔离,不同用户记忆互不干扰。并且它同时支持向量存储和图(知识图谱)存储。
此外知名的还有letta,前身是大名鼎鼎的MemGPT,还有一个值得关注的是ZAP,引入了时间感知的概念。
记忆模块配合
记忆和agent的写作模式为读、用、写。
- 读:用户发来一个心情求,agent先去翻档案:得到用户过往决策,以及用户画像。
- 用:用户每一条消息、模型的每一次输出、工具调用返回的每一个结果都追加到Message。每次调用LLM都带上完整离散
- 写:任务完成把本次任务产生的新知识写回持久化存储。
反思
烦死机制就是让agent在完成一个步骤后,自我评估输出质量判断有没有问题,相当于人写完东西自己再看一遍。代价是多一次调用,所以一般只在关键点使用,而不是每次都做。
步骤级烦死是在每一步就进行反思,任务级烦死是整个任务执行完一次做一次整体评估。
多agent还可以互相评论反思。可以设置一个单独的agent来审查执行agent。
多agent
多agent分为三类
- 第一类是流水线模式,Agent 之间按固定顺序依次执行,前一个完成后交给下一个,像工厂的装配线;
- 第二类是层级模式,有一个 Orchestrator(指挥者)负责分配任务、收集结果,其他 Agent 各自执行分配到的子任务;
- 第三类是协商模式,多个 Agent 之间没有严格的上下级关系,通过互相沟通、辩论来达成一致。
多agent写作分为共享状态和局部状态。
首先是状态结构要分层,通常会把状态分成「全局状态」和「局部状态」两层。全局状态存放所有 Agent 都需要读取的信息,比如用户的原始请求、当前任务进展、最终输出,这些是共享的。
局部状态存放每个 Agent 自己的中间结果,比如搜索 Agent 找到的候选文档列表、代码 Agent 生成的草稿代码,这些在 Agent 内部使用,不会直接暴露给其他 Agent,避免信息污染。
其次是写入规则要明确。最简单也最可靠的做法是「只追加不覆盖」,每个 Agent 完成工作后把结果追加到状态里,而不是修改已有的字段。LangGraph 的 State 更新机制就是这个思路,你定义好 State 的 schema,每个节点返回的是一个「增量更新」,框架帮你合并到全局状态里,这样就不会出现互相覆盖的问题。
最后是错误状态的处理。如果某个 Agent 执行失败了,它的错误信息也应该写入状态,而不是悄悄吞掉。后续的 Agent 或者 Orchestrator 读到这个错误状态后,才能做出正确的决策,比如跳过这一步、换一个 Agent 重试、或者直接终止任务。