ClickHouse基础
简介
版本
- 20.5 final支持多线程
- 20.6.3 支持explain
- 20.8 支持同步mysql
安装
通过rpm安装后
bin/ ===> /usr/bin/
conf/ ===> /etc/clickhouse-server/
lib/ ===> /var/lib/clickhouse
log/ ===> /var/log/clickhouse默认会创建一个clockhouse用户让你设置密码
打开/etc/clickhouse-server下会有几个文件
config.d ==>默认配置
config.xml =>服务配置
user.d ==>默认配置
users.xml =>参数(cpu,内存使用量)配置默认只有本机可以访问,需要打开config中的注释
<listen_host></listen_host>保存启动
sudu clickhouse status或者sudu clickhouse restart
连接
clickhouse-client -m以;为结束语句默认是9000端口
show database;
返回默认俩个库default和system,use进入数据库
表引擎
表引擎是clickHouse的一大特色.可以行锁决定了如何存储表的数据,包括
- 数据的存储方式和位置,写到哪里以及从哪里读取数据:可以支持mysql,kafka
- 支持哪些查询以及如何支持
- 并发数据访问
- 索引的使用
- 是否可以多线程请求
- 数据复制参数
引擎名称大小写敏感
TinyLog
以列文件的形式保存在磁盘上,不支持索引,没有并发控制.一般保存少量数据的小表
三叉戟上作用悠闲.可以平时练习使用
create table t_tinylog (id String,name String) engine=TinyLog
小于100w行
Memory
内存引擎,数据以未压缩的原始形式直接保存在内存中,服务器重启数据就会消失
读写操作之间不阻塞,不支持索引,简单查询下有非常高的性能表现(10g/s)
用到的地方不多,除了来测试,就是 再需要非常高的性能数据量不大,上线1行的场景
mergetree
(没有任何前后缀),ClickHouse中最强大的表引擎当属Merge Tree (合并树)引擎以及该系列(*mergeTree)中的其他引擎,支持索引和分区,地位可以相当于innodb之于mysql.有很多子引擎
建表语句
create table t_order_mt(
id Uint32,
sku_id String,
total_amount decimal(16,2),
create_time datetime
)engine = MergeTree
partition by toYYYMMDD(create_time) #分区字段
primary key (id) #主键,默认没有唯一约束
order by (id,sku_id) #排序字段主键和分区字段都不是必须的,但是order by字段是必须的
partition by分区
学过hive的应该都不陌生,分区的目的主要是降低扫描的范围,优化查询速度,如果不设置就会使用一个分区
分区目录:MergeTree是以文件列表+索引列表+定义文件组成的,但是如果设定了分区那这些文件就会保存到不同的分区目录中
并行:面对设计跨分区的查询统计,clickHouse会以分区为单位进行处理
数据写入与分区合并
任何一个批次的数据写入都会产生一个临时分区,不会纳入任何一个已有的分区.写入后的某个时刻(大概10-15分钟左右),clickHouse自动执行合并操作(等不及可以手动通过optmize执行)把临时分区的数据,合并到已有分区中,然后在一段时间后删除被合并之前的分区
primary key 主键(可选)
clickHouse中的主键和其他数据库不太一样,它只提供了数据的一级索引,但是却不是唯一约束.这就意味着是可以存在相同的primary key的数据的
逐渐的设定主要依据是查询依据中的where条件
根据条件通过对逐渐进行某种二分查找,能够定位到对应的index granularity
避免了全表扫描
index granularity
:直接翻译的话就是索引粒度,指在稀疏索引中俩个相邻索引对应数据的间隔.clickHouse中的MergeTree是8192.官方不建议修改这个值,除非存在大量重复值,比如一个分区中几万行才有一个不同的数据
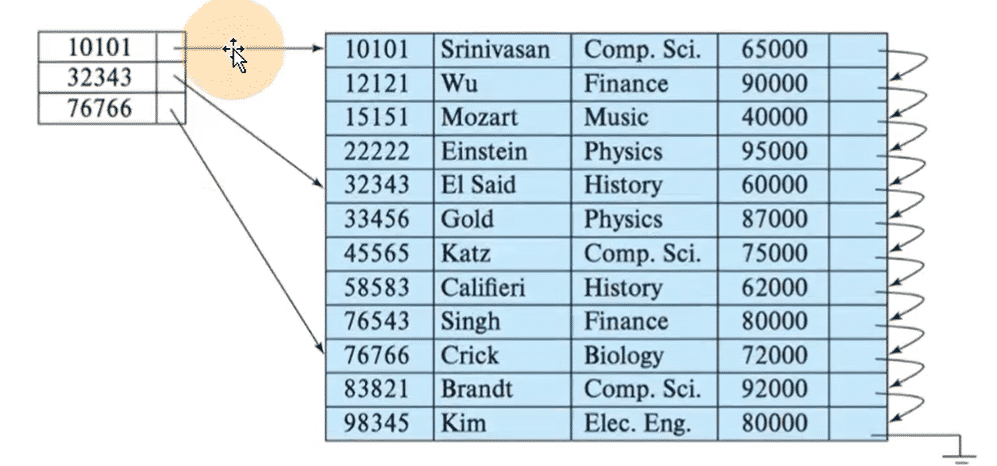
order by
order by设定了分区内的数据按照那些字段顺序进行有序保存
order by是merge Tree中唯一一个非必填项,甚至比primary key还重要,因为当用于不设置主键的情况,很多处理会依旧按照order by字段处理(比如后面会讲的去重和汇总)
主键必须是order by的字段的前缀字段
比如order by字段是(id,sku_id)那么逐渐必须是(id,sku_id)
二级索引
再20.1.2.4之前是实验性功能,再之后的版本才是默认开启的
字段定义的时候加一段,给total_amount 加索引
INDEX a total_amount TYPE minmax GRANULARITY 5
可以简单理解为给索引再加一次索引,再记录大量重复的时候可以用
GRANULARITY N是设定二级索引对于1级索引的粒度
数据TTL
TTL即time To Live,数据的存活时间。
MergeTree中,可以为某个列字段,或者整张表设置TTL。当时间到达时,如果是列字段级别为TTL,则会删除这一列数据;如果是表级别为TTL,则会删除整张表的数据;如果同时设置了列级别和表级别的TTL,会以先到时间的为准删除数据。
无论是列或者表级别的TTL,都依靠DateTime或Date类型字段,通过对这个时间字段的INTERVAL操作,来确定TTL过期时间:
注意:无论是列级别TTL,还是表级别TTL,一旦设置后,目前没有取消的方法。
ReplacingMergeTree
ReplacingMergeTree是MergeTree的一个变种,它存储特性完全继承MErgeTree,只是多了一个去重功能尽管MergeTree可以设置主键,但是主键没有唯一约束功能,如果想处理掉重复的数据可以借用ReplacingMergeTree
去掉时机:不是实时去重
数据的去重只会在合并的过程中出现.合并会在位置的事件在后台进行,所以你无法预先做出计划,.有一些数据可能仍未被处理
去重范围
如果表经过了分区,去重只会在分区内部进行去重,不能执行跨分区去重
所以ReplacingMergeTree的能录有限,适用于在后台清楚重复数据,不能保证没有重复数据出现
创建表 engine=ReplacingMergeTree()
ReplacingMergeTree()填入的参数为版本字段,重复数据保留本字段值最大的,如果不填版本字段,默认按照插入数据保留最后一条
最终一次性
SummingMergeTree
对于不查询明细,只关心以维度进行汇总聚合结果的场景.(GROUP BY 条件明确,且不会随意改变)。如果只使用普通的MergeTree的话,无论是存储空间的开销,还是查询时聚合的开销都比较大
ClickHouse为了这种场景,提供了一种能够"预聚合"的引擎SummingMergeTree
- 分区内聚合
- 分片合并才会聚合
engine=SummingMergeTree()填需要聚合的字段
- 以SummingMergeTree()中指定的列作为汇总数据列
- 可以填写多列必须数字列,如果不填,以所有非维度切数字的字段为汇总数据列
- 以order by的列为例,作为维度列
- 其他的列按插入顺序保留第一行
- 不再一个分区的数据不会被聚合
- 只有在同一批次插入(新版本)或分别时才会进行聚合
开发建议:唯一键值,流水号可以去掉,所有字段全部是维度,度量或时间戳
SummingMergeTree无法保证幂等性
sql操作
click提供了delete和update的能力,这类操作被称为Mutation查询,它可以看做alter的一种
虽然可以实现修改和删除,但是和一般的OLTP数据库不一样,Mutation一句是一种很重的操作,而且不支持事务
重的原因主要是每次修改或者删除都会导致放弃目标数据的原有分区,重建分区,所以尽量做批量的变更,不要进行频繁的小数据操作
通过alter table来实现
由于操作比较重,所以Mutation语句分俩步执行,同步执行的部分其实只是进行新增数据和新增分区,并把旧分区打上逻辑上的失效标记.直到出发分区合并的时候,才会删除旧数据释放磁盘空间,一般不会开放这样的功能给用户,由管理员完成
实现高性能update和delete的思路加版本号
update和delete加上一个版本字段,每次只读最大的版本
问题:时间久了数据会变大
click基本上与标准sql差别不大
- 支持子查询
- 支持CTE
- 支持join,但join操作无法使用缓存,所以即使是俩次相同的语句,clickHouse也会看做俩条新sql(clickHouse会先把数据加载到内存中,再去join下一张表)
- 窗口函数(官方正在测试)
- group by增加了with rollupwith cubewith total用来计算小计和总计
alter操作
同mysql的修改字段基本一致
副本
副本的目的重要是保障数据的高可用性,即一台ClickHouse节点宕机,那么也可以从其他服务器获得相同的数据
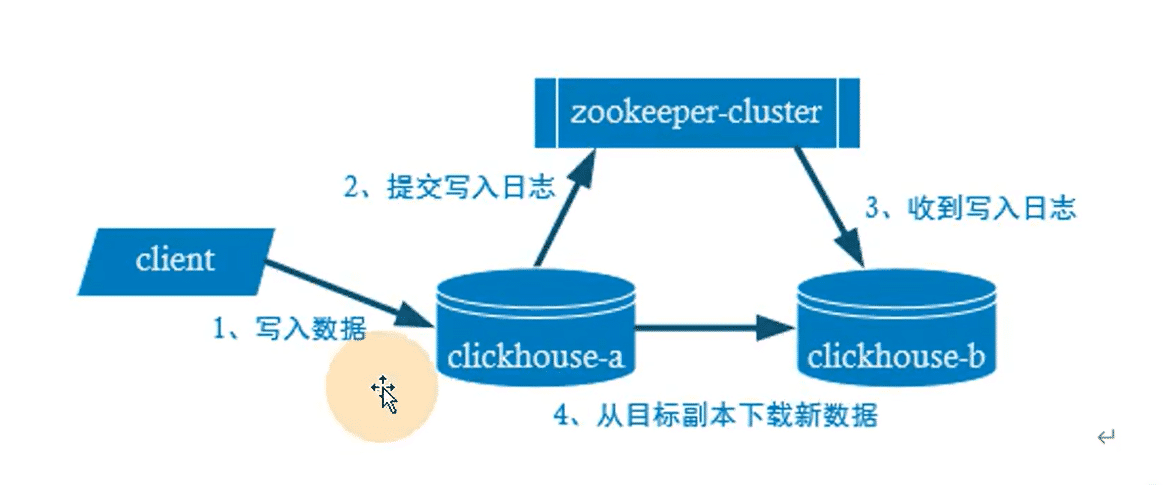
没有主从之分需要通过Zookeeper实现
分片集群
副本虽然能够提高数据可用性,降低丢失风险,但是每台服务器上必须容纳全量数据,对数据的横向扩容没有解决
要解决数据水平切分的问题,需要引入分片概念.通过分片把一份完整的数据进行切分不同的分片分部到不同的节点上,再通过Distributed表引擎把数据拼接起来一起使用
Distributed表引擎本身并不存储数据,有点类似与mycat之于mysql, 成为一种中间件,通过分布式逻辑来写入,分发,路由操作多态节点不同的分布式数据
clickHouse的集群是表级别的,实际企业中,大部分做了高可用,额但是没有用分片,避免降低查询性能以及操作集群的复杂性
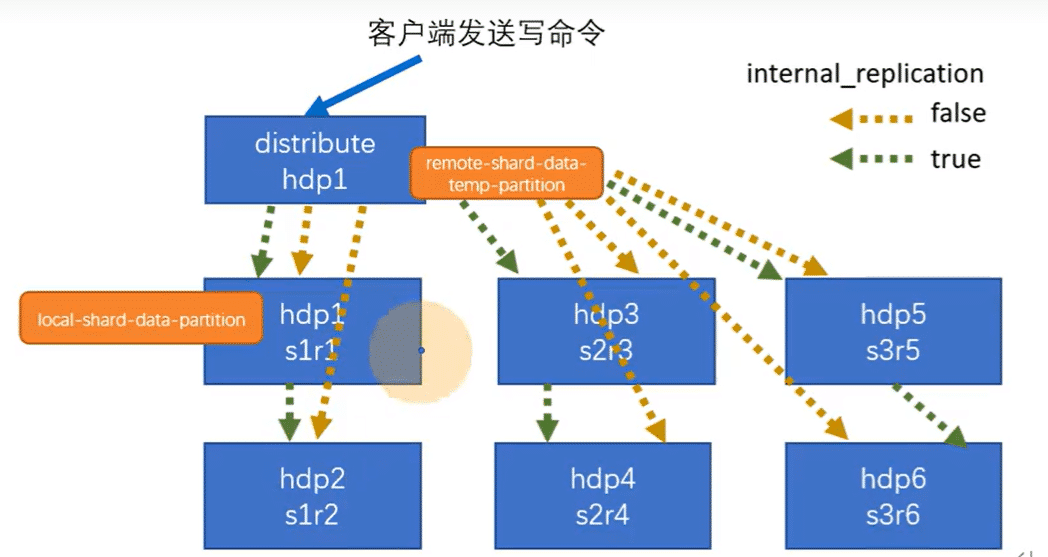
副本之间同步是内部同步
绿色的箭头是内部同步打开的情况下,黄色的箭头是内部同步关闭的情况
读取过程
优先选择errors_count小的副本(发生错误的次数)
errors_count相同的有随机,顺序,随机(优先第一顺位),host名称近似等四种选择方式
