EBPF
“eBPF 是我见过的 Linux 中最神奇的技术,没有之一,已成为 Linux 内核中顶级子模块,从 tcpdump 中用作网络包过滤的经典 cbpf,到成为通用 Linux 内核技术的 eBPF,已经完成华丽蜕变,为应用与神奇的内核打造了一座桥梁,在系统跟踪、观测、性能调优、安全和网络等领域发挥重要的角色。为 Service Mesh 打造了具备 API 感知和安全高效的容器网络方案 Cilium,其底层正是基于 eBPF 技术”
BPF
BPF(Berkeley Packet Filter ),中文翻译为伯克利包过滤器,是类 Unix 系统上数据链路层的一种原始接口,提供原始链路层封包的收发。1992 年,Steven McCanne 和 Van Jacobson 写了一篇名为《BSD数据包过滤:一种新的用户级包捕获架构》的论文。在文中,作者描述了他们如何在 Unix 内核实现网络数据包过滤,这种新的技术比当时最先进的数据包过滤技术快 20 倍。BPF 在数据包过滤上引入了两大革新:
- 一个新的虚拟机 (VM) 设计,可以有效地工作在基于寄存器结构的 CPU 之上;
- 应用程序使用缓存只复制与过滤数据包相关的数据,不会复制数据包的所有信息。这样可以最大程度地减少BPF 处理的数据;
由于这些巨大的改进,所有的 Unix 系统都选择采用 BPF 作为网络数据包过滤技术,直到今天,许多 Unix 内核的派生系统中(包括 Linux 内核)仍使用该实现。
tcpdump 的底层采用 BPF 作为底层包过滤技术,我们可以在命令后面增加 ”-d“ 来查看 tcpdump 过滤条件的底层汇编指令。
$ tcpdump -d 'ip and tcp port 8080'
(000) ldh [12]
(001) jeq #0x800 jt 2 jf 12
(002) ldb [23]
(003) jeq #0x6 jt 4 jf 12
(004) ldh [20]
(005) jset #0x1fff jt 12 jf 6
(006) ldxb 4*([14]&0xf)
(007) ldh [x + 14]
(008) jeq #0x1f90 jt 11 jf 9
(009) ldh [x + 16]
(010) jeq #0x1f90 jt 11 jf 12
(011) ret #262144
(012) ret #0tcpdump 底层汇编指令
BPF 工作在内核层,BPF 的架构图如下 [来自于bpf-usenix93]:
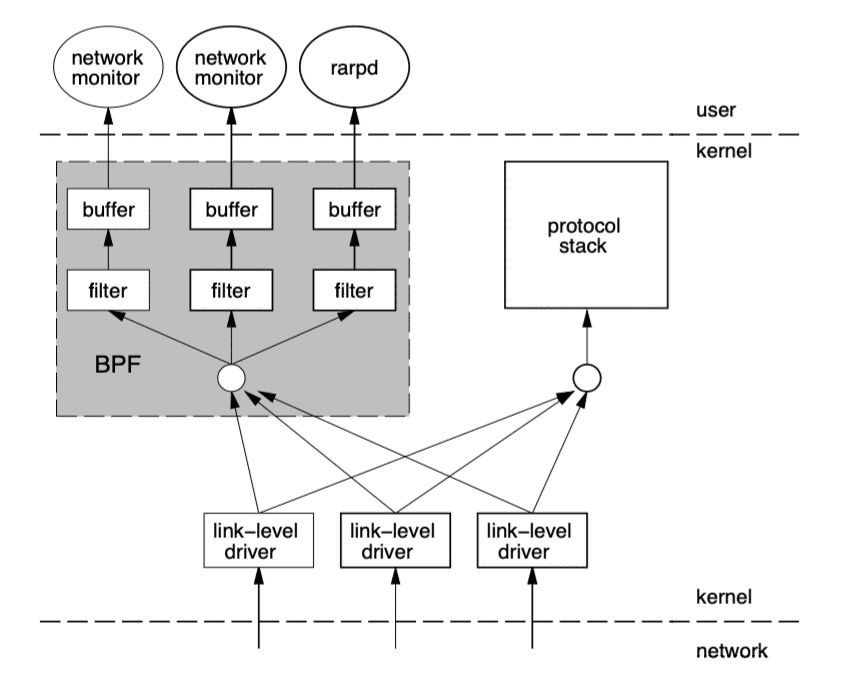
eBPF
介绍
2014 年初,Alexei Starovoitov 实现了 eBPF(extended Berkeley Packet Filter)。经过重新设计,eBPF 演进为一个通用执行引擎,可基于此开发性能分析工具、软件定义网络等诸多场景。eBPF 最早出现在 3.18 内核中,此后原来的 BPF 就被称为经典 BPF,缩写 cBPF(classic BPF),cBPF 现在已经基本废弃。现在,Linux 内核只运行 eBPF,内核会将加载的 cBPF 字节码透明地转换成 eBPF 再执行。
eBPF 新的设计针对现代硬件进行了优化,所以 eBPF 生成的指令集比旧的 BPF 解释器生成的机器码执行得更快。扩展版本也增加了虚拟机中的寄存器数量,将原有的 2 个 32 位寄存器增加到 10 个 64 位寄存器。由于寄存器数量和宽度的增加,开发人员可以使用函数参数自由交换更多的信息,编写更复杂的程序。总之,这些改进使 eBPF 版本的速度比原来的 BPF 提高了 4 倍。
| 维度 | cBPF | eBPF |
|---|---|---|
| 内核版本 | Linux 2.1.75(1997年) | Linux 3.18(2014年)[4.x for kprobe/uprobe/tracepoint/perf-event] |
| 寄存器数目 | 2个:A, X | 10个:R0–R9, 另外 R10 是一个只读的帧指针 |
| 寄存器宽度 | 32位 | 64位 |
| 存储 | 16 个内存位: M[0–15] | 512 字节堆栈,无限制大小的 “map” 存储 |
| 限制的内核调用 | 非常有限,仅限于 JIT 特定 | 有限,通过 bpf_call 指令调用 |
| 目标事件 | 数据包、 seccomp-BPF | 数据包、内核函数、用户函数、跟踪点 PMCs 等 |
表格 1-1 cBPF 与 eBPF 对比
eBPF 在 Linux 3.18 版本以后引入,并不代表只能在内核 3.18+ 版本上运行,低版本的内核升级到最新也可以使用 eBPF 能力,只是可能部分功能受限,比如我就是在 Linux 发行版本 CentOS Linux release 7.7.1908 内核版本 3.10.0-1062.9.1.el7.x86_64 上运行 eBPF 在生产环境上搜集和排查网络问题。
eBPF 实现的最初目标是优化处理网络过滤器的内部 BPF 指令集。当时,BPF 程序仍然限于内核空间使用,只有少数用户空间程序可以编写内核处理的 BPF 过滤器,例如:tcpdump和 seccomp。时至今日,这些程序仍基于旧的 BPF 解释器生成字节码,但内核中会将这些指令转换为高性能的表示。
2014 年 6 月,eBPF 扩展到用户空间,这也成为了 BPF 技术的转折点。正如 Alexei 在提交补丁的注释中写到:“这个补丁展示了 eBPF 的潜力”。当前,eBPF 不再局限于网络栈,已经成为内核顶级的子系统。eBPF 程序架构强调安全性和稳定性,看上去更像内核模块,但与内核模块不同,eBPF 程序不需要重新编译内核,并且可以确保 eBPF 程序运行完成,而不会造成系统的崩溃。
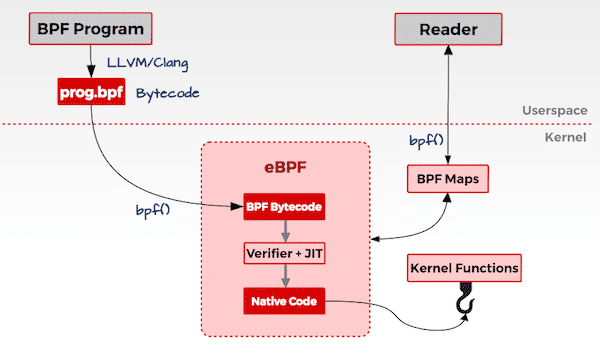
简述概括, eBPF 是一套通用执行引擎,提供了可基于系统或程序事件高效安全执行特定代码的通用能力,通用能力的使用者不再局限于内核开发者;eBPF 可由执行字节码指令、存储对象和 Helper 帮助函数组成,字节码指令在内核执行前必须通过 BPF 验证器 Verfier 的验证,同时在启用 BPF JIT 模式的内核中,会直接将字节码指令转成内核可执行的本地指令运行。
同时,eBPF 也逐渐在观测(跟踪、性能调优等)、安全和网络等领域发挥重要的角色。Facebook、NetFlix 、CloudFlare 等知名互联网公司内部广泛采用基于 eBPF 技术的各种程序用于性能分析、排查问题、负载均衡、防范 DDoS 攻击,据相关信息显示在 Facebook 的机器上内置一系列 eBPF 的相关工具。
相对于系统的性能分析和观测,eBPF 技术在网络技术中的表现,更是让人眼前一亮,BPF 技术与 XDP(eXpress Data Path) 和 TC(Traffic Control) 组合可以实现功能更加强大的网络功能,更可为 SDN 软件定义网络提供基础支撑。XDP 只作用与网络包的 Ingress 层面,BPF 钩子位于网络驱动中尽可能早的位置,无需进行原始包的复制就可以实现最佳的数据包处理性能,挂载的 BPF 程序是运行过滤的理想选择,可用于丢弃恶意或非预期的流量、进行 DDOS 攻击保护等场景;而 TC Ingress 比 XDP 技术处于更高层次的位置,BPF 程序在 L3 层之前运行,可以访问到与数据包相关的大部分元数据,是本地节点处理的理想的地方,可以用于流量监控或者 L3/L4 的端点策略控制,同时配合 TC egress 则可实现对于容器环境下更高维度和级别的网络结构。
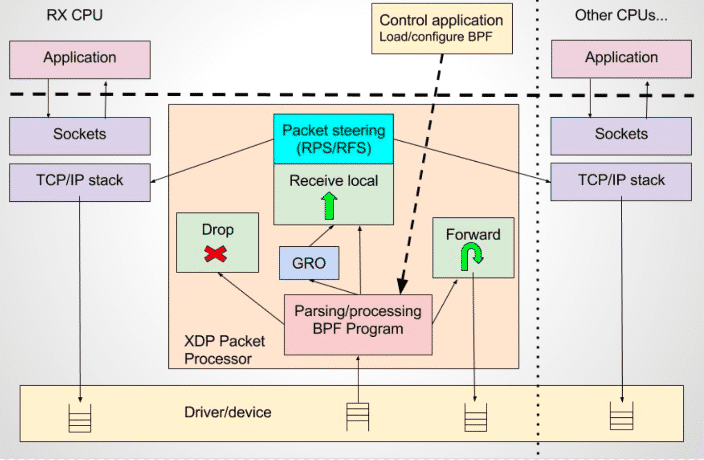
eBPF 相关的知名的开源项目包括但不限于以下:
- Facebook 高性能 4 层负载均衡器 Katran;
- Cilium 为下一代微服务 ServiceMesh 打造了具备API感知和安全高效的容器网络方案;底层主要使用 XDP 和 TC 等相关技术;
- IO Visor 项目开源的 BCC、 BPFTrace 和 Kubectl-Trace:BCC 提供了更高阶的抽象,可以让用户采用 Python、C++ 和 Lua 等高级语言快速开发 BPF 程序;BPFTrace 采用类似于 awk 语言快速编写 eBPF 程序;Kubectl-Trace 则提供了在 kubernetes 集群中使用 BPF 程序调试的方便操作;
- CloudFlare 公司开源的 eBPF Exporter 和 bpf-tools:eBPF Exporter 将 eBPF 技术与监控 Prometheus 紧密结合起来;bpf-tools 可用于网络问题分析和排查;
越来越多的基于 eBPF 的项目如雨后脆笋一样开始蓬勃发展,而且逐步在社区中异军突起,成为一道风景线。比如 IO Visor 项目的 BCC 工具,为性能分析和观察提供了更加丰富的工具集
架构
基于 Linux 系统的观测工具中,eBPF 有着得天独厚的优势,高效、生产安全且内核中内置,特别的可以在内核中完成数据分析聚合比如直方图,与将数据发送到用户空间分析聚合相比,能够节省大量的数据复制传递带来的 CPU 消耗。
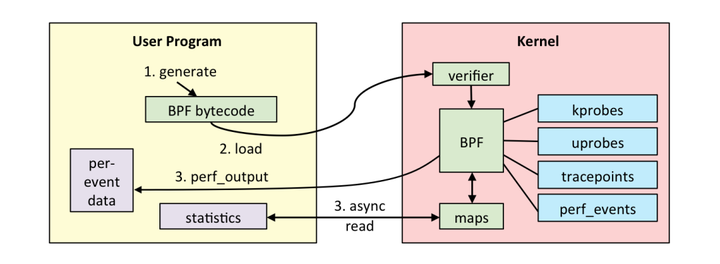
eBPF 分为用户空间程序和内核程序两部分:
- 用户空间程序负责加载 BPF 字节码至内核,如需要也会负责读取内核回传的统计信息或者事件详情;
- 内核中的 BPF 字节码负责在内核中执行特定事件,如需要也会将执行的结果通过 maps 或者 perf-event 事件发送至用户空间;
其中用户空间程序与内核 BPF 字节码程序可以使用 map 结构实现双向通信,这为内核中运行的 BPF 字节码程序提供了更加灵活的控制。
用户空间程序与内核中的 BPF 字节码交互的流程主要如下:
- 我们可以使用 LLVM 或者 GCC 工具将编写的 BPF 代码程序编译成 BPF 字节码;
- 然后使用加载程序 Loader 将字节码加载至内核;内核使用验证器(verfier) 组件保证执行字节码的安全性,以避免对内核造成灾难,在确认字节码安全后将其加载对应的内核模块执行;BPF 观测技术相关的程序程序类型可能是 kprobes/uprobes/tracepoint/perf_events 中的一个或多个,其中:
- kprobes:实现内核中动态跟踪。kprobes 可以跟踪到 Linux 内核中的导出函数入口或返回点,但是不是稳定 ABI 接口,可能会因为内核版本变化导致,导致跟踪失效。
- uprobes:用户级别的动态跟踪。与 kprobes 类似,只是跟踪用户程序中的函数。
- tracepoints:内核中静态跟踪。tracepoints 是内核开发人员维护的跟踪点,能够提供稳定的 ABI 接口,但是由于是研发人员维护,数量和场景可能受限。
- perf_events:定时采样和 PMC。
内核中运行的 BPF 字节码程序可以使用两种方式将测量数据回传至用户空间
- maps 方式可用于将内核中实现的统计摘要信息(比如测量延迟、堆栈信息)等回传至用户空间;
- perf-event 用于将内核采集的事件实时发送至用户空间,用户空间程序实时读取分析;
如无特殊说明,本文中所说的 BPF 都是泛指 BPF 技术。
eBPF 的限制
eBPF 技术虽然强大,但是为了保证内核的处理安全和及时响应,内核中的 eBPF 技术也给予了诸多限制,当然随着技术的发展和演进,限制也在逐步放宽或者提供了对应的解决方案。
- eBPF 程序不能调用任意的内核参数,只限于内核模块中列出的 BPF Helper 函数,函数支持列表也随着内核的演进在不断增加。
- eBPF 程序不允许包含无法到达的指令,防止加载无效代码,延迟程序的终止。
- eBPF 程序中循环次数限制且必须在有限时间内结束,这主要是用来防止在 kprobes 中插入任意的循环,导致锁住整个系统;解决办法包括展开循环,并为需要循环的常见用途添加辅助函数。Linux 5.3 在 BPF 中包含了对有界循环的支持,它有一个可验证的运行时间上限。
- eBPF 堆栈大小被限制在 MAX_BPF_STACK,截止到内核 Linux 5.8 版本,被设置为 512;参见 include/linux/filter.h,这个限制特别是在栈上存储多个字符串缓冲区时:一个char[256]缓冲区会消耗这个栈的一半。目前没有计划增加这个限制,解决方法是改用 bpf 映射存储,它实际上是无限的。
/* BPF program can access up to 512 bytes of stack space. */
#define MAX_BPF_STACK 512
- eBPF 字节码大小最初被限制为 4096 条指令,截止到内核 Linux 5.8 版本, 当前已将放宽至 100 万指令( BPF_COMPLEXITY_LIMIT_INSNS),参见:include/linux/bpf.h,对于无权限的BPF程序,仍然保留 4096 条限制 ( BPF_MAXINSNS );新版本的 eBPF 也支持了多个 eBPF 程序级联调用,虽然传递信息存在某些限制,但是可以通过组合实现更加强大的功能。
#define BPF_COMPLEXITY_LIMIT_INSNS 1000000 /* yes. 1M insns */
eBPF 与内核模块对比
在 Linux 观测方面,eBPF 总是会拿来与 kernel 模块方式进行对比,eBPF 在安全性、入门门槛上比内核模块都有优势,这两点在观测场景下对于用户来讲尤其重要。
| 维度 | Linux 内核模块 | eBPF |
|---|---|---|
| kprobes/tracepoints | 支持 | 支持 |
| 安全性 | 可能引入安全漏洞或导致内核 Panic | 通过验证器进行检查,可以保障内核安全 |
| 内核函数 | 可以调用内核函数 | 只能通过 BPF Helper 函数调用 |
| 编译性 | 需要编译内核 | 不需要编译内核,引入头文件即可 |
| 运行 | 基于相同内核运行 | 基于稳定 ABI 的 BPF 程序可以编译一次,各处运行 |
| 与应用程序交互 | 打印日志或文件 | 通过 perf_event 或 map 结构 |
| 数据结构丰富性 | 一般 | 丰富 |
| 入门门槛 | 高 | 低 |
| 升级 | 需要卸载和加载,可能导致处理流程中断 | 原子替换升级,不会造成处理流程中断 |
| 内核内置 | 视情况而定 | 内核内置支持 |
表格 2-1 eBPF 与 Linux 内核模块方式对比
容器监控
传统模型
在传统理念中,想要能够“全方位”对容器进行有效监控,开发人员、运维人员或 DevOps 工程师面临着如下共同的挑战:
在传统理念中,想要能够“全方位”对容器进行有效监控,开发人员、运维人员或 DevOps 工程师面临着如下共同的挑战:
1、基于不同的业务场景,针对某一个应用程序,其可能包含数十个甚至数百个单独的容器部署。同时,每个容器都必须进行单独监控,从而增加了部署监控代理以及从每个容器中收集必要数据所需的工作成本。
2、基于容器生命周期状态而言,当某一容器因各种不同的原因导致关闭时,存储在容器内的数据就会消失,而且通常无法准确预测容器何时可能关闭。因此,我们便不能定期拉取监控数据。这与我们所设想的初衷不匹配,期望能够实时收集从每个容器中进行数据获取。
3、除此之外,由于容器是从托管它们的服务器的操作系统中抽象出来,并且,基于不同的环境,它们可能需要在不同的 Node 周围进行飘移,所以,基于主机的监控方法效果往往达不到预期的需求。使得无法能够轻松地在每台服务器上运行代理并使用其来监视所有容器。
其实,从本质上而言,目前市场上有多种方案可供选择以解决上述各种挑战,但最流行、通用的策略便是使用所谓的 Sidecar 模式来部署容器监控代理。在 Sidecar 模式下,监控代理能够在特殊容器内运行,这些容器与它们监控的容器一起运行。这种方法比尝试在主机上部署监控代理更有效。它还消除了直接从应用程序逻辑中公开监控数据的需要,这需要对源代码进行复杂的更改。
在 Sidecar 模型中,可观察性或安全工具作为 Sidecar 容器注入到每个 Pod 中。需要注意的是,Sidecar 也是一个容器,Pod 中的所有容器都可以共享网络命名空间和卷信息等内容,所以 Sidecar 可以看到 Pod 中其他容器中发生的事情。为了在 Pod 里部署 Sidecar,需要在 YAML 中进行配置。这项操作可以是手动进行,也可能是自动进行。当然,可以将 Sidecar 定义注入应用程序 YAML,从而实现自动化部署。
然而,基于 Sidecar 模式有一个天生的缺点:资源的敏感性,即它不能充分有效地使用资源。必须在承载实际工作负载的每个容器旁边部署一个边车容器,这意味着在实际的生产环境中我们最终会运行更多的容器。由于所有这些额外的容器都需要 CPU 和内存资源,因此它们会为我们所构建的容器集群预留更少的资源。
除此之外,Sidecar 模式另一个缺陷便是“配置的合规性”,如果 Sidecar 没有得到正确的配置,便无法在 Pod 中正常运行。这是 Sidecar 另一个脆弱点,如果恶意用户设法运行了一个 Pod,并避免了 Sidecar 的注入,那就无法看到该 Pod 中发生了什么。
基于eBPF模型
eBPF提供了一种方法来解决这个问题,即在不消耗大量资源的情况下监控每个容器。eBPF给Linux内核带来了可编程性,由于其安全、灵活、对应用无侵入的特点,在云原生网络、安全、可观测性方面带来了很多创造性的应用。
eBPF与2015年推出,是Linux的一项功能,可以直接在Linux内核中运行程序,而不是在无法直接访问内核源的“用户空间”中运行程序。
eBPF源于BPF,本质上是出于内核中的一个搞笑与灵活的类虚拟机组件,以一种安全的方式在许多内核Hook点执行字节码。BPF最初的目的是用于搞笑网络报文过滤,经过重新设计,eBPF不再局限于网络协议栈,已经称为内核顶级的子系统,演进为一个通用执行引擎。开发者可基于eBPF开发性能分析工具、软件定义网络、安全等诸多场景。
架构原理
总体而言,eBPF分为User Space(用户空间)程序和Kernel Space(内核)程序俩部分:
- User Space程序负责加载BPF字节码至内核,如需要,也会负责读取Kernel Space回传系统信息或事件详情;
- Kernel Space中的BPF字节码负责在Kernel Space中执行特定事件,如需要,也会将执行的结果通过maps或perf-event事件发送至User Space
其中 User Space 程序与 Kernel Space BPF 字节码程序可以使用 map 结构实现双向通信,这为 Kernel Space 中运行的 BPF 字节码程序提供了更加灵活的控制。
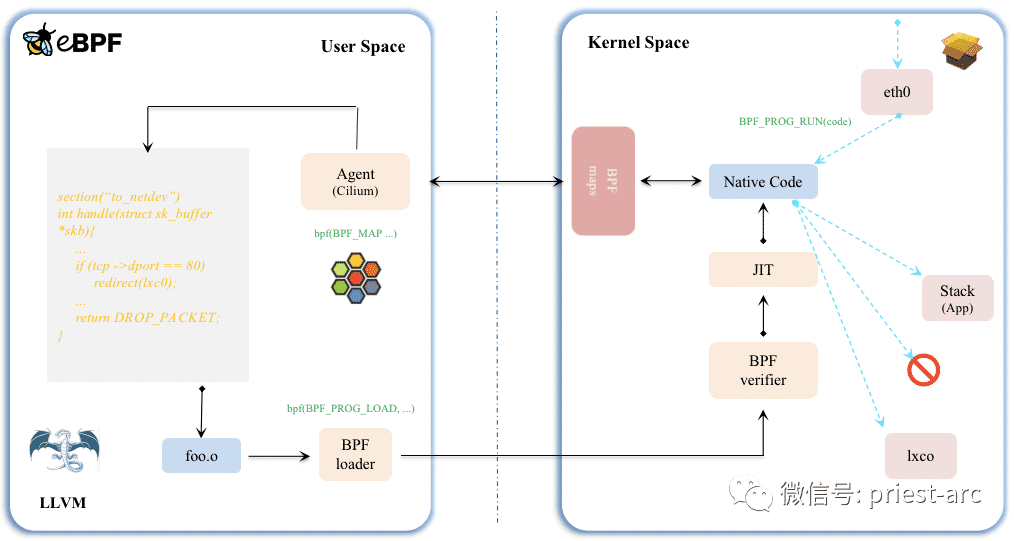
基于上述的架构图,我们可以看到整个工作原理涉及如下:
- eBPF基于事件驱动架构,并附加到代码路径。代码路径包含特定的触发器(称为钩子),这些触发器在传递时执行任何附加的eBPF程序。钩子的一些示例包括Network Events(网络事件)、System Calls(系统调用)、Functions Entries(函数入口)和Kernel Tracepoints(内核跟踪点)等。
- 触发时,代码首先编译为BPF字节码。反过来,字节码在运行前会经过验证,以确保它不会创建循环。此步骤可防止意外或故意损坏Linux内核。
- 在Hook触发程序后,它会进行由内核预先定义好的Helper调用。通常,这些调用主要为eBPF配备多种访问内核功能的函数。
eBPF 最初被用作在过滤网络数据包时提高可观察性和安全性的一种方式。然而,随着时间的推移,它成为使用户提供的代码实现更安全、更方便、性能更好的一种方式。由于在内核中运行,eBPF 程序消耗的资源往往较少,不仅如此,其还可以访问在他们运行的服务器上运行的任何进程所产生的数据
核心优势
从本质上来讲,eBPF 的闪亮点主意体现在“观测”和“安全” 2 个层面,其主要应用于 “追踪” User Space 进程。基于如上,其优势主要涉及如下:
1、高性能
eBPF 可以将数据包处理从 Kernel Space 移动到 User Space。同样,eBPF 是一个准时(JIT)编译器。编译字节码后,将调用 eBPF,而不是对每种方法的字节码进行新的解释,基于此种机制,极大地提高了效率。
2、可编程性
使用 eBPF 有助于在不添加额外层的情况下提高环境的功能丰富度。同样,由于代码直接在内核中运行,因此可以在 eBPF 事件之间存储数据,而不是像其他跟踪器那样转储数据。
3、安全性
程序被有效地沙箱化了,这意味着内核源代码仍然受到保护并保持不变。eBPF 程序的验证步骤确保资源不会被运行无限循环的程序阻塞。
4、侵入性低
与构建和维护内核模块相比,创建 Hook 内核函数的代码的工作更少。当用作调试器时,eBPF 不需要停止程序来观察其状态。
以上为最为核心的优势,当然,除了上述之外,也有其他的优势:例如,单一、强大且可访问的跟踪流程框架;强劲的表现力等等。
应用场景
eBPF 的真正强大之一是低侵入性,也意味着无需改动就可以让程序在内核中运行,使得其能够观测到所有的容器和 Pod 中发生的事情,不需要在任何地方修改任何YAML,也不需要在应用程序中添加脚本。这就是为什么有许多新项目基于 eBPF 以及这种技术令人兴奋的原因之一。
eBPF 正在或已经在云原生生态体系中获得较为广泛的关注及青睐。基于此,若使用 eBPF 技术,其应用场景主要涉及如下:
1、基于内核层面的观测性
在此种场景下,eBPF 能够更快、更准确地进行切入,也不涉及上下文切换带来的性能影响;除此之外,eBPF 程序是基于事件型的,因此,没有特定的触发器,任何额外的事件都不会运行。
2、传统监控力不从心
在分布式和基于容器的环境中,eBPF 能够将“监控”之力发挥的淋漓尽致,尤其是在一些进程可视化场景中。eBPF 可以访问有关进程和在这些进程中运行的程序的信息,也有关于网络流量的信息。如果我们将这些信息结合在一起,进行整合,那么就会得到这样的信息:可以确切的看到哪个进程、在哪个 Node 上、在哪个 Pod 中、在哪个命名空间、正在运行什么可执行文件、在处理哪个特定的网络连接等。毕竟,在这些环境中,eBPF 可以缩小可见性差距,提供 HTTP 流量的可见性。
因此,基于上述所述,如果你想监控容器,那么,则可以编写一个 eBPF 程序,拦截与每个容器相关的进程,并进行监控数据收集。最终会得到一个比传统的 Sidecar 容器占用更少资源的监控解决方案。
同时,不必在为监控目的收集的数据量上做出妥协。实际上,大家所想要的关于每个容器的状态和性能的每条信息都可以通过内核获得。
使用基于 eBPF 的监控方法,甚至部署和管理也变得更简单。我们不必部署和编排一堆 Sidecar 容器,只需在 K8s Cluster 中的每个 Node 上运行一个 eBPF 程序即可。可能大家会问,如果 eBPF 是容器监控的绝佳解决方案,为什么不是每个人都在使用它?
“你怎么知道别人没有在用?” 这里面涉及的因素较多,可能因为技术的成熟度、也许因为人的懒惰性,但这也不能阻止新技术的革新、新技术的侵入。可能大多数现有的容器监控工具都被设计为基于 Sidecar 模式,而不是利用 eBPF。但这种现象已经在逐渐改变。Cilium 等工具已经在使用 eBPF 来提高效率和可见性。许多可观察性供应商——例如 VMware、Splunk 和 New Relic 等等——也在探讨 eBPF 的潜力,将其进行封装集成。
因此,如果你觉得传统的容器监控方法不如法眼、太他妈的 Low,尤其是在降本增效方面,此种策略耗尽我们的应用程序或资源并且难以管理,那么不妨考虑尝试一下 eBPF,或许,它会给你带来不一样的惊喜~