ES段合并原理
简介
在ES中,数据存储在分片中,每一个分片存储一部分数据。为了确保数据的可用性和可靠性,ES通过数据复制机制将每个分片复制到多个节点上,行程多个副本。当索引数据更新时,ES会采用合并原理将更新的数据合并到分片中,保证数据的一致性和完整性。
合并的主要作用有:
- 数据合并:当索引数据更新时,ES会将更新后的数据合并到已有数据中。这样可以确保索引数据的正确性和完整性。
- 碎片整理:当索引数据删除或更新时,会产生碎片(fragment),即被删除或更新的数据占据的空间。合并原理可以对碎片进行整理,减少磁盘空间占用,提高查询性能。
- ES提供了段合并和分片合并和节点合并,以满足不同应用场景和需求
段合并
段合并是ES中最基本,最常见的合并操作。当一个分片中的数据达到一定带下限制或者更新次数时,ES会将分片中的多个段(segment)合并成一个新的段。段合并的主要目的是减少磁盘空间占用提高读取性能。
- 合并候选阶段,es会选择一些相似大小的段作为合并候选,减少合并过程中的IO开销。
- 合并阶段:ES将合并时候选中的多个段合并成为一个新的段。同时删除旧的段。在合并过程中ES会进行数据的排序和去重,并重新生成倒排索引
段合并的触发条件可以通过参数进行配置,如最大段数,最大段大小等。通过合理配置这些参数,可以控制段合并的频率和规模,以达到合并的最佳效果。
分片合并
- 合并候选阶段:ES会选择一些需要合并的分片作为合并选项,减少合并过程中的网络开销。
- 合并阶段:ES将合并候选的多个分片合并为一个新的分片,并将心的分片复制到其他节点上
- 重新分配阶段:ES会将心的分片复制到其他节点上,并进行负载均衡,以确保数据的高可用性和高可靠性。
分片合并的过程中ES会根据节点的负载情况和网络状况进行动态调整,以提高合并的效率和性能。同时ES还提供了手动触发分片合并的API,会触发节点合并操作
节点合并
节点合并是在整个急群众进行合并的操作,主要用于整理碎片和平衡负载。当一个节点上的分片发生变化,如薪资,删除或者迁移时,会触发节点合并操作。
节点合并的过程分为三个阶段:
- 合并候选阶段:ES会选择一些需要合并的节点作为合并候选,减少合并过程中的网络开销。
- 合并阶段:ES将合并选中的多个节点合并为一个新的节点,并且进行负载均衡,以确保数据的高可用性和可靠性。
节点合并过程中,ES会根据节点的负载和情况进行动态调整,以提高合并的效率和性能。同时ES还提供了手动触发节点合并的API,以满足特定需求
分片原理
ES客户端将一份数据写入primary shard,然后将数据同步到replica shard中去。ES客户端取数据的时候就会在replica或primary的shard中去读。ES集群有多个节点,会自动选举一个节点为master节点,这个master节点干一些管理类的操作,比如维护元数据,负责切换primary shard和replica shard的身份,要是master节点宕机了,那么就会重新选举下一个节点为master为节点。如果primary shard所在的节点宕机了,那么就会由master节点将那个宕机的节点上的primary shard的身份转移到replica shard上,如果修复了宕机的那台机器,重启之后,master节点就会将缺失的replica shard分配过去,同步后续的修改工作,让集群恢复正常。
分片机制
在建立索引时,会自动将数据拆分到多个分片(shard)中,默认数量是5,这个就是索引数据分片机制。
document路由原理
document要存储到Elasticsearch中,还要满足后续搜索的需求,路由到分片位置的算法肯定不能是随机的,要不然搜索就没法找了,路由的过程有一个公式:
shard = hash(routing) % number_of_primary_shards
routing值默认是document的ID值,也可以自行指定。先对routing信息求hash值,然后将hash结果对primary_shard的数量求模,比如说primary_shard是5,那么结果肯定落在[0,4]区间内,这个结果值就是该document的分片位置,如示意图所示:
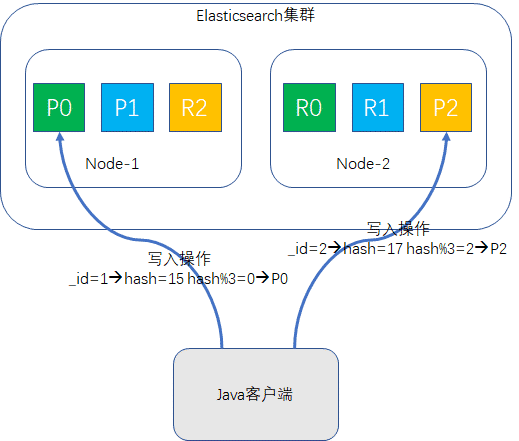
这个求模公式间接的解释了为什么了索引创建时指定了primary shard的值,后续就不让改了,模数改了,之前路由的document再执行该公式时,值就可能跟改之前得到的值不一致,这样document就找不到了