insert...on duplicate key update
作用和使用场景
在mysql入库时,不能出现两条数据主键一致的情况,因为在两条数据的主键一致的情况下,mysql就会判定为待插入数据在数据库中存在重复数据,也就是说判断数据是否重复是根据主键来区别的。
但是有一些场景,如日志文件解析入库,消息队列接收数据入库等情况下可能解析到或者接收到待插入的重复数据存在重复数据则更新,不存在则插入。
这时如下语句的写法就派上用场了,on duplicate key update的作用也就是说存在重复数据则更新,不存在则插入。
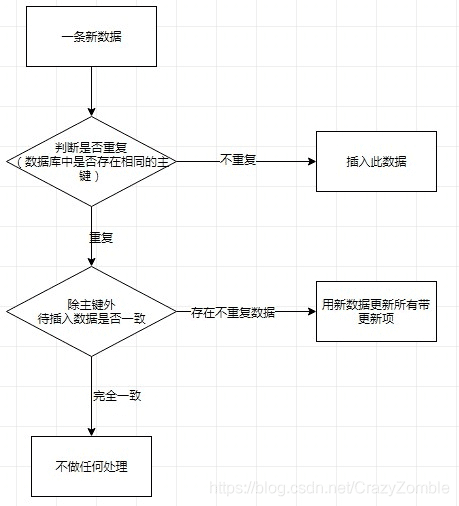
场景大概是这样的,业务方的需求是查询一条语句在不在,如果在就给出一个update语句,更新这条记录,如果不在,就给出一个insert语句,插入这条记录。逻辑大概是:
result = select * from table;
if result = 0
insert the record into table;
else
update the record;
这样的操作乍一看没有什么问题,但是仔细分析分析,还是有些瓶颈的,目前来看,我能分析到的瓶颈有两个,
其一:
每次要执行2个SQL,效率比较差;
其二:
当我们在高并发的情况下跑这条语句,如果程序崩溃,不能保证操作的原子性。
insert...on duplicate key update语法的作用,可以分析到,当发生主键冲突的时候,可以直接进行update操作,这个update操作里面可以更新任意想要更新的列;而没有主键冲突的时候,相当于对这个表进行了一次插入操作。
Replace操作
Replace语句。使用Replace插入一条记录时,如果不重复,Replace就和Insert的功能一样,如果有重复记录,Replace就使用新记录的值来替换原来的记录值。
使用REPLACE的最大好处就是可以将Delete和Insert合二为一,形成一个原子操作。这样就可以不必考虑在同时使用Delete和Insert时添加事务等复杂操作了。
在使用Replace时,表中必须有唯一索引,而且这个索引所在的字段不能允许空值,否则Replace就和Insert完全一样的。
在执行Replace后,系统返回了所影响的行数,如果返回1,说明在表中并没有重复的记录,如果返回2,说明有一条重复记录,系统自动先调用了Delete删除这条记录,然后再记录用Insert来插入这条记录。
不同之处
有了上面的知识储备,这两条命令的不同之处就显而易见了,replace是删除记录,然后再重新insert,而insert...on duplicate key update是直接在该条记录上修改,所以二者的差别主要有以下两处:
1、当表中存在自增值的时候,如果表中存在某条记录,replace语法会导致自增值+1,而insert...on duplicate key update语法不会;
2、当表中的某些字段中包含默认值的时候,replace操作插入不完全字段的记录,会导致其他字段直接使用默认值,而insert...on duplicate key update操作会保留该条记录的原有值。