Cassandra
Cassandra 简介 - Apache Cassandra中文手册 (dba.cn)
简介
Apache Cassandra是一个高度可扩展的高性能分别是数据库,用于处理大量商用服务器上的大量数据,提高可用性,无单点故障。是一种Nosql类型数据库。
| 关系数据库 | NoSQL数据库 |
|---|---|
| 支持强大的查询语言。 | 支持非常简单的查询语言。 |
| 它具有固定的模式。 | 无固定模式。 |
| 遵循ACID(原子性,一致性,隔离性和持久性)。 | 只有“最终一致”。 |
| 支持事务。 | 不支持事务。 |
特性
- 弹性可扩展:Cassandra是高度可扩展的;它允许添加更多的硬件以适应更多的客户端和更多的数据根据需求。
- 始终基于架构:Cassandra没有单点故障,它可以连续用于不能承担故障的关键业务应用程序
- 快速线性性能:Cassandra是线性可扩展的,即它为你增加急群中节点数量增加你的吞吐量。因此保持一个快速响应时间
- 灵活的数据存储:Cassandra适应所有可能的数据格式,包括:结构化,半结构化和非结构化,它可以根据您的需求动态适应变化的数据结构。
- 敏捷的数据分发:Cassandra通过在多个数据中心中复制数据,可以灵活地在需要时分发数据
- 事务支持:Cassandra支持属性,如原子性,一致性,隔离和持久性(ACID)。
- 快速写入:Cassandra被设计为在廉价的商品硬件上运行。 它执行快速写入,并可以存储数百TB的数据,而不牺牲读取效率。
架构
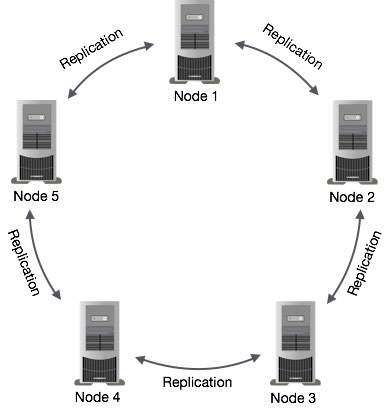
Cassandra的设计目的是处理跨多个节点的大数据工作负载,而没有任何单点故障。Cassandra在其节点之间具有对等分布式系统,并且数据分布在集群的所有节点之间。
集群中的所有节点都扮演相同的角色,每个节点是独立的,并且同时互联都按其他节点。
急群中每个节点都可以接受读取和写入请求,无论数据实际位于急群中的何处。
当节点关闭时,可以从网络中的其他节点提供读写请求。
数据复制
在Cassandra中,集群中的一个或多个节点充当给定数据片段的副本。如果检测到一些节点过期相应,Cassandra将向客户端返回最近的值。返回最新的值后,Cassandra在后台执行读修复以更新失效值。
组件
- 节点:它是存储数据的地方
- 数据中心:它是相关节点的集合
- 集群:集群是包含一个或多个数据中心的组件
- 提交日志:是cassandra中崩溃恢复机制。每个操作都写入提交日志。
- Mem表:mem表是存储器驻留的数据结构,提交日志后,数据将被写入mem表。有时,相对单列族,将有多个mem表。
- SSTable:它是一个磁盘文件,当其内容达到阈值时,数据从mem表中刷新
- 布隆过滤器:这些只是快速,非确定性的算法英语测试元素是否是集合的成员。它是一种特殊的缓存。每次查询后访问Bloom过滤器
查询语言
用户可以使用Cassandra查询语言(CQL)通过其节点访问Cassandra.CQL将数据库(keyspace)视为容器。程序员使用cqlsh:提示以使用CQL或单独的应用程序语言驱动程序。
客户端针对其读写操作访问其任何节点。该节点(协调器)在客户端和保存数据的节点之间播放代理。
写操作
节点的每个写入活动都由接写在节点中的提交日志捕获。稍后数据江北捕获并存储在存储表中。每当内存满时,数据将写入SStable数据文件。所有写入都会在整个集群中自动分区和复制。Cassandra会定期整合SSTable,丢弃不必要的数据。
读操作
LSM-Tree的树节点可以分为两种,保存在内存中的称之为MemTable, 保存在磁盘上的称之为SSTable
在 读操作,Cassandra从MEM-表得到的值,并检查过滤器栈放到保存所需数据的相应的SSTable。
数据模型
集群Cluster
Cassandra数据库分布在几个一起操作的机器上。最外层容器被称为集群。对于故障处理,每个节点包含一个副本,副本将负责。Cassandra按照环形格式将节点排列在集群中,并为它们分配数据。
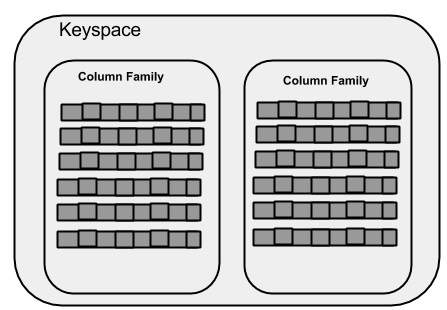
键空间(Keyspace)
键空间是Cassandra中最外层的容器。Cassandra中的一个键空间的基本属性是
- 复制因子:它是急群中将接受相同数据副本的计算机数。
- 副本放置策略 - 它只是把副本放在戒指中的策略。我们有简单策略(机架感知策略),旧网络拓扑策略(机架感知策略)和网络拓扑策略(数据中心共享策略)等策略。
- 列族:键空间是一个或多个列族的容器,列族优势一个行集合的容器。每行包含有序列。列族表示数据的结构。每个空间至少有一个,通常是许多列族。
创建键空间的语法如下 -
CREATE KEYSPACE Keyspace name
WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 3};下图显示了键空间的示意图。
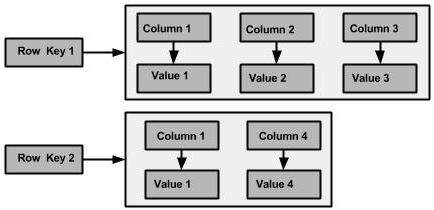
列族
列族是有序收集行的容器。有是一行优势一个有序的列集合。下表列出了区分列系列和关系数据库的要点。
| 关系表 | Cassandra列族 |
|---|---|
| 关系模型中的模式是固定的。 一旦为表定义了某些列,在插入数据时,在每一行中,所有列必须至少填充一个空值。 | 在Cassandra中,虽然定义了列族,但列不是。 您可以随时向任何列族自由添加任何列。 |
| 关系表只定义列,用户用值填充表。 | 在Cassandra中,表包含列,或者可以定义为超级列族。 |
Cassandra列族具有以下属性 -
- keys_cached - 它表示每个SSTable保持缓存的位置数。
- rows_cached - 它表示其整个内容将在内存中缓存的行数。
- preload_row_cache -它指定是否要预先填充行缓存。
注 - 与不是固定列族的模式的关系表不同,Cassandra不强制单个行拥有所有列。
下图显示了Cassandra列族的示例。
列
列是Cassandra的基本数据结构,具有三个值,即键或列名称,值和时间戳。下面给出了列的结构。
- name:byte[]
- value:byte[]
- clock:clock[]
超级列
超级列是一个特殊的列,因此,它也是一个键值对。但是超级列存储了子列的地图。
通常列族被存储在磁盘上的单个文件中。因此,为了优化性能,重要的是保持您看在同一列中一起查询的列,并且超级列在此可以有所帮助。下面是超激列的结构
- name:byte[]
- cols:map<byte[],column>
Cassandra 和 RDBMS 的数据模型
下表列出了区分Cassandra的数据模型和RDBMS的数据模型的要点。
| 关系型数据库 | Cassandra |
|---|---|
| RDBMS处理结构化数据。 | Cassandra处理非结构化数据。 |
| 它具有固定的模式。 | Cassandra具有灵活的架构。 |
| 在关系型数据库中,表是一个数组的数组。 (ROW x COLUMN) | 在Cassandra中,表是“嵌套的键值对”的列表。 (ROW x COLUMN键x COLUMN值) |
| 数据库是包含与应用程序对应的数据的最外层容器。 | Keyspace是包含与应用程序对应的数据的最外层容器。 |
| 表是数据库的实体。 | 表或列族是键空间的实体。 |
| Row是关系型数据库中的单个记录。 | Row是Cassandra中的一个复制单元。 |
| 列表示关系的属性。 | Column是Cassandra中的存储单元。 |
| 关系型数据库支持外键的概念,连接。 | 关系是使用集合表示。 |