rocketMQ官方组件
RocketMQ Streams
整体架构
RocketMQ Streams是基于RocketMq的轻量级流计算引擎。能以SDK方式被应用依赖,无需部署复杂的流计算服务端即可获得流计算能力。因此具有资源消耗少,扩展性更好、支持流计算算子丰富特点
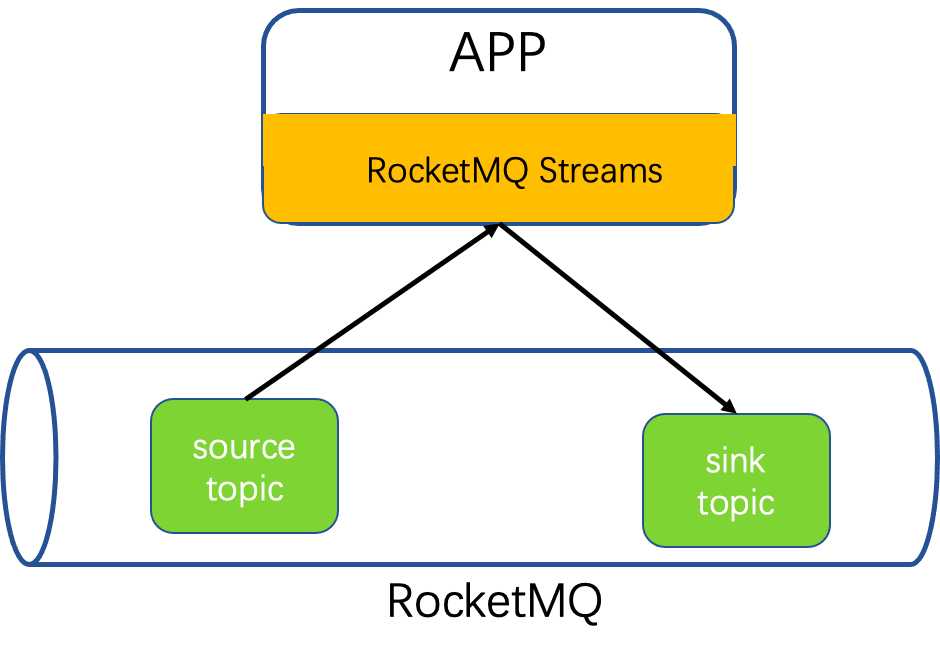
数据从RocketMQ中被RocketMQ-streams消费,经过处理最终被写回到RocketMQ。
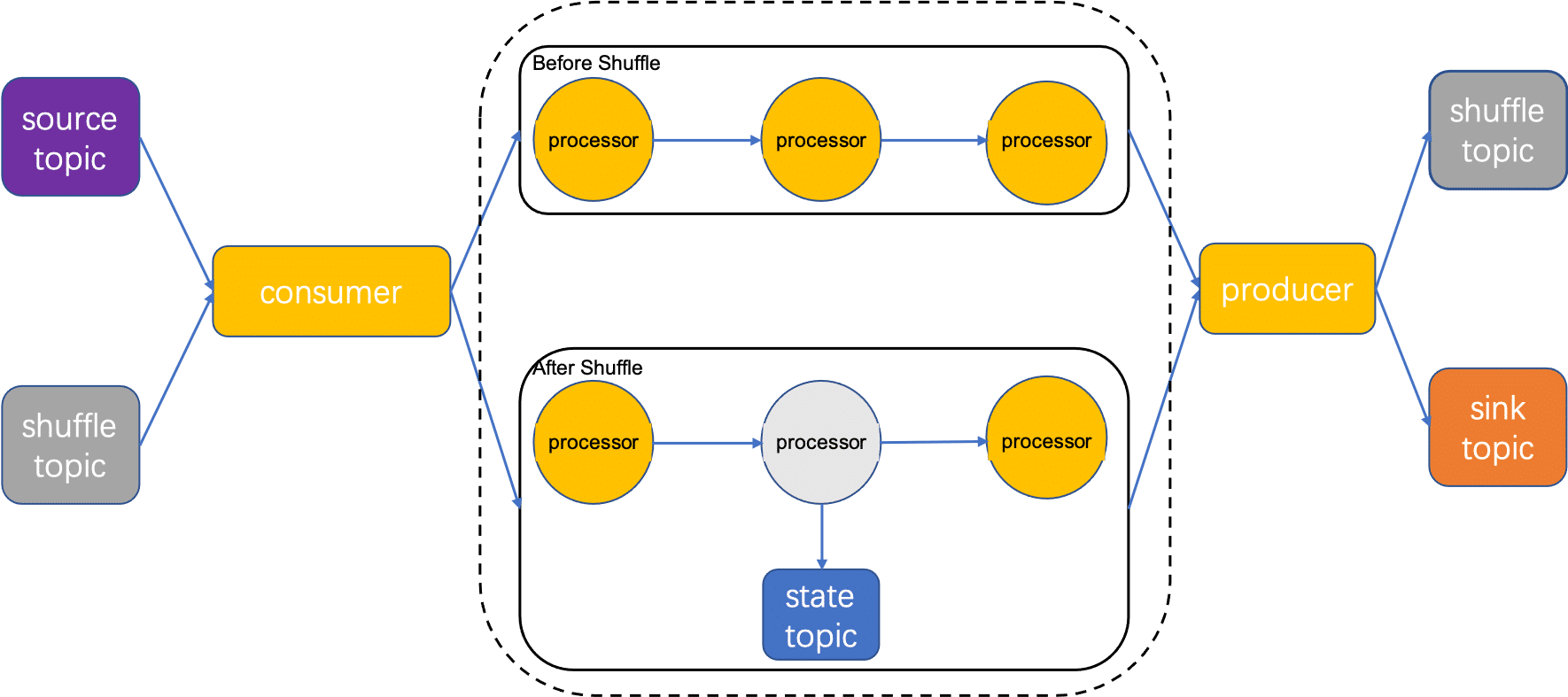
数据被RocketMQ Consumer消费,进入处理拓扑被算子处理,如果流处理任务重含有算子keyBy,则需要将数据按照Key进行分组,将分组数据写入shuffle topic。后续算子从Shffle topic消费。如果还涉及count之类有状态算子,那么计算时需要读写state topic,计算结束后,将结果回到RocketMQ。
消费模型
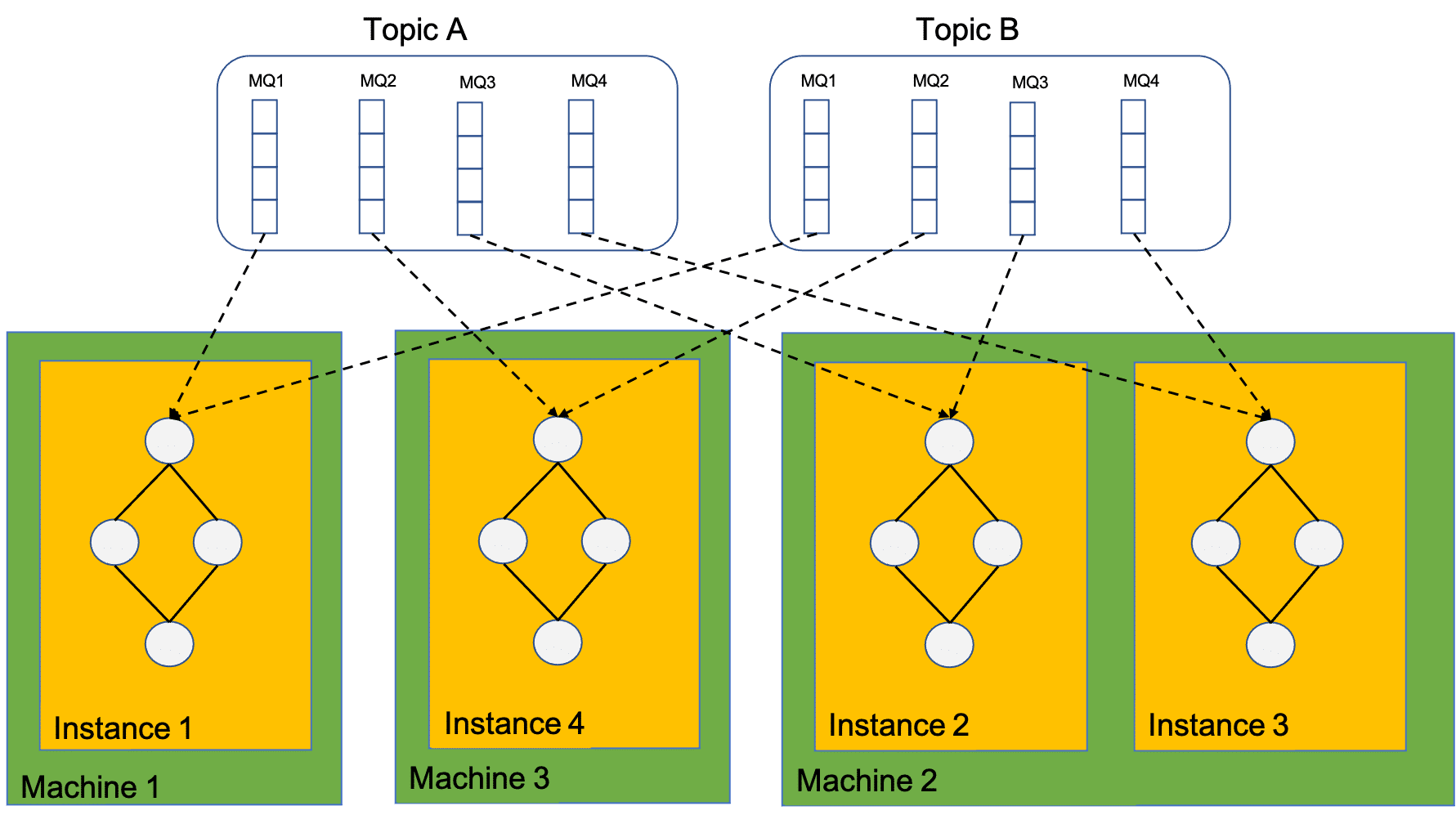
计算实例实际上是依赖了Rocket-streams SDK的client,因此,计算实例消费的MQ依赖RocketMQ reblance分配,计算实例总个数不能大于消费总MQ个数,否则将有部分计算实例处于等待状态消费不到数据。
一个计算实例可以消费多个MQ,一个实例内也只能由一张计算拓步图。
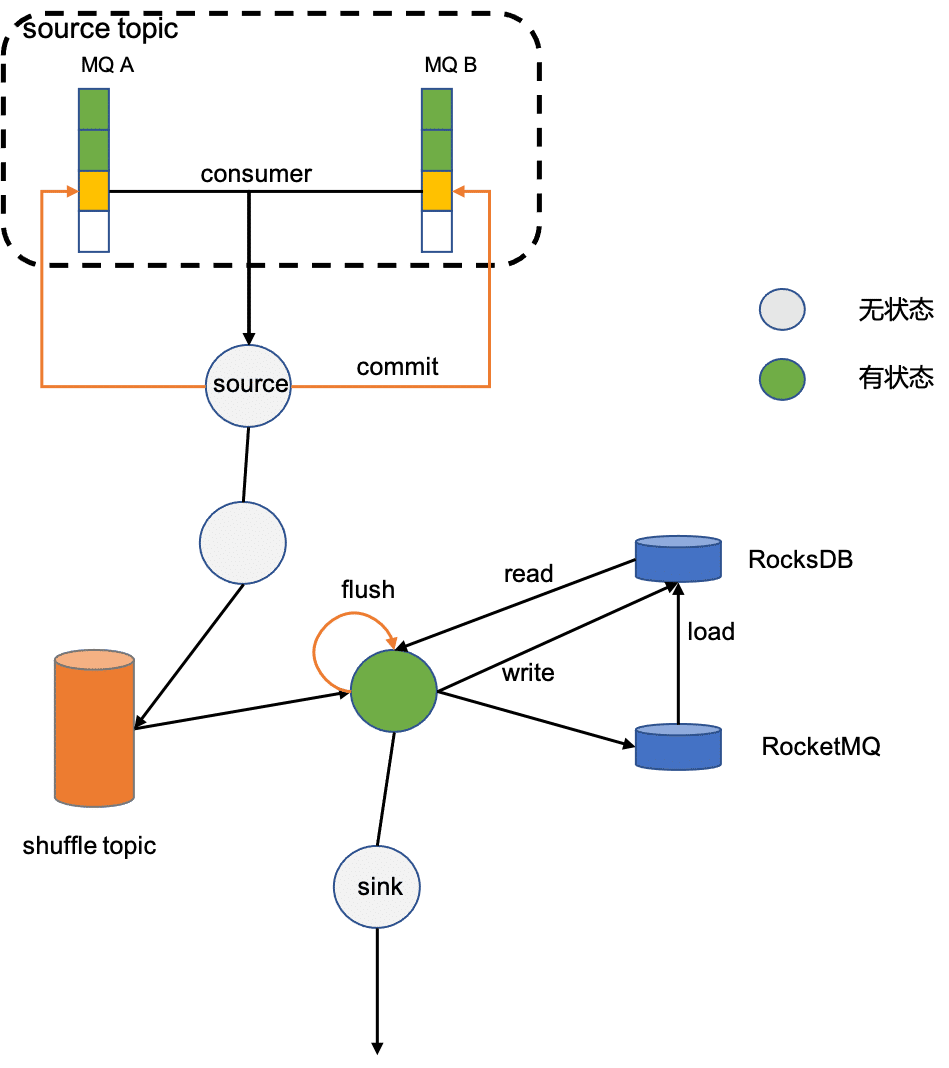
对于有状态的算子,比如count,需要先对count算子金凤分组,然后才能求和。分组算子keyBy会将数据按照分组的key重新写回RocketMQ,并且使相同Key写入同一分区(这一过程称作shuffle),保证这个含有相同的key的数据被同一个消费者消费。状态本地依赖RocksDB加速读取,远程依赖RocketMQ做持久化。
扩缩容
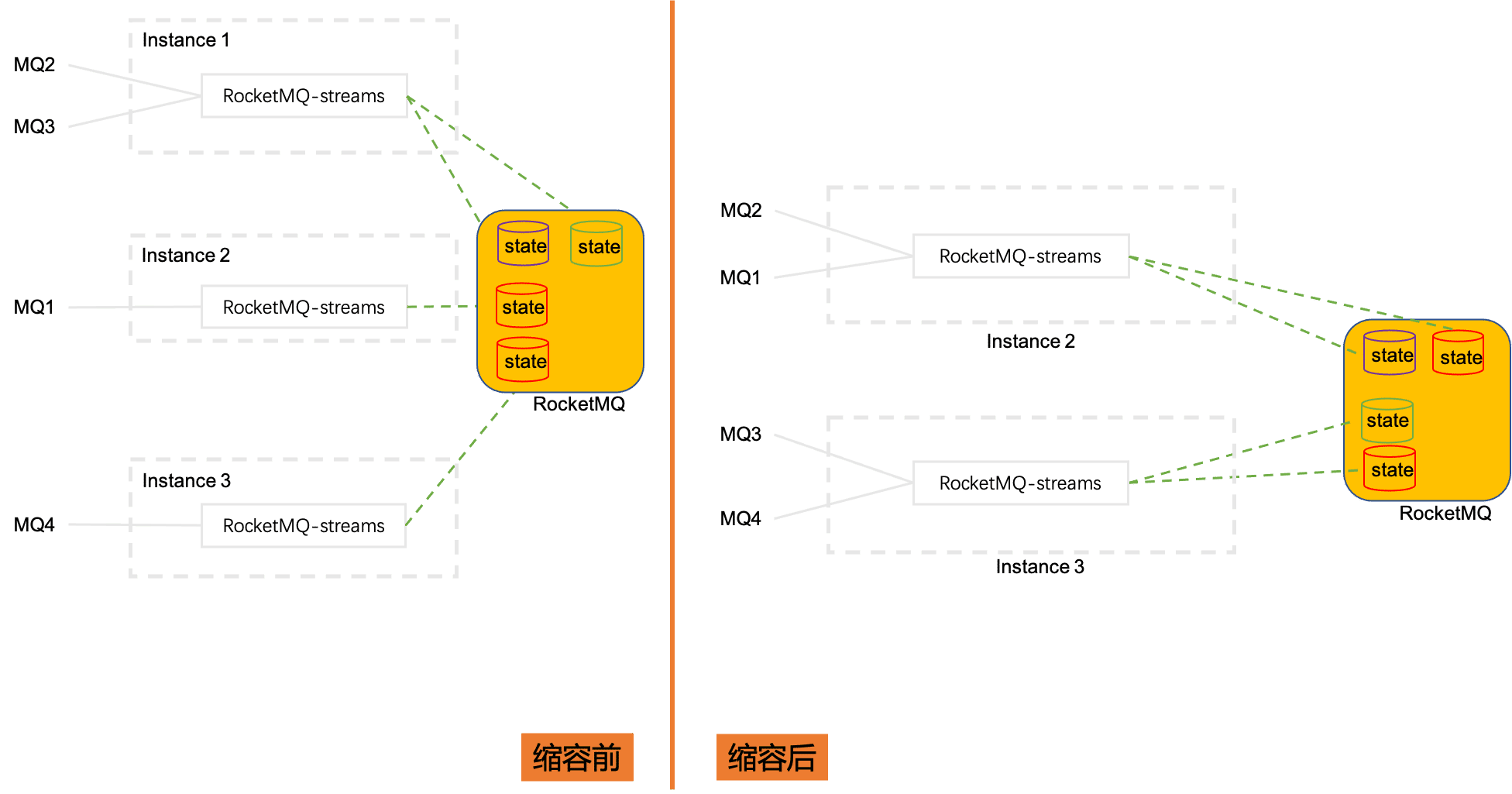
当计算实例从3个缩容到2个,借助于RocketMQ消费模式下的reblance功能,被消费的分片MQ会在计算实例之间重新分配。
Instance1上消费的MQ2和MQ3被分配到Instance2和Instance3上, 这两个MQ的状态数据也需要迁移到Instance2和Instance3上,这也暗示,状态数据是根据源数据分片MQ保存的;扩容则是刚好相反的过程。
RocketMQ Connect
RocketMQ Connect是RocketMQ数据集成重要组件,可将各种系统中的数据通过高效,可靠,流的方式,流入流出到RocketMQ,它是独立于RocketMQ的一个单独的分布式,可扩展,可容错系统, 它具备低延时,高可靠性,高性能,低代码,扩展性强等特点,可以实现各种异构数据系统的连接,构建数据管道,ETL,CDC,数据湖等能力。
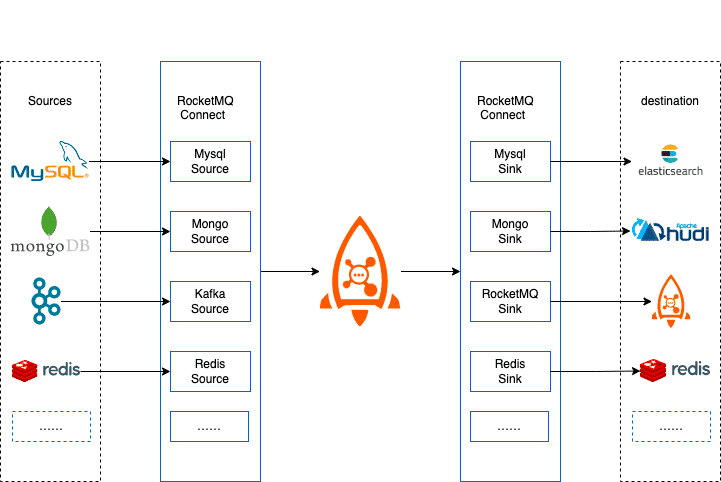
Connector工作原理
RocketMQ Connect是一个独立的的分布式,可伸缩,容错的系统,它主要为RocketMQ提供与各种外部系统的数据的流入流出能力。用户不需要编程,只需要简单的配置即可使用RocketMQ Connect,例如从MySQL同步数据到RocketMQ,只需要配置同步所需的MySQL的账号密码,链接地址,和需要同步的数据库,表名就可以了。
Connector的使用场景
在业务系统中,利用MySQL完善的事务支持,处理数据的增删改,使用ElasticSearch,Solr等实现强大的搜索能力,或者将产生的业务数据同步到数据分析系统,数据湖中(例如hudi),对数据进一步处理从而让数据产生更高的价值。使用RocketMQ Connect很容易实现这样的数据管道的能力,只需要配置3个任务,第一个从MySQL获取数据的任务,第二,三个是从RocketMQ消费数据到ElasticSearch,Hudi的任务,配置3个任务就实现了从MySQL到ElasticSearch,MySQL到hudi的两条数据管道,既可以满足业务中事务的需求,搜索的需求,又可以构建数据湖。
CDC
CDC作为ETL模式之一,可以通过近乎实时的增量捕获数据库的 INSERT、UPDATE,DELETE变化,RocketMQ Connect流试数据传输,具备高可用,低延时等特性,通过Connector很容易实现CDC。
ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
Connector部署
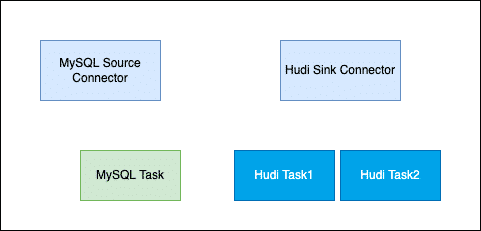
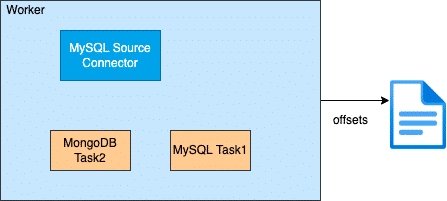
在创建Connector时,一般是通过配置完成的,Connector一般包含逻辑的Connector连接器和执行数据复制的Task即物理线程,如下图所示,俩个Connector连接器和它们对应的运行Task任务。
一个Connector也可以同时运行多个任务,提高Connector的并行度,例如下图所示的Hudi sink Connector有俩个任务每个任务处理不同的数据分片,从而Connector的并行度,进而提高处理性能。
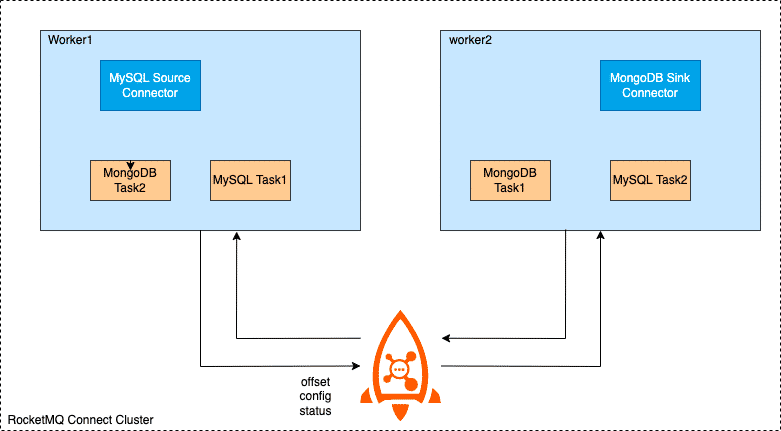
RocketMQ Connect Worker支持俩种运行模式,集群和单机 集群模式,顾名思义,有多个worker节点组成,推荐最少有俩个Worker节点,组成高可用集群。集群之间的配置信息,offset信息,status信息,并触发负载均衡,重新分配急群中的任务,使集群达到负载均衡状态,减少Worker节点或者Worker宕机也会触发负载均衡,从而保障集群中的所有任务都可以均衡的在急群中 的节点正常运行
单机模式,Connector任务运行在单机上,Worker本身没有高可用,任务offset信息持久化在本地。适合一些对高可用没什么要求或者不需要worker保障高可用的场景,例如在K8s急群中,由K8s集群保障高可用。
概念
Connector
连接器,定义数据从哪复制到哪,是从数据源系统读取数据写入RocketMQ,这种是SourceController,或从RocketMMQ读数据写入到目标系统,这种是SinkConnector。Connector决定需要创建任务的数量,从Woker接收配置传递给任务。
Task
Task是Connector任务分片的最小单位,是实际将数据源复制数据到RocketMQ(Source Task),或者将数据从RocketMQ读取数据写到目标系统(SinkTask)真正的执行者,Task是无状态的可以动态启停任务,多个Task是可以并行执行的,Connector复制数据的并行度主要体现在Task数量上。
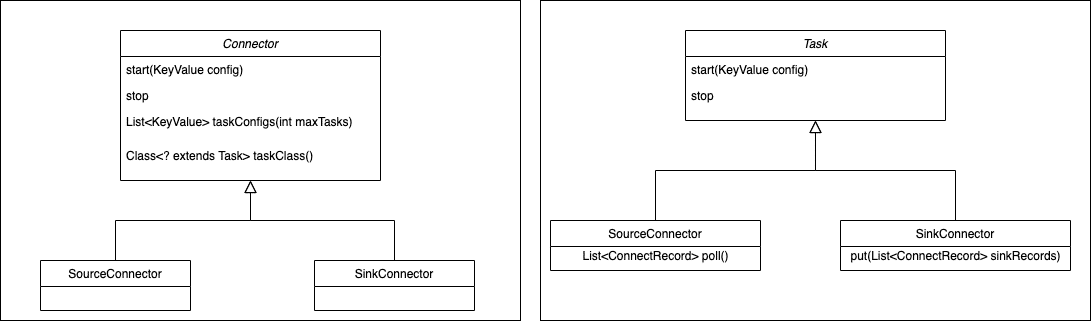
通过Connect的Api也可以看到Connector和Task各自的职责,Connector实现时就已经确定数据复制的流向,Connector接收数据源相关的配置,taskClass获取需要创建的任务类型,通过taskConfigs指定最大任务数量,并且为task分配好配置。task拿到配置以后从数据源取数据写入到目标存储。
通过下面的两张图可以清楚的看到,Connecotr和Task处理基本流程。
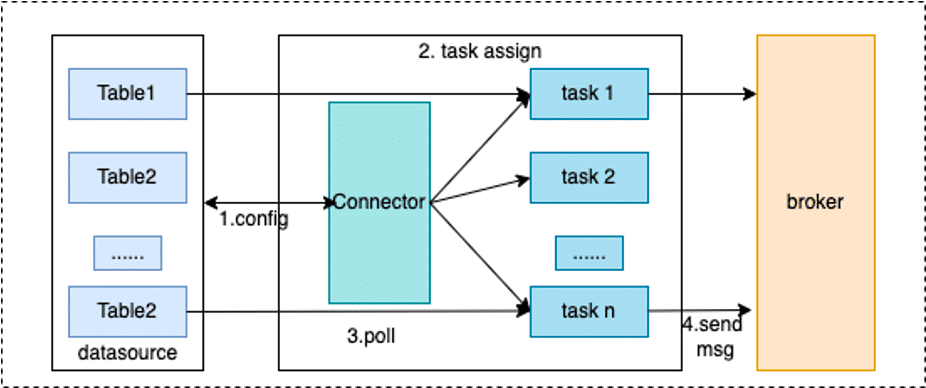
Worker
worker 进程是Connector和Task运行环境,它提供RESTFul能力,接受HTTP请求,将获取到的配置传递给Connector和Task。 除此之外它还负责启动Connector和Task,保存Connector配置信息,保存Task同步数据的位点信息,负载均衡能力,Connect集群高可用,扩缩容,故障处理主要依赖Worker的负载均衡能力实现的。
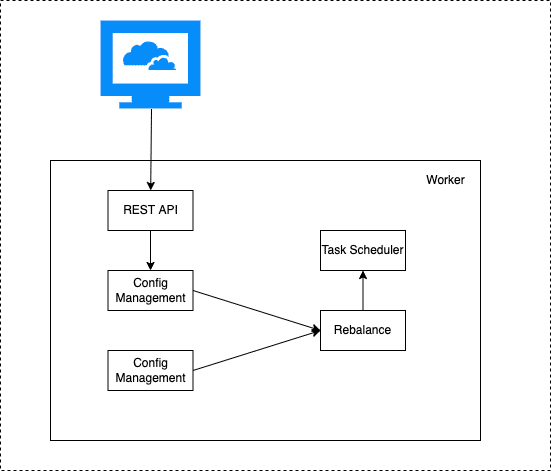
从上面面这张图,看到Worker通过提供的REST Api接收http请求,将接收到的配置信息传递给配置管理服务,配置管理服务将配置保存到本地并同步给其它worker节点,同时触发负载均衡。
RocketMQ EventBride概览
RocketMQ EventBridge 致力于帮助用户构建高可靠、低耦合、高性能的事件驱动架构。在事件驱动架构中,微服务不需要主动订阅外部消息,而是可以把所有触发微服务系统发生改变的入口统一到API,并只需要关注当前微服务自己的业务领域模型定义和设计API,无需通过大量的胶水代码去适配解析外部服务的消息。EventBridge 则会负责将外部服务产生的事件安全的、可靠的适配并投递到当前微服务设计的API。
那什么时候我们使用RocketMQ消息,什么时候使用EventBridge事件? 事件的含义是什么,和消息有什么区别?
消息与事件
事件指过去发生的事,尤其是比较重要的事。
消息与事件关系如下
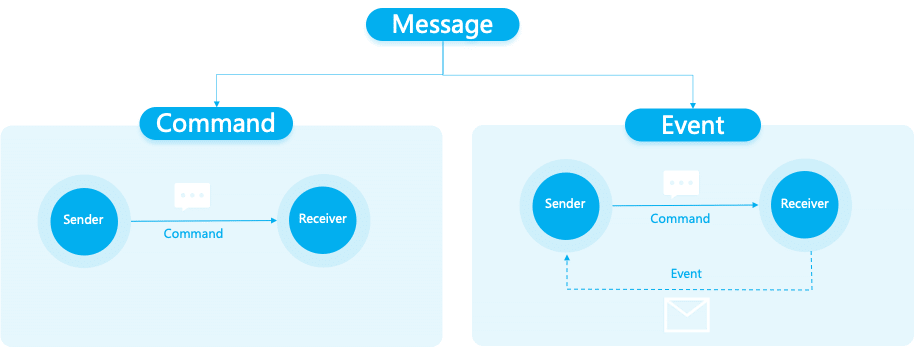
事件的四个特性
已发生
事件,一定是“已发生”的。 “已发生”同时意味着是不可变的。这个特性非常重要,在我们处理事件、分析事件的时候,这就意味着,我们绝对可以相信这些事件,只要是收到的事件,一定是系统真实发生过的行为。
Command,则代表一种操作请求,是否真的发生不可得知,比如:
* 把厨房的灯打开
* 去按下门铃
* 转给A账户10wEvent,则是明确已经发生的事情。比如
* 厨房灯被打开了
* 有人按了门铃
* A账户收到了10w无期望
事件是客观的描述一个事务的状态或属性值变化,但对于如何处理事件本身并没有做任何期望。相比之下,Command和Query则都是有期望的,他们希望系统做出改变或者返回结果,但是Event只是客观描述系统的一个变化。
举个例子: 交通信号灯,从绿灯变成黄灯,只是描述了一个客观事实,本身并没有客观期望。在不同国家地区,对这个事件赋予了不同的期望。 比如,在日本黄灯等于红灯,而在俄罗斯闯黄灯是被默许的。
与Command消息对比:
- 事件:有点像"市场经济",商品被生产出来,摆放在商场的大橱窗里,消费者谁看着觉得好就买回去,如果一直没人买,商品可能就过期浪费了。
- Command消息:则有点像"计划经济",按需生产,指定分配对象,也很少产生浪费。
天然有序且唯一
同一个实体,不能同时发生A又发生B,必有先后关系,如果是,则这俩个事件属于不同类型的事件。
比如:针对同一个交通信号灯,不能既变成绿灯,又变成红灯,同一时刻,只能变成一种状态。 如果我们看到了两个内容一样的事件,那么一定是发生了两次,而且一次在前,一次在后。这对于我们处理数据最终一致性、以及系统行为分析(比如ABA场景)都很有价值:我们看到的,不光光是系统的一个最终结果,而是看到变成这个结果之前的,一系列中间过程。
具象化
事件会尽可能的把案发现场完整的记录下来,因为事件不知道消费者会如何使用它,所以会做到尽量的详尽。包括:
什么时候发生的事件?
谁产生的?
是什么类型的事件?
事件的内容是什么?内容的结构是什么?
... ...
对比我们常见的消息,因为上下游一般是确定的,常常为了性能和传输效率,则会做到尽可能的精简,只要满足“计划经济”指定安排的消费者需求即可。
典型应用场景
事件通知
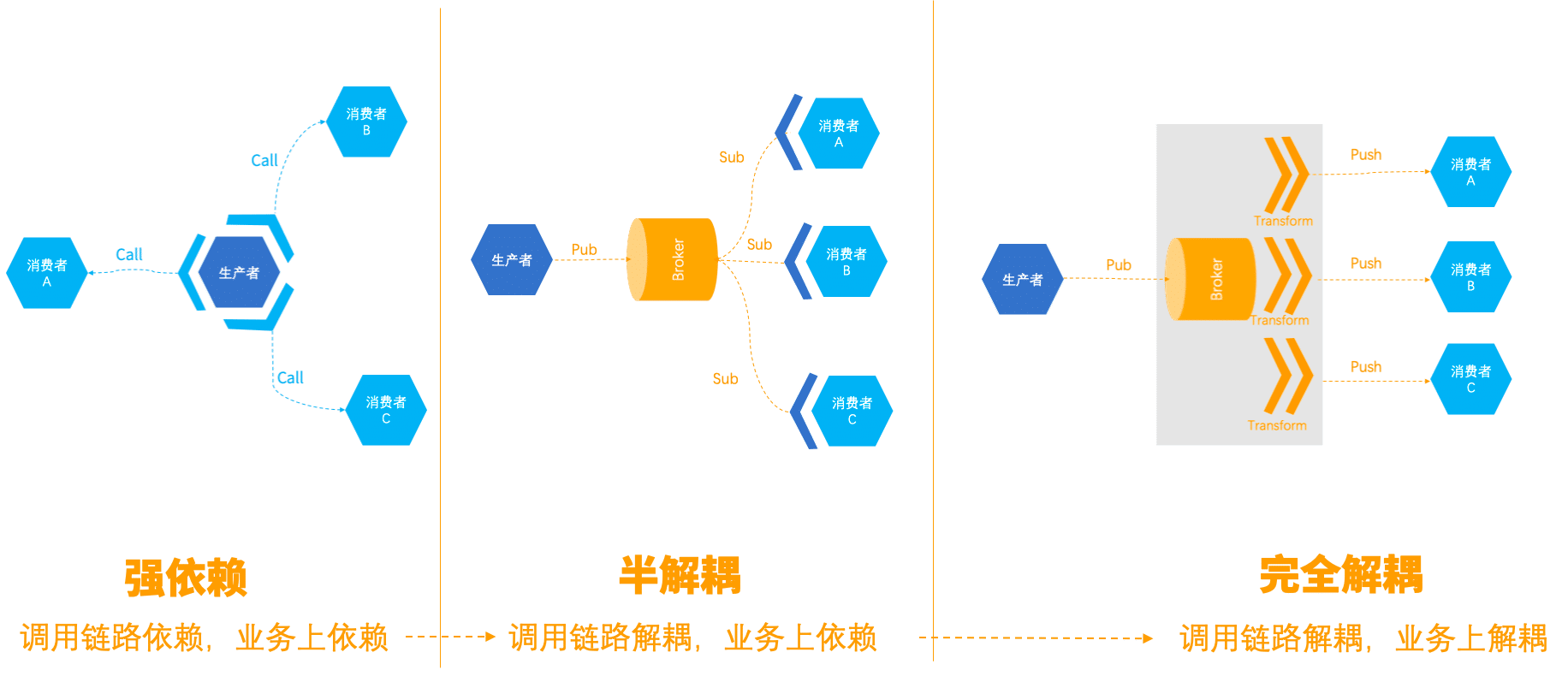
微服务中,我们常常会遇到需要把一个微服中产生的消息,通知给其他消费者。这里我们对比三种方式:
A:强依赖方式
生产者主动调用消费者的微服务,并适配消费者的API。这种设计无疑是非常糟糕的,生产者强依赖消费者,深度耦合。万一某个消费者出现异常且未做有效隔离,极容易导致整个服务Hang起。有新的消费者进来,扩展性也极差。
B:半解耦方式
生产者将消息发送到消息服务,消息订阅消息服务获取消息,并将消息解析成自己业务领域模型中需要的数据格式。这种方式做到了调用链路上的解耦,极大降低了系统风险,但是对于消费者来说,依旧需要去理解和 解析生产者的业务语义,将消息转换成自己业务领域内需要的格式。这种方式下,当消费者需要订阅多个生产者数据的时候,需要用大量胶水代码,为每一个生产者产生的消息做适配。另外,当上游生产者的消息格式发生变化时,也会存在风险和运维成本。
C:完全解耦方式
这方式下,消费者不需要引入SDK订阅Broker,只需按照自己的业务领域模型设计API,消息服务会将上游的事件,过滤并转化成API需要的事件格式。既没有调用链路上的依赖,也没有业务上的依赖。当上游生产者的事件数据发生变化时,消息服务会做兼容性校验,可以拒绝生产者发送事件或则进行告警。
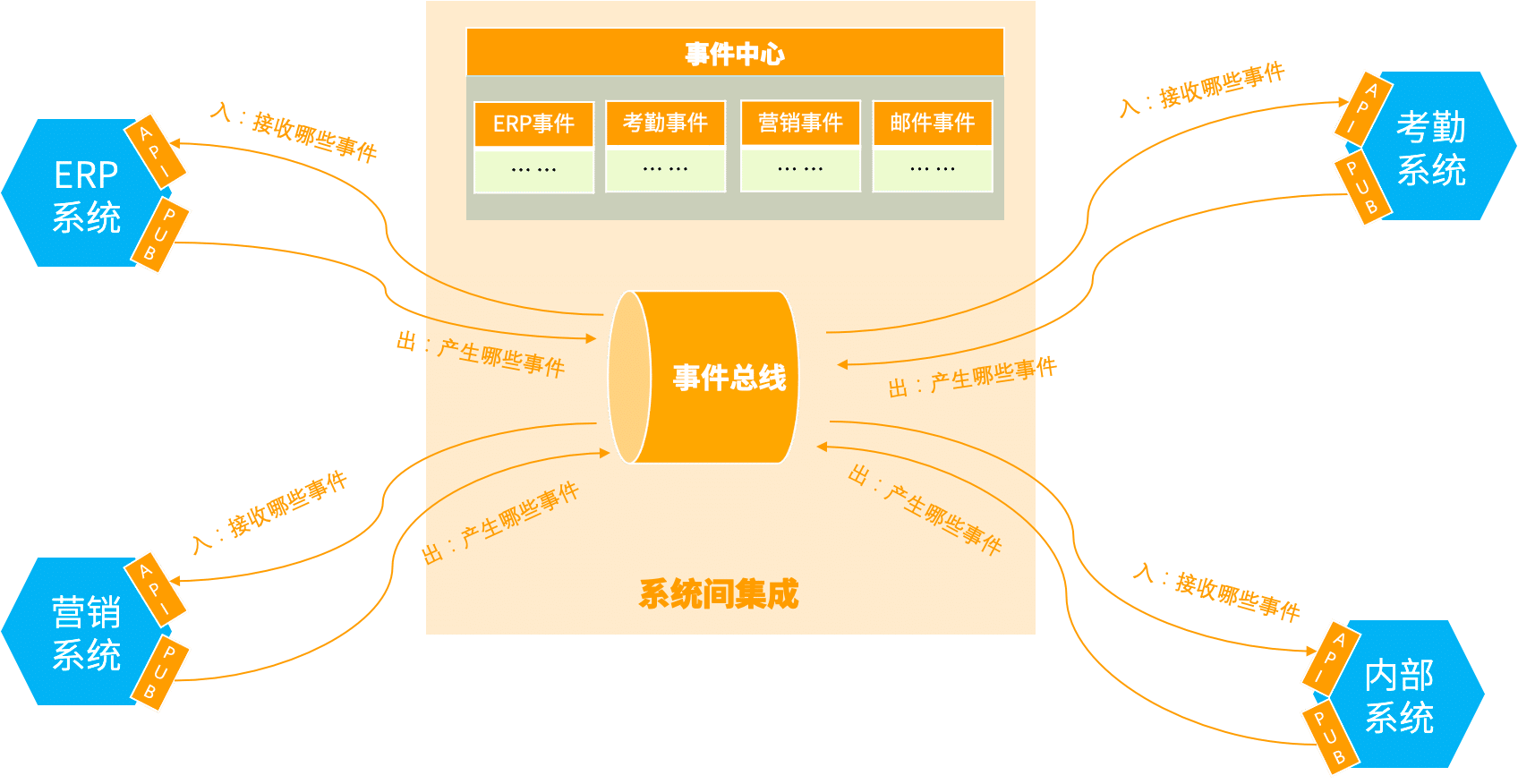
系统间集成
事件通知场景主要面向一个产品内部,各个微服务之间事件通信,系统间集成则是主要面向多个产品之间的事件通信。在一个企业中,我们常常会用到多款产品,而且很多产品可能并不是我们自己开发的,而是购买的外部SaaS服务。这个时候,如果我们希望同事间在不同外部SasS服务。这个时候,如果我们希望事件在不同外部SaaS产品之间流转是比较困难的,因为这些外部SaaS产品不是我们自己开发的,无法轻易修改其中的代码。EventBridge提供事件中心能力,能够帮助手机各个产品产生的事件,并很好的组织管理起来,就像大卖场橱窗里的商品,精心摆放准备好,配备介绍说明书,供消费者挑选,同时提供送货上门服务。
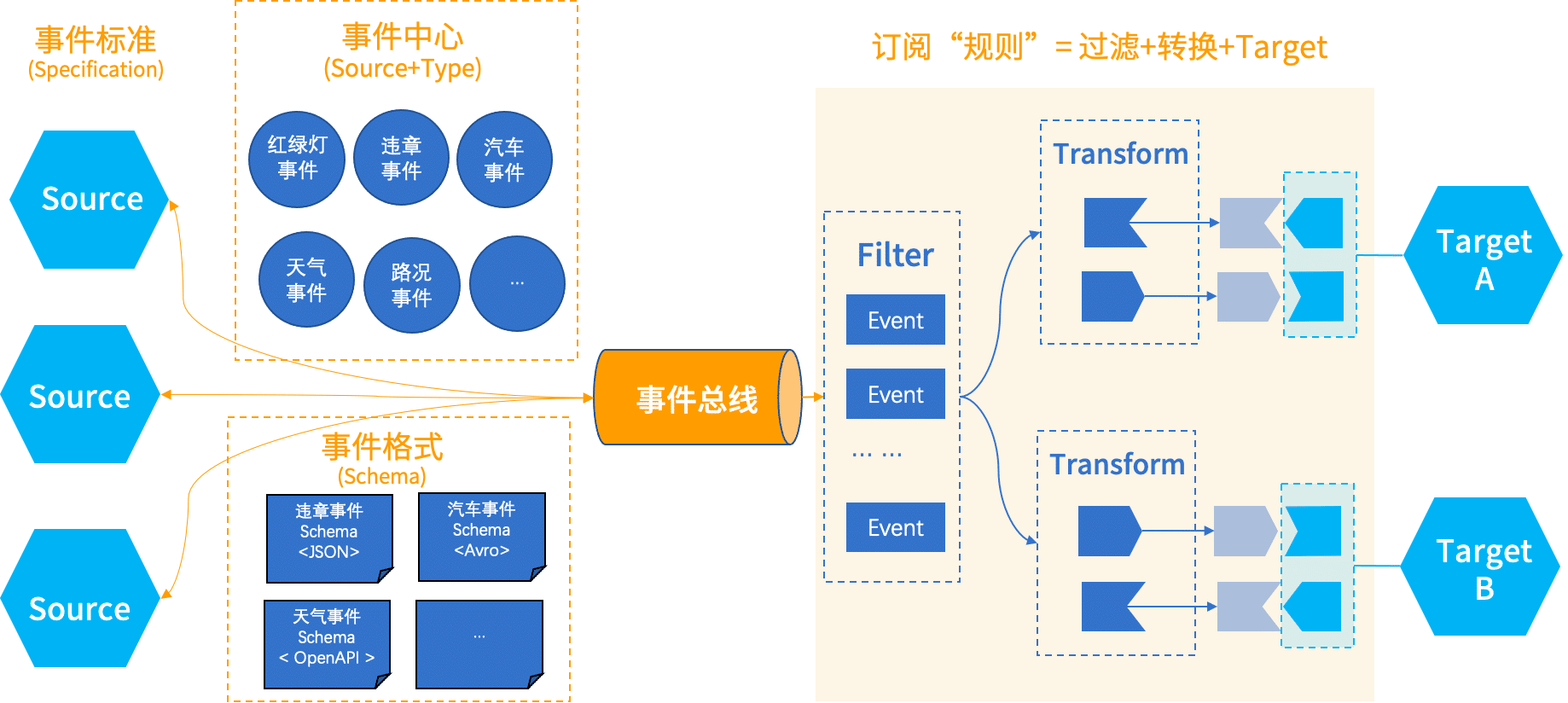
如何工作
为了解决上述俩个应用场景中提到的问题,EventBridge从5个方面入手
- 确定事件标准:因为事件不是给自己看的,而是给所有人看的。它没有明确的消费者,所有都是潜在的消费者。所以,我们需要规范化事件的定义,让所有人都能看得懂,一目了然。目前CNCF旗下的CloudEvent,以逐渐成为广泛的事实标准,因此,我们选取了CloudEvent 作为我们的EventBridge的事件标准。
- 建立时间中心:事件中心里面所有系统,注册上来的各种事件,这个就像我们上面说的市场经济大卖场,里面琳琅满目分类摆放了各种各样的事件,所有人即使不买,也都可以进来瞧一瞧看一看,有哪些时间可能是我需要的,那就可以买回去。
- 定义事件格式: 事件格式用来描述事件的具体内容。这相当于市场经济的一个买卖契约。生产者发送的事件格式是什么,得确定下来,不能总是变;消费者以什么格式接收事件也得确定下来,不然整个市场就乱套了。
- 订阅“规则”:我们得给消费者一个,把投递事件到目标端的能力,并且投递前可以对事件进行过滤和转换,让它可以适配目标端API接收参数的格式,我们把这个过程叫做创建订阅规则。
- 事件总线:最后我们还得有一个存储事件的地方,就是图中最中间的事件总线
核心概念
理解EventBridge中的核心概念,能帮助我们更好的分析和使用EventBridge。本文重点介绍下EventBridge中包含的术语:
- EventSource:事件源。用于管理发送到EventBridge的事件,所有发送到EventBridge中的事件都必须标注事件源名称信息,对应CloudEvent事件体中的source字段。
- EventBus:事件总线。用于存储发送到EventBridge的事件。
- EventRule:事件规则。当消费者需要订阅事件时,可以通过规则配置过滤和转换信息,将事件推送到指定的目标端。
- FilterPattern:事件过滤模式,用于在规则中配置过滤出目标端需要的事件。
- Transform:事件转换,将事件格式转换成目标端需要的数据格式。
- EventTarget:事件目标端,即我们真正的事件消费者。
下面,我们具体展开:
EventSource
事件源,代表事件发生的源头,用来描述一类事件,一般与微服务系统一一对应。比如:交易事件源、考勤事件源等等。事件源,是对事件的一个大的分类,一个事件源下面,往往会包含多事件类型(type),比如交易事件源下面,可能包含:下单事件、支付事件、退货事件等等。
另外,需要值得注意的是,事件源并不用来描述发生事件的实体,取而代之的是,在CloudEvent中,我们一般选用subject来表示产生这个事件的实体资源。事件资源有点像市场经济大卖场的大类分区,例如:生鲜区、日化日用区、家用电器区等等。在事件中心这个"大卖场",我们可以通过事件源快速的找到我们需要的事件。
EventBus
事件总线是存储事件的地方,其下可以有多种实现,包括Local、RocketMQ、Kafka等。
事件生产者发送事件的时候,必须指定事件总线。事件总线是EventBridge的一等公民,其他所有资源都围绕事件总线形成逻辑上的隔离,即:事件源、事件规则必须都隶属于某一个事件总线下。不同事件总线下的事件源和事件规则可以重名,但是同一个事件总线下的事件源和规则必须不重名。
EventRule
当消费者需要订阅事件时,可以通过规则配置过滤和转换信息,将时间推到指定的目标端。所以时间规则包含三部分:事件过滤+事件转换+事件目标
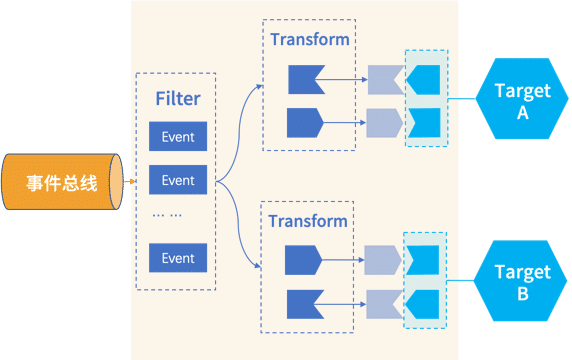
FilterPattern
通过事件过滤模式,我们可以对事件总线上的事件进行过滤,只将目标端需要的事件推送过去,以减少不必要的开销,同时减轻消费者Taget端的压力。目前EventBridge支持的事件过滤能力包括
- 指定值匹配
- 前缀匹配
- 后缀匹配
- 除外匹配
- 数值匹配
- 数组匹配
- 以及复杂的组合逻辑匹配
(详细介绍待见其他文章)
Transform
生产者的事件可能会同时被多个消费者订阅,但不同消费者需要的数据格式往往不同。这是需要我们将生产者的事件转换成消费者Target端需要的事件格式。目前EventBridge支持的事件转换能力包括:
- 完整事件:不做转换,直接投递原生 CloudEvents;
- 部分事件:通过 JsonPath 语法从 CloudEvents 中提取出需要投递到事件目标的内容;
- 常量:事件只起到触发器的作用,投递内容为常量;
- 模板转换器:通过定义模板,灵活地渲染投递出去的事件格式;