Kubernetes架构官网笔记
节点
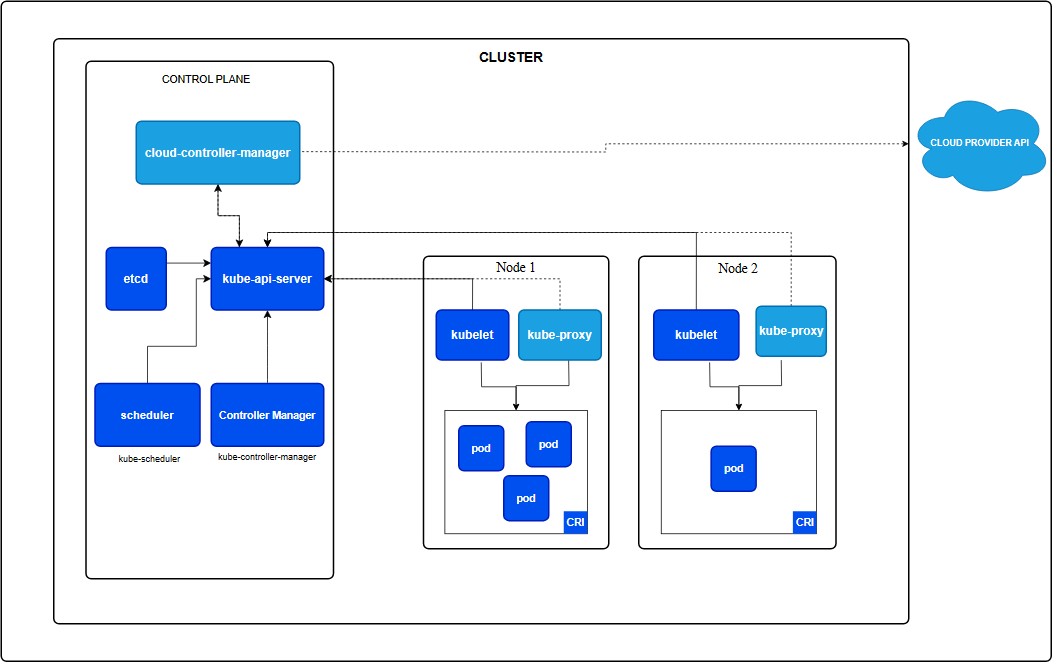
Kubernetes 通过将容器放入在节点(Node)上运行的 Pod 中来执行你的工作负载。 节点可以是一个虚拟机或者物理机器,取决于所在的集群配置。 每个节点包含运行 Pod 所需的服务; 这些节点由控制面负责管理。
通常集群中会有若干个节点;而在一个学习所用或者资源受限的环境中,你的集群中也可能只有一个节点。
节点上的组件包括 kubelet、 容器运行时以及 kube-proxy。
管理
向API服务器添加节点的方式主要有俩种:
- 节点上的kubelet向控制面执行注册
- 手动添加一个Node对象
在你创建了 Node 对象或者节点上的 kubelet 执行了自注册操作之后,控制面会检查新的 Node 对象是否合法。 例如,如果你尝试使用下面的 JSON 对象来创建 Node 对象:
{
"kind": "Node",
"apiVersion": "v1",
"metadata": {
"name": "10.240.79.157",
"labels": {
"name": "my-first-k8s-node"
}
}
}Kubernetes会在内部创建一个Node对象作为节点表示。Kubertes检查Kubelet向API服务注册节点时使用的metadata.name字段是否匹配。如果节点是健康的(即所有必要的服务都在运行中),则该节点可以用来运行Pod。否则直到该节点变为健康节点之前,所有集群活动都会忽略该节点。
Kubernetes会一直保存着非法节点对应的对象,并持续检查该节点是否已经变得健康。
你,或者某个控制器必须显式的删除该Node对象以停止对健康检查的操作。
Node对象的名称必须是合法的子域名。
很多资源类型需要可以用作 DNS 子域名的名称。 DNS 子域名的定义可参见 RFC 1123。 这一要求意味着名称必须满足如下规则:
- 不能超过 253 个字符
- 只能包含小写字母、数字,以及 '-' 和 '.'
- 必须以字母数字开头
- 必须以字母数字结尾
节点的名称唯一性
节点的名称用来标识Node对象。没有俩个Node可以同时使用相同的名称。Kubernetes还嘉定名字相同的资源是同一个对象。
就Node而言,隐式嘉定使用相同名称的实例具有相同的状态(列如网络配置、根磁盘内容)和类似节点标签这类属性。这可能在节点被更改但其名称未变时导致系统状态不一致。如果某个Node需要被替换或者大量变更,需要从API服务器移除现有的Node对象,之后再更新之后重新将其加入。
节点自注册
当 kubelet 标志 --register-node 为 true(默认)时,它会尝试向 API 服务注册自己。 这是首选模式,被绝大多数发行版选用。
对于自注册模式,kubelet 使用下列参数启动:
--kubeconfig- 用于向 API 服务器执行身份认证所用的凭据的路径。--cloud-provider- 与某云驱动 进行通信以读取与自身相关的元数据的方式。--register-node- 自动向 API 服务器注册。--register-with-taints- 使用所给的污点列表 (逗号分隔的<key>=<value>:<effect>)注册节点。当register-node为 false 时无效。--node-ip- 可选的以英文逗号隔开的节点 IP 地址列表。你只能为每个地址簇指定一个地址。 例如在单协议栈 IPv4 集群中,需要将此值设置为 kubelet 应使用的节点 IPv4 地址。 参阅配置 IPv4/IPv6 双协议栈了解运行双协议栈集群的详情。
如果你未提供这个参数,kubelet 将使用节点默认的 IPv4 地址(如果有); 如果节点没有 IPv4 地址,则 kubelet 使用节点的默认 IPv6 地址。
--node-labels- 在集群中注册节点时要添加的标签。 (参见 NodeRestriction 准入控制插件所实施的标签限制)。--node-status-update-frequency- 指定 kubelet 向 API 服务器发送其节点状态的频率。
当 Node 鉴权模式和 NodeRestriction 准入插件被启用后, 仅授权 kubelet 创建/修改自己的 Node 资源。
说明:
正如节点名称唯一性一节所述,当 Node 的配置需要被更新时, 一种好的做法是重新向 API 服务器注册该节点。例如,如果 kubelet 重启时其
--node-labels是新的值集,但同一个 Node 名称已经被使用,则所作变更不会起作用, 因为节点标签是在 Node 注册时完成的。如果在 kubelet 重启期间 Node 配置发生了变化,已经被调度到某 Node 上的 Pod 可能会出现行为不正常或者出现其他问题,例如,已经运行的 Pod 可能通过污点机制设置了与 Node 上新设置的标签相排斥的规则,也有一些其他 Pod, 本来与此 Pod 之间存在不兼容的问题,也会因为新的标签设置而被调到同一节点。 节点重新注册操作可以确保节点上所有 Pod 都被排空并被正确地重新调度。
节点手动管理
你可以使用kubectl来创建和修改Node对象。
如果你希望手动创建节点对象时,请设置kubelet标志--register-node=false
你可以修改Node对象(忽略--register-node设置)。例如,你可以修改节点上的标签或并标记其为不可调度。
你可以结合使用 Node 上的标签和 Pod 上的选择算符来控制调度。 例如,你可以限制某 Pod 只能在符合要求的节点子集上运行。
如果标记节点为不可调度(unschedulable),将阻止新 Pod 调度到该 Node 之上, 但不会影响任何已经在其上的 Pod。 这是重启节点或者执行其他维护操作之前的一个有用的准备步骤。
要标记一个 Node 为不可调度,执行以下命令:
kubectl cordon $NODENAME节点状态
一个节点的状态包含以下信息
- 地址addresses
- 状况Condition
- 容量和可分配Capacity
- 信息Info
你可以使用kubectl来查看节点状态和其他细节信息
kubectl describe node 节点名称节点心跳
kubernetes发送节点心跳帮助你的集群确定每个节点的可用性并在检测刀故障时采取行动。
- 更新节点的.status
- kube-node-lease名字空间中的lease租约对象。每个节点都有一个关联的lease对象。
节点控制器
节点控制器是kubernetes控制面组件,管理节点的方方面面。
节点控制器在节点的生命周期中扮演多个角色。第一个是当节点注册时为它分配一个CIDR区段。
CIDR无类别域间路由,Class Inter-Domain Routing是一个在internet上创建附加地址的方法,这些地址提供给服务提供商ISP,再由ISP分配给客户。
CIDR将路由集中起来,是一个IP地址代表骨干提供商的几千个IP地址,从而减轻internet路由器负担。
IP地址有俩部分组成:
- 网络地址,这是一串指向网络唯一标识的数字
- 主机地址,这是一串数字,表示网络上的主机或单个设备标识符
有类地址,IPV4 32位组成。用句号分割的每串数字由8位组成,以0-255的数字形式表示。(ABC类 )
吴磊地址:吴磊或吴磊别区间路由(CIDR)地址使用可变长度子网掩码(VLSM)来改变IP网络地址位和主机地址位之间的比率。子网掩码是一组标识符,通过将主机地址变为0,从IP地址返回网络的地址。
VLSM序列允许网络管理员将IP地址分解为不同大小的子网。每个子网可以有灵活的主机数量和有限的IP地址数量。CIDR IP地址在普通IP地址的基础上附加了一个后缀值,说明网络地址的前缀数。
第二个是保持节点控制器内的节点列表与云服务商所提供的可用机器列表同步。如果在云环境下运行,只要某节点不健康,节点控制器会询问云服务器是否节点的虚拟机仍可用。如果不可用,节点控制器会将该节点从它的节点列表删除。
第三个是节点的健康状况。节点控制器负责:
- 在节点不可达的情况下,在Node的.status中更新Ready状况。在这种情况下,节点控制器将NodeReady状态更新为Unknown。
- 如果节点仍然无法访问:对于不可达节点上的所有Pod触发API发起的逐出操作。默认情况下,节点控制器将节点标记为Unknown后等待五分钟提交一个逐出请求。
默认情况下,节点控制器每5秒检查一次节点状态,可以用kube-controller-manager组件上的--node-monitor-period参数来配置周期。
逐出速率限制
大部分情况下,节点控制器把逐出速率限制在每秒 --node-eviction-rate 个(默认为 0.1)。 这表示它每 10 秒钟内至多从一个节点驱逐 Pod。
当一个可用区域(Availability Zone)中的节点变为不健康时,节点的驱逐行为将发生改变。 节点控制器会同时检查可用区域中不健康(Ready 状况为 Unknown 或 False) 的节点的百分比:
- 如果不健康节点的比例超过
--unhealthy-zone-threshold(默认为 0.55), 驱逐速率将会降低。 - 如果集群较小(意即小于等于
--large-cluster-size-threshold个节点 - 默认为 50), 驱逐操作将会停止。 - 否则驱逐速率将降为每秒
--secondary-node-eviction-rate个(默认为 0.01)。
在逐个可用区域中实施这些策略的原因是,当一个可用区域可能从控制面脱离时其他可用区域仍然保持链接。如果你的集群没有跨越云服务商的多个可用区域,那(整个集群)就只有一个可用区域。
跨多个可用区域部署你的节点的一个关键原因是当某个可用区域整体出现故障时,工作负载可以转移到健康的可用区域。
跨多个可用其余部署你的节点的关键原因是当某个可用区域整体出现故障时,工作负载可以转移到健康的可用区域,那(整个集群)只有一个可用区域。
跨多个可用区域部署你的节点的一个关键原因是当某个可用区域整体出现故障时,工作负载可以转移到健康的可用区域。因此,如果一个可用区域的所有节点都不健康时,节点控制器会以正常的速率--node-eviction-rate进行驱逐操作。在所有的可用区域都不健康(也即急群众没有健康节点)的极端情况下,节点控制器将假设控制面与节点之间的连接出了问题,它将停止所有驱逐动作(如果故障后部分节点重新连接,节点控制器会从剩下不健康或者不可达的节点中驱逐pod)
节点控制器还负责驱逐运行在拥有NoExecute污点的节点上的Pod,除非这些Pod能够容忍此污点。节点控制器还负责根据节点故障(列如节点不可访问或没有就绪)为其添加污点。这意味着调度器不会将Pod调度到不健康的节点上。
资源容量跟踪
Node对象会跟踪节点上资源的容量(列如可用内存和cpu数量)。通过自动注册机制生成的Node对象会在注册期间报告自身容量。如果你手动添加了Node,你就需要再添加节点时手动设置节点容量
Kubernetes调度器保证节点上有足够的资源 供其上的所有pod使用。它会检查节点上所有容器的请求总和不会超过节点的容量。总的请求包括有kubelet启动的所有容器,但不包括由容器运行时直接启动的容器,也不包括kubelet控制的其他进程
节点拓扑
特性状态: Kubernetes v1.18 [beta]
如果启用了 TopologyManager 特性门控, kubelet 可以在作出资源分配决策时使用拓扑提示。 参考控制节点上拓扑管理策略了解详细信息。
节点体面关闭
特性状态: Kubernetes v1.21 [beta]
kubelet会尝试检测节点系统关闭事件并终止在节点上运行所有的Pod。
在节点终止期间,Kubelet保证Pod遵从常规的Pod终止流程,且不接受新的Pod(即使这些Pod已经绑定到该节点)
由于 Pod 所代表的是在集群中节点上运行的进程,当不再需要这些进程时允许其体面地终止是很重要的。 一般不应武断地使用
KILL信号终止它们,导致这些进程没有机会完成清理操作。设计的目标是令你能够请求删除进程,并且知道进程何时被终止,同时也能够确保删除操作终将完成。 当你请求删除某个 Pod 时,集群会记录并跟踪 Pod 的体面终止周期, 而不是直接强制地杀死 Pod。在存在强制关闭设施的前提下, kubelet 会尝试体面地终止 Pod。
通常 Pod 体面终止的过程为:kubelet 先发送一个带有体面超时限期的 TERM(又名 SIGTERM) 信号到每个容器中的主进程,将请求发送到容器运行时来尝试停止 Pod 中的容器。 停止容器的这些请求由容器运行时以异步方式处理。 这些请求的处理顺序无法被保证。许多容器运行时遵循容器镜像内定义的
STOPSIGNAL值, 如果不同,则发送容器镜像中配置的 STOPSIGNAL,而不是 TERM 信号。 一旦超出了体面终止限期,容器运行时会向所有剩余进程发送 KILL 信号,之后 Pod 就会被从 API 服务器上移除。 如果kubelet或者容器运行时的管理服务在等待进程终止期间被重启, 集群会从头开始重试,赋予 Pod 完整的体面终止限期。
节点体面关闭特性依赖于systemd,因为它要利用systemd抑制器锁机制,在给定期限内延迟节点的关闭。
节点的体面关闭特性受GracefulNodeShutdown 特性门控控制, 在 1.21 版本中是默认启用的。
注意,默认情况下,下面描述的两个配置选项,shutdownGracePeriod 和 shutdownGracePeriodCriticalPods 都是被设置为 0 的,因此不会激活节点体面关闭功能。 要激活此功能特性,这两个 kubelet 配置选项要适当配置,并设置为非零值。
一旦 systemd 检测到或通知节点关闭,kubelet 就会在节点上设置一个 NotReady 状况,并将 reason 设置为 "node is shutting down"。 kube-scheduler 会重视此状况,不将 Pod 调度到受影响的节点上; 其他第三方调度程序也应当遵循相同的逻辑。这意味着新的 Pod 不会被调度到该节点上, 因此不会有新 Pod 启动。
如果检测到节点关闭过程正在进行中,kubelet 也会在 PodAdmission 阶段拒绝 Pod,即使是该 Pod 带有 node.kubernetes.io/not-ready:NoSchedule 的容忍度。
同时,当 kubelet 通过 API 在其 Node 上设置该状况时,kubelet 也开始终止在本地运行的所有 Pod。
在体面关闭节点过程中,kubelet 分两个阶段来终止 Pod:
- 终止在节点上运行的常规 Pod。
- 终止在节点上运行的关键 Pod。
节点体面关闭的特性对应两个 KubeletConfiguration 选项:
shutdownGracePeriod- 指定节点应延迟关闭的总持续时间。此时间是 Pod 体面终止的时间总和,不区分常规 Pod 还是关键 Pod。
shutdownGracePeriodCriticalPods- 在节点关闭期间指定用于终止关键 Pod 的持续时间。该值应小于
shutdownGracePeriod。
- 在节点关闭期间指定用于终止关键 Pod 的持续时间。该值应小于
基于Pod优先级的节点体面关闭
为了在节点体面关闭期间提供更多的灵活性,尤其是处理关闭期间的 Pod 排序问题, 节点体面关闭机制能够关注 Pod 的 PriorityClass 设置,前提是你已经在集群中启用了此功能特性。 此功能特性允许集群管理员基于 Pod 的优先级类(Priority Class) 显式地定义节点体面关闭期间 Pod 的处理顺序。
前文所述的节点体面关闭特性能够分两个阶段关闭 Pod, 首先关闭的是非关键的 Pod,之后再处理关键 Pod。 如果需要显式地以更细粒度定义关闭期间 Pod 的处理顺序,需要一定的灵活度, 这时可以使用基于 Pod 优先级的体面关闭机制。
当节点体面关闭能够处理 Pod 优先级时,节点体面关闭的处理可以分为多个阶段, 每个阶段关闭特定优先级类的 Pod。kubelet 可以被配置为按确切的阶段处理 Pod, 且每个阶段可以独立设置关闭时间。
假设集群中存在以下自定义的 Pod 优先级类。
| Pod 优先级类名称 | Pod 优先级类数值 |
|---|---|
custom-class-a | 100000 |
custom-class-b | 10000 |
custom-class-c | 1000 |
regular/unset | 0 |
在 kubelet 配置中, shutdownGracePeriodByPodPriority 可能看起来是这样:
| Pod 优先级类数值 | 关闭期限 |
|---|---|
| 100000 | 10 秒 |
| 10000 | 180 秒 |
| 1000 | 120 秒 |
| 0 | 60 秒 |
对应的 kubelet 配置 YAML 将会是:
shutdownGracePeriodByPodPriority:
- priority: 100000
shutdownGracePeriodSeconds: 10
- priority: 10000
shutdownGracePeriodSeconds: 180
- priority: 1000
shutdownGracePeriodSeconds: 120
- priority: 0
shutdownGracePeriodSeconds: 60处理节点非体面关闭
特性状态: Kubernetes v1.28 [stable]
特性状态: Kubernetes v1.28 [stable]
节点关闭的操作可能无法被 kubelet 的节点关闭管理器检测到, 是因为该命令不会触发 kubelet 所使用的抑制锁定机制,或者是因为用户错误的原因, 即 ShutdownGracePeriod 和 ShutdownGracePeriodCriticalPod 配置不正确。 请参考以上节点体面关闭部分了解更多详细信息。
当某节点关闭但 kubelet 的节点关闭管理器未检测到这一事件时, 在那个已关闭节点上、属于 StatefulSet 的 Pod 将停滞于终止状态,并且不能移动到新的运行节点上。 这是因为已关闭节点上的 kubelet 已不存在,亦无法删除 Pod, 因此 StatefulSet 无法创建同名的新 Pod。 如果 Pod 使用了卷,则 VolumeAttachments 不会从原来的已关闭节点上删除, 因此这些 Pod 所使用的卷也无法挂接到新的运行节点上。 所以,那些以 StatefulSet 形式运行的应用无法正常工作。 如果原来的已关闭节点被恢复,kubelet 将删除 Pod,新的 Pod 将被在不同的运行节点上创建。 如果原来的已关闭节点没有被恢复,那些在已关闭节点上的 Pod 将永远滞留在终止状态。
为了缓解上述情况,用户可以手动将具有 NoExecute 或 NoSchedule 效果的 node.kubernetes.io/out-of-service 污点添加到节点上,标记其无法提供服务。 如果在 kube-controller-manager 上启用了 NodeOutOfServiceVolumeDetach 特性门控, 并且节点被通过污点标记为无法提供服务,如果节点 Pod 上没有设置对应的容忍度, 那么这样的 Pod 将被强制删除,并且该在节点上被终止的 Pod 将立即进行卷分离操作。 这样就允许那些在无法提供服务节点上的 Pod 能在其他节点上快速恢复。
在非体面关闭期间,Pod 分两个阶段终止:
- 强制删除没有匹配的
out-of-service容忍度的 Pod。 - 立即对此类 Pod 执行分离卷操作。
交换内存管理
特性状态: Kubernetes v1.28 [beta]
要在节点上启用交换内存,必须启用 kubelet 的 NodeSwap 特性门控, 同时使用 --fail-swap-on 命令行参数或者将 failSwapOn 配置设置为 false。
警告:
当内存交换功能被启用后,Kubernetes 数据(如写入 tmpfs 的 Secret 对象的内容)可以被交换到磁盘。
用户还可以选择配置 memorySwap.swapBehavior 以指定节点使用交换内存的方式。例如:
memorySwap:
swapBehavior: UnlimitedSwapUnlimitedSwap(默认):Kubernetes 工作负载可以根据请求使用尽可能多的交换内存, 一直到达到系统限制为止。LimitedSwap:Kubernetes 工作负载对交换内存的使用受到限制。 只有具有 Burstable QoS 的 Pod 可以使用交换空间。
如果启用了特性门控但是未指定 memorySwap 的配置,默认情况下 kubelet 将使用与 UnlimitedSwap 设置相同的行为。
采用 LimitedSwap 时,不属于 Burstable QoS 分类的 Pod (即 BestEffort/Guaranteed QoS Pod) 被禁止使用交换内存。为了保持上述的安全性和节点健康性保证, 在 LimitedSwap 生效时,不允许这些 Pod 使用交换内存。
在详细介绍交换限制的计算之前,有必要定义以下术语:
nodeTotalMemory:节点上可用的物理内存总量。totalPodsSwapAvailable:节点上可供 Pod 使用的交换内存总量 (一些交换内存可能被保留由系统使用)。containerMemoryRequest:容器的内存请求。
交换限制被配置为 (containerMemoryRequest / nodeTotalMemory) * totalPodsSwapAvailable 的值。
需要注意的是,位于 Burstable QoS Pod 中的容器可以通过将内存请求设置为与内存限制相同来选择不使用交换空间。 以这种方式配置的容器将无法访问交换内存。
只有 cgroup v2 支持交换空间,cgroup v1 不支持。
节点于控制面之间的通讯
本文列举控制面(确切的说是API服务器,API服务器是控制面的一部分,负责公开K8sAPI 负责处理接受请求的工作)和Kubernetes集群之间通信路径。目的是为了让用户能够自定义他们的安装,已实现对网络配置的加固,使得集群能够在不可信的网络上(或者在一个云服务商完全公开的IP上)运行。
节点到控制面
kubernetes采用的是中心辐射型(Hub-and-Spoke)API模式。所有从节点(或云星宇其上的Pod)发出的API调用都终止于API服务器。其它控制面组件都没有被设计为可暴露远程服务。API服务器被配置为在一个安全的HTTPS端口(通常为443)上监听远程连接请求,并启用一种或多种形式的客户端身份认真机制,一种或多种客户端鉴权机制应该被启动,特别是允许使用匿名请求或服务账户的令牌的时候。
应该使用集群的公共证书开通节点,这样它们就能够给予有效的客户端票据安全地连接API服务器。一种好的方法是一客户端证书的形式将客户端凭据提供给kubelet。请查看 kubelet TLS 启动引导 以了解如何自动提供 kubelet 客户端证书。
想要连接到API服务器的Pod可以使用服务账号安全地连接。当Pod被实例化时,Kubernetes自动把公共根证书和一个有效的持有者令牌注入到Pod里。kubernetes服务(位于defalt名字空间中)配置了一个虚拟IP地址,通过kube-proxy请求转到API服务器的HTTP末端
控制面组件也通过安全端口与集群的API服务器通信。这样,从集群节点和节点上运行的Pod到控制面的连接缺省操作也即是安全的,能够在不可信的网络或公网上运行。
控制面到节点
从控制面(API服务器)到节点主要有俩种主要的通信路径。第一种是从API服务器到急群众每个节点运行的kubelet进程。第二种是从API服务器通过它的代理功能连接到任何节点。Pod或服务。
API 服务器到 kubelet
从 API 服务器到 kubelet 的连接用于:
- 获取 Pod 日志。
- 挂接(通过 kubectl)到运行中的 Pod。
- 提供 kubelet 的端口转发功能。
这些连接终止于 kubelet 的 HTTPS 末端。 默认情况下,API 服务器不检查 kubelet 的服务证书。这使得此类连接容易受到中间人攻击, 在非受信网络或公开网络上运行也是 不安全的。
为了对这个连接进行认证,使用 --kubelet-certificate-authority 标志给 API 服务器提供一个根证书包,用于 kubelet 的服务证书。
如果无法实现这点,又要求避免在非受信网络或公共网络上进行连接,可在 API 服务器和 kubelet 之间使用 SSH 隧道。
最后,应该启用 Kubelet 认证/鉴权 来保护 kubelet API。
API 服务器到节点、Pod 和服务
从 API 服务器到节点、Pod 或服务的连接默认为纯 HTTP 方式,因此既没有认证,也没有加密。 这些连接可通过给 API URL 中的节点、Pod 或服务名称添加前缀 https: 来运行在安全的 HTTPS 连接上。 不过这些连接既不会验证 HTTPS 末端提供的证书,也不会提供客户端证书。 因此,虽然连接是加密的,仍无法提供任何完整性保证。 这些连接 目前还不能安全地 在非受信网络或公共网络上运行。
SSH 隧道
Kubernetes 支持使用 SSH 隧道来保护从控制面到节点的通信路径。 在这种配置下,API 服务器建立一个到集群中各节点的 SSH 隧道(连接到在 22 端口监听的 SSH 服务器) 并通过这个隧道传输所有到 kubelet、节点、Pod 或服务的请求。 这一隧道保证通信不会被暴露到集群节点所运行的网络之外。
说明:
SSH 隧道目前已被废弃。除非你了解个中细节,否则不应使用。 Konnectivity 服务是 SSH 隧道的替代方案。
Konnectivity 服务
特性状态: Kubernetes v1.18 [beta]
作为 SSH 隧道的替代方案,Konnectivity 服务提供 TCP 层的代理,以便支持从控制面到集群的通信。 Konnectivity 服务包含两个部分:Konnectivity 服务器和 Konnectivity 代理, 分别运行在控制面网络和节点网络中。 Konnectivity 代理建立并维持到 Konnectivity 服务器的网络连接。 启用 Konnectivity 服务之后,所有控制面到节点的通信都通过这些连接传输。
请浏览 Konnectivity 服务任务 在你的集群中配置 Konnectivity 服务。
控制器
在机器人技术和自动化领域,控制回路(Control Loop)是一个非终止回路,用于调节系统状态。
这是一个控制环的例子:房间里的温度自动调节器。
当你设置了温度,告诉了温度自动调节器你的期望状态(Desired State)。 房间的实际温度是当前状态(Current State)。 通过对设备的开关控制,温度自动调节器让其当前状态接近期望状态。
在 Kubernetes 中,控制器通过监控集群 的公共状态,并致力于将当前状态转变为期望的状态。
控制器模式
一个控制器至少追踪一种类型的Kubernetes资源。这些对象有一个代表期望状态的spec字段。该资源的控制器负责确保当前状态接近期望的状态。
控制器可能会自行执行的操作;在Kubernetes中更常见的是一个控制器会发送信息给API服务器,这会有副作用。
通过API服务来控制
Job控制器是一个Kubernetes内置控制器的例子。内置控制器通过和集群API服务器交互来管理状态。
Job 会创建一个或者多个 Pod,并将继续重试 Pod 的执行,直到指定数量的 Pod 成功终止。 随着 Pod 成功结束,Job 跟踪记录成功完成的 Pod 个数。 当数量达到指定的成功个数阈值时,任务(即 Job)结束。 删除 Job 的操作会清除所创建的全部 Pod。 挂起 Job 的操作会删除 Job 的所有活跃 Pod,直到 Job 被再次恢复执行。
一种简单的使用场景下,你会创建一个 Job 对象以便以一种可靠的方式运行某 Pod 直到完成。 当第一个 Pod 失败或者被删除(比如因为节点硬件失效或者重启)时,Job 对象会启动一个新的 Pod。
你也可以使用 Job 以并行的方式运行多个 Pod。
Job是一种kubernetes资源,它运行一个或多个pod,来执行一个任务然后停止。(一旦被调度了,对kubelet来说Pod对象就会变成了期望状态的一部分)。
在急群众,当Job控制器拿到新任务时,它会保证一组Node节点上的kubelet可以运行正确数量的Pod来完成工作。Job控制器不会自己运行任何的Pod或容器。Job控制器是通知API服务器来创建或者移除Pod。
控制面中的其它组件根据新的消息做出反应(调度并运行新Pod)并且完成最终工作。
创建新Pod后,所期望的状态就是完成这个Job。Job控制器会让Job的当前状态不断接近期望状态:创建Job要完成工作所需要的Pod,使Job的状态接近完成。控制器也会更新配置对象。例如:一旦Job工作完成了,Job控制器会更新Job对象的状态为Finished
(这有点像温度自动调节器关闭了一个灯,以此来告诉你房间的温度现在到你设定的值了)。
直接控制
相比Job控制器,有些控制器需要对集群外的一些东西进行修改。
例如,如果你使用一个控制回路来保证急群中有足够的节点,那么控制器就需要当前集群外的一些服务在需要时创建新节点。
和外部状态控制器从API服务器获取到它想要的状态,然后直接和外部系统进行通信并使当前状态更接近期望的状态。
(实际上有一个控制器 可以水平地扩展集群中的节点。)
这里的重点是,控制器做出了一些变更以使得事物更接近你的期望状态, 之后将当前状态报告给集群的 API 服务器。 其他控制回路可以观测到所汇报的数据的这种变化并采取其各自的行动。
在温度计的例子中,如果房间很冷,那么某个控制器可能还会启动一个防冻加热器。 就 Kubernetes 集群而言,控制面间接地与 IP 地址管理工具、存储服务、云驱动 APIs 以及其他服务协作,通过扩展 Kubernetes 来实现这点。
期望状态与当前状态
Kubernetes 采用了系统的云原生视图,并且可以处理持续的变化。
在任务执行时,集群随时都可能被修改,并且控制回路会自动修复故障。 这意味着很可能集群永远不会达到稳定状态。
只要集群中的控制器在运行并且进行有效的修改,整体状态的稳定与否是无关紧要的。
设计
作为设计原则之一,Kubernetes 使用了很多控制器,每个控制器管理集群状态的一个特定方面。 最常见的一个特定的控制器使用一种类型的资源作为它的期望状态, 控制器管理控制另外一种类型的资源向它的期望状态演化。 例如,Job 的控制器跟踪 Job 对象(以发现新的任务)和 Pod 对象(以运行 Job,然后查看任务何时完成)。 在这种情况下,新任务会创建 Job,而 Job 控制器会创建 Pod。
使用简单的控制器而不是一组相互连接的单体控制回路是很有用的。 控制器会失败,所以 Kubernetes 的设计正是考虑到了这一点。
说明:
可以有多个控制器来创建或者更新相同类型的对象。 在后台,Kubernetes 控制器确保它们只关心与其控制资源相关联的资源。
例如,你可以创建 Deployment 和 Job;它们都可以创建 Pod。 Job 控制器不会删除 Deployment 所创建的 Pod,因为有信息 (标签)让控制器可以区分这些 Pod。
运行控制器的方式
Kubernetes 内置一组控制器,运行在 kube-controller-manager 内。 这些内置的控制器提供了重要的核心功能。
Deployment 控制器和 Job 控制器是 Kubernetes 内置控制器的典型例子。 Kubernetes 允许你运行一个稳定的控制平面,这样即使某些内置控制器失败了, 控制平面的其他部分会接替它们的工作。
你会遇到某些控制器运行在控制面之外,用以扩展 Kubernetes。 或者,如果你愿意,你也可以自己编写新控制器。 你可以以一组 Pod 来运行你的控制器,或者运行在 Kubernetes 之外。 最合适的方案取决于控制器所要执行的功能是什么。
租约Lease
分别是系统通常需要租约(Lease);租约提供了一种机制来锁定共享资源并协调集合成员之间的活动。在Kubernetes中,租约概念表示为coordination.k8s.ioAPI组中的Lease对象,常用与类似心跳和组件级领导者选举等系统核心能力。
节点心跳
kubernetes使用Lease API将kubelet节点心跳传递到Kubernetes API服务器。对于每个Node,在kube-node-lease名字空间中都有一个匹配名称的lease对象。再此基础上,每个kubelet心跳都是对该lease对象update请求,更新该lease的spec.renewTime字段。Kubernetes控制平面使用此字段的时间戳来确定Node的可用性。
领导者选举
Kubernetes也是用Lease确保任何给定时间某个组件只有一个实例在运行。这在高可用配置中由kube-controller-manager和kube-scheduler等控制平面组件进行使用,这些组件只有一个实例激活运行,而且其它实例待机。
API服务器身份
特性状态: Kubernetes v1.26 [beta]
从 Kubernetes v1.26 开始,每个 kube-apiserver 都使用 Lease API 将其身份发布到系统中的其他位置。 虽然它本身并不是特别有用,但为客户端提供了一种机制来发现有多少个 kube-apiserver 实例正在操作 Kubernetes 控制平面。kube-apiserver 租约的存在使得未来可以在各个 kube-apiserver 之间协调新的能力。
你可以检查 kube-system 名字空间中名为 kube-apiserver-<sha256-hash> 的 Lease 对象来查看每个 kube-apiserver 拥有的租约。你还可以使用标签选择算符 apiserver.kubernetes.io/identity=kube-apiserver:
kubectl -n kube-system get lease -l apiserver.kubernetes.io/identity=kube-apiserver
NAME HOLDER AGE
apiserver-07a5ea9b9b072c4a5f3d1c3702 apiserver-07a5ea9b9b072c4a5f3d1c3702_0c8914f7-0f35-440e-8676-7844977d3a05 5m33s
apiserver-7be9e061c59d368b3ddaf1376e apiserver-7be9e061c59d368b3ddaf1376e_84f2a85d-37c1-4b14-b6b9-603e62e4896f 4m23s
apiserver-1dfef752bcb36637d2763d1868 apiserver-1dfef752bcb36637d2763d1868_c5ffa286-8a9a-45d4-91e7-61118ed58d2e 4m43s租约名称中使用的 SHA256 哈希基于 API 服务器所看到的操作系统主机名生成。 每个 kube-apiserver 都应该被配置为使用集群中唯一的主机名。 使用相同主机名的 kube-apiserver 新实例将使用新的持有者身份接管现有 Lease,而不是实例化新的 Lease 对象。 你可以通过检查 kubernetes.io/hostname 标签的值来查看 kube-apisever 所使用的主机名:
kubectl -n kube-system get lease apiserver-07a5ea9b9b072c4a5f3d1c3702 -o yaml
apiVersion: coordination.k8s.io/v1
kind: Lease
metadata:
creationTimestamp: "2023-07-02T13:16:48Z"
labels:
apiserver.kubernetes.io/identity: kube-apiserver
kubernetes.io/hostname: master-1
name: apiserver-07a5ea9b9b072c4a5f3d1c3702
namespace: kube-system
resourceVersion: "334899"
uid: 90870ab5-1ba9-4523-b215-e4d4e662acb1
spec:
holderIdentity: apiserver-07a5ea9b9b072c4a5f3d1c3702_0c8914f7-0f35-440e-8676-7844977d3a05
leaseDurationSeconds: 3600
renewTime: "2023-07-04T21:58:48.065888Z"kube-apiserver 中不再存续的已到期租约将在到期 1 小时后被新的 kube-apiserver 作为垃圾收集。
你可以通过禁用 APIServerIdentity 特性门控来禁用 API 服务器身份租约。
工作负载
你自己的工作负载可以定义自己使用的 Lease。例如, 你可以运行自定义的控制器, 让主要成员或领导者成员在其中执行其对等方未执行的操作。 你定义一个 Lease,以便控制器副本可以使用 Kubernetes API 进行协调以选择或选举一个领导者。 如果你使用 Lease,良好的做法是为明显关联到产品或组件的 Lease 定义一个名称。 例如,如果你有一个名为 Example Foo 的组件,可以使用名为 example-foo 的 Lease。
如果集群操作员或其他终端用户可以部署一个组件的多个实例, 则选择名称前缀并挑选一种机制(例如 Deployment 名称的哈希)以避免 Lease 的名称冲突。
你可以使用另一种方式来达到相同的效果:不同的软件产品不相互冲突。
运行时容器接口
CRI 是一个插件接口,它使 kubelet 能够使用各种容器运行时,无需重新编译集群组件。
你需要在集群中的每个节点上都有一个可以正常工作的容器运行时, 这样 kubelet 能启动 Pod 及其容器。
容器运行时接口(CRI)是 kubelet 和容器运行时之间通信的主要协议。
Kubernetes 容器运行时接口(Container Runtime Interface;CRI)定义了主要 gRPC 协议, 用于节点组件 kubelet 和容器运行时之间的通信。
API
当通过 gRPC 连接到容器运行时,kubelet 将充当客户端。运行时和镜像服务端点必须在容器运行时中可用, 可以使用 --image-service-endpoint 命令行标志在 kubelet 中单独配置。
对 Kubernetes v1.28,kubelet 偏向于使用 CRI v1 版本。 如果容器运行时不支持 CRI 的 v1 版本,那么 kubelet 会尝试协商较老的、仍被支持的所有版本。 v1.28 版本的 kubelet 也可协商 CRI v1alpha2 版本,但该版本被视为已弃用。 如果 kubelet 无法协商出可支持的 CRI 版本,则 kubelet 放弃并且不会注册为节点。
垃圾收集
垃圾收集是Kubernetes用于清理集群资源的各种机制的统称。垃圾收集允许系统清理如下资源
- 终止的 Pod
- 已完成的 Job
- 不再存在属主引用的对象
- 未使用的容器和容器镜像
- 动态制备的、StorageClass 回收策略为 Delete 的 PV 卷
- 阻滞或者过期的 CertificateSigningRequest (CSR)
- 在以下情形中删除了的
节点
对象:
- 当集群使用云控制器管理器运行于云端时;
- 当集群使用类似于云控制器管理器的插件运行在本地环境中时。
属主与依赖
Kubernetes 中很多对象通过属主引用 链接到彼此。属主引用(Owner Reference)可以告诉控制面哪些对象依赖于其他对象。 Kubernetes 使用属主引用来为控制面以及其他 API 客户端在删除某对象时提供一个清理关联资源的机会。 在大多数场合,Kubernetes 都是自动管理属主引用的。
属主关系与某些资源所使用的标签和选择算符不同。 例如,考虑一个创建 EndpointSlice 对象的 Service。 Service 使用标签来允许控制面确定哪些 EndpointSlice 对象被该 Service 使用。 除了标签,每个被 Service 托管的 EndpointSlice 对象还有一个属主引用属性。 属主引用可以帮助 Kubernetes 中的不同组件避免干预并非由它们控制的对象。
说明:
根据设计,系统不允许出现跨名字空间的属主引用。名字空间作用域的依赖对象可以指定集群作用域或者名字空间作用域的属主。 名字空间作用域的属主必须存在于依赖对象所在的同一名字空间。 如果属主位于不同名字空间,则属主引用被视为不存在,而当检查发现所有属主都已不存在时,依赖对象会被删除。
集群作用域的依赖对象只能指定集群作用域的属主。 在 1.20 及更高版本中,如果一个集群作用域的依赖对象指定了某个名字空间作用域的类别作为其属主, 则该对象被视为拥有一个无法解析的属主引用,因而无法被垃圾收集处理。
在 1.20 及更高版本中,如果垃圾收集器检测到非法的跨名字空间 ownerReference, 或者某集群作用域的依赖对象的 ownerReference 引用某名字空间作用域的类别, 系统会生成一个警告事件,其原因为 OwnerRefInvalidNamespace,involvedObject 设置为非法的依赖对象。你可以通过运行 kubectl get events -A --field-selector=reason=OwnerRefInvalidNamespace 来检查是否存在这类事件。
级联删除
Kubernetes 会检查并删除那些不再拥有属主引用的对象,例如在你删除了 ReplicaSet 之后留下来的 Pod。当你删除某个对象时,你可以控制 Kubernetes 是否去自动删除该对象的依赖对象, 这个过程称为级联删除(Cascading Deletion)。 级联删除有两种类型,分别如下:
- 前台级联删除
- 后台级联删除
你也可以使用 Kubernetes Finalizers 来控制垃圾收集机制如何以及何时删除包含属主引用的资源。
前台级联删除
在前台级联删除中,正在被你删除的属主对象首先进入 deletion in progress 状态。 在这种状态下,针对属主对象会发生以下事情:
- Kubernetes API 服务器将某对象的
metadata.deletionTimestamp字段设置为该对象被标记为要删除的时间点。 - Kubernetes API 服务器也会将
metadata.finalizers字段设置为foregroundDeletion。 - 在删除过程完成之前,通过 Kubernetes API 仍然可以看到该对象。
当属主对象进入删除过程中状态后,控制器删除其依赖对象。控制器在删除完所有依赖对象之后, 删除属主对象。这时,通过 Kubernetes API 就无法再看到该对象。
在前台级联删除过程中,唯一可能阻止属主对象被删除的是那些带有 ownerReference.blockOwnerDeletion=true 字段的依赖对象。 参阅使用前台级联删除 以了解进一步的细节。
后台级联删除
在后台级联删除过程中,Kubernetes 服务器立即删除属主对象,控制器在后台清理所有依赖对象。 默认情况下,Kubernetes 使用后台级联删除方案,除非你手动设置了要使用前台删除, 或者选择遗弃依赖对象。
参阅使用后台级联删除 以了解进一步的细节。
被遗弃的依赖对象
当 Kubernetes 删除某个属主对象时,被留下来的依赖对象被称作被遗弃的(Orphaned)对象。 默认情况下,Kubernetes 会删除依赖对象。要了解如何重载这种默认行为,可参阅 删除属主对象和遗弃依赖对象。
未使用容器和镜像的垃圾收集
kubelet 会每五分钟对未使用的镜像执行一次垃圾收集, 每分钟对未使用的容器执行一次垃圾收集。 你应该避免使用外部的垃圾收集工具,因为外部工具可能会破坏 kubelet 的行为,移除应该保留的容器。
要配置对未使用容器和镜像的垃圾收集选项,可以使用一个 配置文件,基于 KubeletConfiguration 资源类型来调整与垃圾收集相关的 kubelet 行为。
容器镜像生命周期
Kubernetes 通过其镜像管理器(Image Manager) 来管理所有镜像的生命周期, 该管理器是 kubelet 的一部分,工作时与 cadvisor 协同。 kubelet 在作出垃圾收集决定时会考虑如下磁盘用量约束:
HighThresholdPercentLowThresholdPercent
磁盘用量超出所配置的 HighThresholdPercent 值时会触发垃圾收集, 垃圾收集器会基于镜像上次被使用的时间来按顺序删除它们,首先删除的是最近未使用的镜像。 kubelet 会持续删除镜像,直到磁盘用量到达 LowThresholdPercent 值为止。
容器垃圾收集
kubelet 会基于如下变量对所有未使用的容器执行垃圾收集操作,这些变量都是你可以定义的:
MinAge:kubelet 可以垃圾回收某个容器时该容器的最小年龄。设置为0表示禁止使用此规则。MaxPerPodContainer:每个 Pod 可以包含的已死亡的容器个数上限。设置为小于0的值表示禁止使用此规则。MaxContainers:集群中可以存在的已死亡的容器个数上限。设置为小于0的值意味着禁止应用此规则。
除以上变量之外,kubelet 还会垃圾收集除无标识的以及已删除的容器,通常从最近未使用的容器开始。
当保持每个 Pod 的最大数量的容器(MaxPerPodContainer)会使得全局的已死亡容器个数超出上限 (MaxContainers)时,MaxPerPodContainers 和 MaxContainers 之间可能会出现冲突。 在这种情况下,kubelet 会调整 MaxPerPodContainer 来解决这一冲突。 最坏的情形是将 MaxPerPodContainer 降格为 1,并驱逐最近未使用的容器。 此外,当隶属于某已被删除的 Pod 的容器的年龄超过 MinAge 时,它们也会被删除。
说明:
kubelet 仅会回收由它所管理的容器。
配置垃圾收集
你可以通过配置特定于管理资源的控制器来调整资源的垃圾收集行为。 下面的页面为你展示如何配置垃圾收集: