CNI和docker-compose
转载自K8s 网络之深入理解 CNI - 知乎 (zhihu.com)
先导1
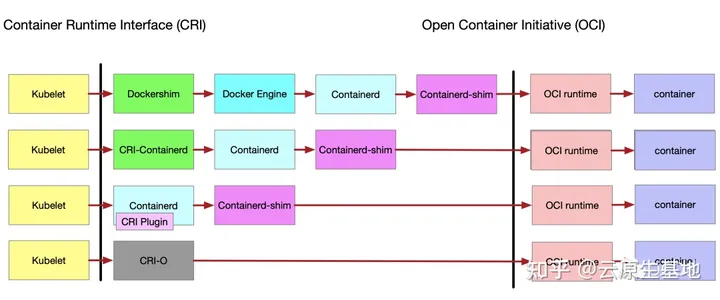
K8s 已经在很早前的 1.20 版发布之前就宣布要移除内嵌在 kubelet 中的 docker shim 的代码,大概原因就是谷歌一直在 k8s 中使用一套叫做 CRI(container runtime interface)的规范,该规范旨在定义 k8s 如何更好地操作容器技术,该规范大概分为三部分:CRI Client,CRI Server,OCI Runtime
简单来讲,就是在kubelet中放一个grpc的客户端,这个客户端要和一个grpc的服务端进行通信,这个grpc的服务端里进行容器的,“拉起“,”销毁“等动作的调用,而执行”拉起“,”销毁“懂动作的代码由OCI Runtime实现。
或者再简单点,对应到实现来说:CRI Client段有个实现就是kubelet,CRI Server端有个实现叫Containerd,OCI Runtime由好多实现其中有个叫runc。然后把他们串起来就是:kubelet在昨晚了一些准入校验,CSI的存储卷挂载等操作之后,要去拉起一个pod了,在拉起pod的时候,就先启动了一个grpc的客户端,然后与Containerd中的grpc的服务端通信,告诉它说要拉起一个Pod了。然后Containerd收到后会按照一定的流程去拉取镜像,创建sandbox、创建netns、启动容器、创建容器网络,把容器假如到sandbox中等。containerd基本上只负责调用(高级运行时),真正实现这些功能的地方在OCI的runc(或其他低级运行时)中,有点像通常服务端的controller和service。
不同的低级运行时因为实现逻辑以及调用逻辑可能不太一样,就比如runc是利用namespace,kata是直接起的qemu虚拟机,因此containerd到OCI之间还会有一层shim,containerd到runc有runc-shim,到kata有kata-shim
所谓的废弃 docker,其实不是真的直接干掉 docker,而是上面我们说 CRI 规范要有个 grpc 的 client 和 server 端嘛,然后 server 端通知 oci 里头去创建 ns 或者创建网络等,但是对于 docker 来讲,docker 内置了创建网络,创建存储卷等功能,在 k8s 里,这些功能比如挂载存储功能由 CSI 实现,挂载网络由 CNI 实现等,所以 docker 很多功能 k8s 并不需要,因此 kubelet 内嵌了一个 docker-shim 作为 grpc 的 client 端用来屏蔽掉 docker 的一些内置功能后再和 containerd 通信,所以其实对于 k8s 来讲,这个 docker-shim 是个冗余的负担,因此所谓的“废弃”,指的是将 docker-shim 的代码从 kubelet 中移除,在减负的同时也能通过让第三方实现 CRI 规范中的东西而接入到 k8s 里。
Docker-comnpose
docker-compose是一种编排服务,基于python实现
是一个用于哎docker上定于并运行复杂应用的工具,可以让用户在集群中部署分布式应用。
用户可以很容易的用一个配置文件定义一个多容器的应用,然后使用一条皮指令安装这个应用的所有依赖,完成构建。解决了容器与容器之间编排的问题。
1、compose是docker推出的(swarm也是,级别同k8s),k8s是CNCF推出的
2、compose只能在一 台宿主机上编排容器,而k8s可以在很多台机器上编排容器
CNI简介
本次我们想介绍的,就是上面的 OCI 规范中有一步叫 “创建网络”。对于 k8s 来讲,网络属于最重要的功能之一,因为没有一个良好的网络,集群不同节点之间甚至同一个节点之间的 pod 就无法良好的运行起来。
K8s 在设计网络的时候,采用的准则就一点:“灵活”!那怎么才能灵活呢?答案就是“我不管,你自己做”~
没错,k8s 自己没有实现太多跟网络相关的操作,而是制定了一个规范。该规范贼简单,一共就三点:
- 有一个配置文件,配置文件里协商要使用的网络插件名,以及一些该插件需要的信息。
- 让CRI调用这个插件,并把容器的运行时信息,包括容器的命名空间,容器ID等信息传给插件
- 插件实现自定义逻辑,返回结果中包含podIP就可以
这就是CNI规范,简单,足够灵活
不过恰恰就是因为 k8s 自己“啥也不干”,所以大家可以自由发挥,自由实现不同的 CNI 插件,反正 pod 的相关你都给我了,我要的配置也都通过配置文件设置好了,那我作为插件的实现方,当然就可以 free style 了,反正最终目的就是能让 pod 有一个健康的网络就好了嘛~
因此就有了现在如此多的网络插件,比如 flannel,这个是利用的静态路由表配置或者 vxlan 实现的网络通信。再比如 calico,是通过 BGP 协议实现了动态路由。再比如其他还有什么 Weave,以及 OVN 之类的各种各样的网络插件。这些插件虽然实现的方法各式各样,但是最终目的只有一个,就是让集群中的各种 pod 之间能自由通信。
在K8s中,由于不同的pod可能遍布在同一个节点上,也可能在不同的节点上,因此在k8s的网络环境中,需要解决三点问题
- pod IP地址的管理
- 同一节点上的pod之间相互通信
- 不同节点上的pod之间相互通信
基本上只要想好了方法解决这三个问题,那我们就可以自己实现一个 CNI 网络插件了。
总结
- k8s 的 kubelet 在启动一个容器之前,会先做一些预先检查以及 csi 的操作
- 然后 kubelet 调用 CRI 的接口,通过 grpc 的方式和 CRI runtime 通信,告知 CRI 要创建 pod 了
- 随后 CRI 的 Server 端收到通知后调用 OCI 的接口去真正的执行拉起 Pod 的操作
- 不过在真的拉起 pod 之前,会先给 pod 创建一个 pause 容器,这个 pause 容器是一个特别小又特别稳定的进程,主要用来挂载网络命名空间和存储资源
- 然后 CRI 调用 CNI 提供的接口,先在 /etc/cni/net.d 目录中获取网络插件配置(这个配置由每个插件自己通过 daemonset 的方式拷贝到主机上), 然后把插件的配置作为标准输入, 再把容器的运行时信息作为环境变量, 最后执行插件
- CNI 插件执行完毕后, 把执行结果(结果要包含一些关键信息比如 Pod IP 等)直接干到标准输出上
- CRI 从标准输出上读取插件执行结果再做后续操作, 后续操作就是拉起真正的容器等