kubernetes Secrt和kubeconfig
Secrt
简介
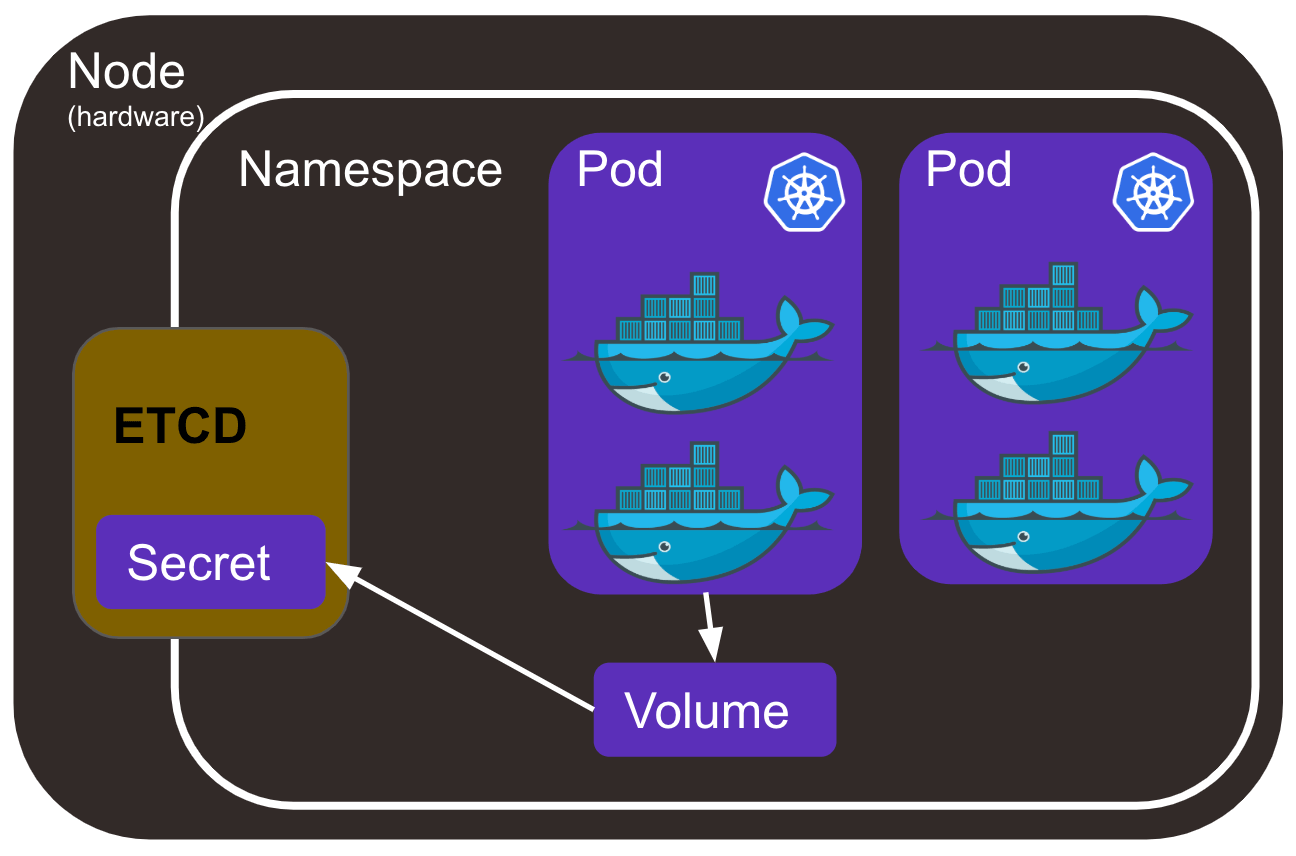
Secret是一种包含少量敏感信息、令牌或密钥对象。这样的信息可能会被放在Pod规约中或者镜像中。使用Secret意味着你不需要再应用程序代码中包含机密数据。
由于创建Secret可以独立于它们的Pod,因此再创建、查看和编辑Pod的工作流程中暴露Secret(及其数据)的风险较小。Kubernetes和在急群中运行的应用程序也可以对Secret采取额外的预防措施,例如避免将敏感数据写入非易失性存储。
Secret类似于ConfigMap但用于保存机密数据。
data字段用来存储base64编码的数据,stringData存储未编码的字符串。
Secret意味着你不需要再应用程序代码中包含机密数据,减少机密数据(如密码)泄露的风险。
Secret可以用作环境变量、命令行参数或者存储卷文件。
默认情况下,Kubernetes Secret未加密地存储在API服务器的底层数据存储中(etcd)。任何拥有访问权限的人都可以检索或修改Secret,任何有权访问etcd的人也可以。此外,任何有权限在命名空间中创建Pod的人都可以使用访问权限读取该命名空间中的任何Secret;这包括间接访问,例如创建Deployment的能力。
为了安全使用Secret,请至少执行以下步骤。
- 为Secret启用静态加密。
- 以最小特权访问Secret并启用或配置RBAC规则。
- 限制Secret对特定容器的访问
- 考虑使用外部Secret存储驱动
使用场景
- 设置容器的环境变量。
- 向Pod提供SSH密钥或密码登凭据。
- 允许kubelet从私有仓库中拉取镜像。
Kubernetes控制面也使用Secret;列如,引导令牌Secret是一种帮助自动化节点注册的机制。
使用场景:在Secret卷中带句点的文件
通过定义句点 (.)开头的主键,你可以隐藏你的数据。这些主键代表的是以句点开头的文件或隐藏文件。例如,当以下Secret被挂载到secret-volume卷上是,该卷会包含一个名为.secret-file的文件,并且容器 dotfile-test-container 中此文件位于路径 /etc/secret-volume/.secret-file 处。
使用场景:仅对Pod中一个容器可见的Secret
考虑一个需要处理HTTP请求,执行某些复杂的业务逻辑,之后使用HMAC来对某些消息进行签名的程序。因为这一程序的应用逻辑复杂,其中可能包含违背注意到的远程服务器文件读取漏洞,这种漏洞可能会把撕咬暴露给攻击者。
这一程序可以分割成俩个容器进程:前端容器要处理用户交互和业务逻辑但无法看到私钥;签名容器可以看到私钥,并对前端的简单签名请求做出响应(例如,通过本地主机网络。)
采用这种划分的方法,攻击者现在必须欺骗应用服务器来做一些其他操作, 而这些操作可能要比读取一个文件要复杂很多。
使用
secret用来保存小片敏感数据的k8s资源,例如密码,token,或者秘钥。这类数据当然也可以存放在Pod或者镜像中,但是放在Secret中是为了更方便的控制如何使用数据,并减少暴露的风险。
用户可以创建自己的secret,系统也会有自己的secret。
Pod需要先引用才能使用某个secret
pod有俩种方式来使用secret
- 作为volume的一个域被多个容器挂载
- 在拉取镜像的时候被kubelet引用
Secret用法
echo -n '123456' | base64
echo 'MTIzNDU2' | base64 --decodeapiVersion: v1
kind: Secret
metadata:
name: mysql-password
type: Opaque
data:
PASSWORD: MTIzNDU2Cg==
---
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-password
key: PASSWORD
optional: false # 此值为默认值;表示secret已经存在了
volumeMounts:
- mountPath: /var/lib/mysql
name: data-volume
- mountPath: /etc/mysql/conf.d
name: conf-volume
readOnly: true
volumes:
- name: conf-volume
configMap:
name: mysql-config
- name: data-volume
hostPath:
# directory location on host
path: /home/mysql/data
# this field is optional
type: DirectoryOrCreate
---
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql-config
data:
mysql.cnf: |
[mysqld]
character-set-server=utf8mb4
collation-server=utf8mb4_general_ci
init-connect='SET NAMES utf8mb4'
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4kubeconfig
多集群用户认证机制
使用kubeconfig文件来组织有关集群、用户、命名空间和身份认真的信息。kubectl命令行工具使用kubeconfig文件来查找选择集群所需信息,并与集群的API服务器进行通信。
说明:用于配置集群访问的文件成为kubeconfig文件。这是引用到配置文件的通用方法,并不意味着有一个名为kubeconfig的文件
警告:请务必使用来源可靠的kubeconfig文件。使用特指的kubeconfig文件可能会导致恶意代码执行或文件暴露。如果必须使用不信任的kubeconfig文件,请首先像检查 Shell 脚本一样仔细检查此文件。
默认情况下,kubectl,在$HOME/.kube目录下查找名为config的文件。 你可以通过设置 KUBECONFIG 环境变量或者设置 --kubeconfig参数来指定其他 kubeconfig 文件。
支持多集群、用户身份认证机制
假设你有多个集群,并且你的用户和组件以多种方式进行身份认真。比如
- 正在运行的kubelet可能使用证书在尽显认证
- 用户可能通过令牌进行认证
- 管理员可能拥有多个证书集合提供给各用户
使用kubeconfig文件,你可以组织集群、用户和命名空间。你还可以定义上下文,以便在集群和命名空间之间快速轻松切换。
上下文
通过kubecinfig文件中的context元素,使用简便的名称来对访问参数进行分组。每个context都有三个参数:cluster、namespace和user。默认情况下,kubectl命令行工具使用当前上下文中的参数与集群进行通信。
选择当前上下文:
kubectl config use-contextKUBECONFIG 环境变量
KUBECONFIG 环境变量包含一个 kubeconfig 文件列表。 对于 Linux 和 Mac,此列表以英文冒号分隔。对于 Windows,此列表以英文分号分隔。 KUBECONFIG 环境变量不是必需的。 如果 KUBECONFIG 环境变量不存在,kubectl 将使用默认的 kubeconfig 文件:$HOME/.kube/config。
如果 KUBECONFIG 环境变量存在,kubectl 将使用 KUBECONFIG 环境变量中列举的文件合并后的有效配置。
合并 kubeconfig 文件
要查看配置,输入以下命令:
kubectl config view如前所述,输出可能来自单个 kubeconfig 文件,也可能是合并多个 kubeconfig 文件的结果。
以下是 kubectl 在合并 kubeconfig 文件时使用的规则。
- 如果设置了
--kubeconfig参数,则仅使用指定的文件。不进行合并。此参数只能使用一次。
否则,如果设置了 KUBECONFIG 环境变量,将它用作应合并的文件列表。根据以下规则合并 KUBECONFIG 环境变量中列出的文件:
- 忽略空文件名。
- 对于内容无法反序列化的文件,产生错误信息。
- 第一个设置特定值或者映射键的文件将生效。
- 永远不会更改值或者映射键。示例:保留第一个文件的上下文以设置
current-context。 示例:如果两个文件都指定了red-user,则仅使用第一个文件的red-user中的值。 即使第二个文件在red-user下有非冲突条目,也要丢弃它们。
有关设置 KUBECONFIG 环境变量的示例, 请参阅设置 KUBECONFIG 环境变量。
否则,使用默认的 kubeconfig 文件($HOME/.kube/config),不进行合并。
根据此链中的第一个匹配确定要使用的上下文。
- 如果存在上下文,则使用
--context命令行参数。 - 使用合并的 kubeconfig 文件中的
current-context。
- 如果存在上下文,则使用
这种场景下允许空上下文。
确定集群和用户。此时,可能有也可能没有上下文。根据此链中的第一个匹配确定集群和用户, 这将运行两次:一次用于用户,一次用于集群。
- 如果存在用户或集群,则使用命令行参数:
--user或者--cluster。 - 如果上下文非空,则从上下文中获取用户或集群。
- 如果存在用户或集群,则使用命令行参数:
这种场景下用户和集群可以为空。
确定要使用的实际集群信息。此时,可能有也可能没有集群信息。 基于此链构建每个集群信息;第一个匹配项会被采用:
- 如果存在集群信息,则使用命令行参数:
--server、--certificate-authority和--insecure-skip-tls-verify。 - 如果合并的 kubeconfig 文件中存在集群信息属性,则使用这些属性。
- 如果没有 server 配置,则配置无效。
- 如果存在集群信息,则使用命令行参数:
确定要使用的实际用户信息。使用与集群信息相同的规则构建用户信息,但对于每个用户只允许使用一种身份认证技术:
- 如果存在用户信息,则使用命令行参数:
--client-certificate、--client-key、--username、--password和--token。 - 使用合并的 kubeconfig 文件中的
user字段。 - 如果存在两种冲突技术,则配置无效。
- 如果存在用户信息,则使用命令行参数:
- 对于仍然缺失的任何信息,使用其对应的默认值,并可能提示输入身份认证信息。
文件引用
kubeconfig 文件中的文件和路径引用是相对于 kubeconfig 文件的位置。 命令行上的文件引用是相对于当前工作目录的。 在 $HOME/.kube/config 中,相对路径按相对路径存储,而绝对路径按绝对路径存储。
代理
你可以在 kubeconfig 文件中,为每个集群配置 proxy-url 来让 kubectl 使用代理,例如:
apiVersion: v1
kind: Config
clusters:
- cluster:
proxy-url: http://proxy.example.org:3128
server: https://k8s.example.org/k8s/clusters/c-xxyyzz
name: development
users:
- name: developer
contexts:
- context:
name: development