Dubbo
架构
作用
dubbo提供了六大核心能力
- 面向接口代理的高性能RPC调用
- 只能容错和负载均衡
- 服务自动注册和法线
- 高可用扩展能力
- 运行期流量调度
- 可视化的服务治理与运维
角色
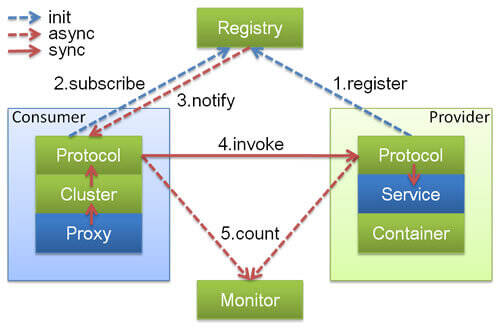
- Contaniner:服务运行容器,负责加载,运行服务提供者.必须.
- provider:暴露服务的服务提供方,会想注册中心注册自己提供的服务.必须
- 调用远程服务的服务消费方,会想注册中心订阅自己所需的服务.必须
- Registry:服务注册与发现的注册中心.注册中心会返回服务提供者地址列表给消费者.非必须
- Monitor:统计服务的调用次数和调用时间的监控中心.服务消费者和提供者会定时发送统计数据到监控中心.非必须
Invoker
Invoker是Dubbo领域模型中非常重要的一个概念,如果阅读过dubbo源码的话,会无数次看到这玩意
简单来说Invoker就是Dubbo对远程调用的抽象

按照官方的话来说Invoker分为
- 服务提供Invoker
- 服务消费
假如我们需要调用一个远程方法,我们需要动态代理来屏蔽远程调用的细节吧,我们屏蔽掉的细节就是对应Invoker实现,Invoker实现了真正的服务调用
工作原理
下面是dubbo的整体设计,从上至下分为十层,各层均为单向依赖
左边淡蓝背景的为服务消费方使用的接口,右边淡绿色背景的为服务提供方使用的接口,位于中轴线上的为双方都用到的接口。

- config配置层:dubbo相关的配置.支持代码配置,同时也支持基于spring来做配置,以ServiceConfig,ReferenceConfig为中心
- proxy服务代理层:调用远程方法像调用本地方法一样简单的关键,真实调用过过程依赖代理类,以serviceProxy为中心
- Registry注册中心封装服务地址的注册与发现
- cluster路由层:RPC调用次数和调用时间监控,以statistics为中心
- protocol远程调用层:封装RPC调用,以Invocation,result为中心
- exchange信息交换层:封装请求响应模式,同步转异步,以request,response为中心
- transport网络传输层:抽象mina和netty为统一接口,一message为中心
- serialize数据序列化层:对需要在网络传输的数据进行序列化
dubbo的SPI
SPI机制被大量用在开源项目中,它可以帮助我们动态寻找服务/功能(比如负载均衡策略的实现)
SPI具体的原理是这样的:我们将接口的实现类放在配置文件中,我们在程序运行过程中读取配置文件,通过反射加载实现类.这样,我们可以在运行的时候,动态替换接口的实现类.和IOC的解耦思想是类似的
java本身就提供了SPI机制.不过Dubbo没有直接用,而是对java原生的SPI进行了增强,以便更好满足需求
那我们如何扩展 Dubbo 中的默认实现呢?
比如说我们想要实现自己的负载均衡策略,我们创建对应的实现类 XxxLoadBalance 实现 LoadBalance 接口或者 AbstractLoadBalance 类。
package com.xxx;
import org.apache.dubbo.rpc.cluster.LoadBalance;
import org.apache.dubbo.rpc.Invoker;
import org.apache.dubbo.rpc.Invocation;
import org.apache.dubbo.rpc.RpcException;
public class XxxLoadBalance implements LoadBalance {
public <T> Invoker<T> select(List<Invoker<T>> invokers, Invocation invocation) throws RpcException {
// ...
}
}我们可以将这个实现类的路径写入到resouces下的 META-INF/dubbo/org.apache.dubbo.rpc.cluster.LoadBalance文件中即可。
src
|-main
|-java
|-com
|-xxx
|-XxxLoadBalance.java (实现LoadBalance接口)
|-resources
|-META-INF
|-dubbo
|-org.apache.dubbo.rpc.cluster.LoadBalance (纯文本文件,内容为:xxx=com.xxx.XxxLoadBalance)微服务架构
doubbo采用微内核(Microkernel)+插件(plugin)模式,简单来说就是微内核架构.微内核只负责组装插件.
微内核架构模式(有时被称为插件架构模式)是实现基于产品应用程序的一种自然设计模式.基于产品的应用程序是已经打包好并且拥有不同版本,可作为第三方插件下载的.微内核系统可让用户添加额外的应用如插件,到核心应用,继而提供了可扩展性和功能分离的用法。
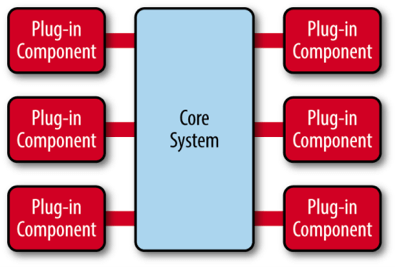
核心系统所需核心能力,插件模块可以扩展系统的功能.因此,基于微内核架构的系统,非常易于扩展功能
我们常见的一些IDE,都可以看作是基于微内核架构设计的。绝大多数 IDE比如IDEA、VSCode都提供了插件来丰富自己的功能。
正是因为Dubbo基于微内核架构,才使得我们可以随心所欲替换Dubbo的功能点。比如你觉得Dubbo 的序列化模块实现的不满足自己要求,没关系啊!你自己实现一个序列化模块就好了啊!
通常情况下,微核心都会采用 Factory、IoC、OSGi 等方式管理插件生命周期。Dubbo 不想依赖 Spring 等 IoC 容器,也不想自己造一个小的 IoC 容器(过度设计),因此采用了一种最简单的 Factory 方式管理插件 :JDK 标准的 SPI 扩展机制 (java.util.ServiceLoader)。
分布式问题
注册中心
注册中心可以实现分布式的服务注册与发现,注册中心是分布式系统的枢纽
主要作用有
动态加入。 一个服务提供者通过注册中心可以动态地把自己暴露给其他消费者, 无须消费者逐个去更新配置文件。
动态发现。 一个消费者可以动态地感知新的配置、 路由规则和新的服务提供者, 无须重启服务使之生效。
动态调整。 注册中心支持参数的动态调整, 新参数自动更新到所有相关服务节点。
统一配置。 避免了本地配置导致每个服务的配置不一致问题。
dubbo可以使用多种注册中心,比如nacos,redis,eureka,zk等
无论使用哪一种注册中心的实现,都要在注册中心上保存四种类型的数据:
- providers:服务提供者的目录,记录着服务提供者的ip,端口等信息
- consumers:服务消费者的目录,记录服务消费者的元数据信息,服务提供者并不会用到服务消费者的信息,这里要记录消费者的信息,是给服务治理中心(dubbo-admin)使用的
- configurators:用于服务动态配置URL元数据的信息
比如在zk中上述信息的数据结构如下

注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互
服务提供者宕机后,注册中心会立即推送事件通知消费者
注册中心和监控中心都宕机的话,服务也不会挂掉,消费者在本地缓存了提供者的列表.注册中心和监控中心都是可选的,消费者可以直连服务提供者
服务发现
服务发现,即消费端自动发现服务地址列表的能力,是微服务框架需要具备的关键能力,借助于自动化的服务发现,微服务之间可以在无需感知对端部署位置与 IP 地址的情况下实现通信。
实现服务发现的方式有很多种,Dubbo 提供的是一种 Client-Based 的服务发现机制,通常还需要部署额外的第三方注册中心组件来协调服务发现过程,如常用的 Nacos、Consul、Zookeeper 等,Dubbo 自身也提供了对多种注册中心组件的对接,用户可以灵活选择。
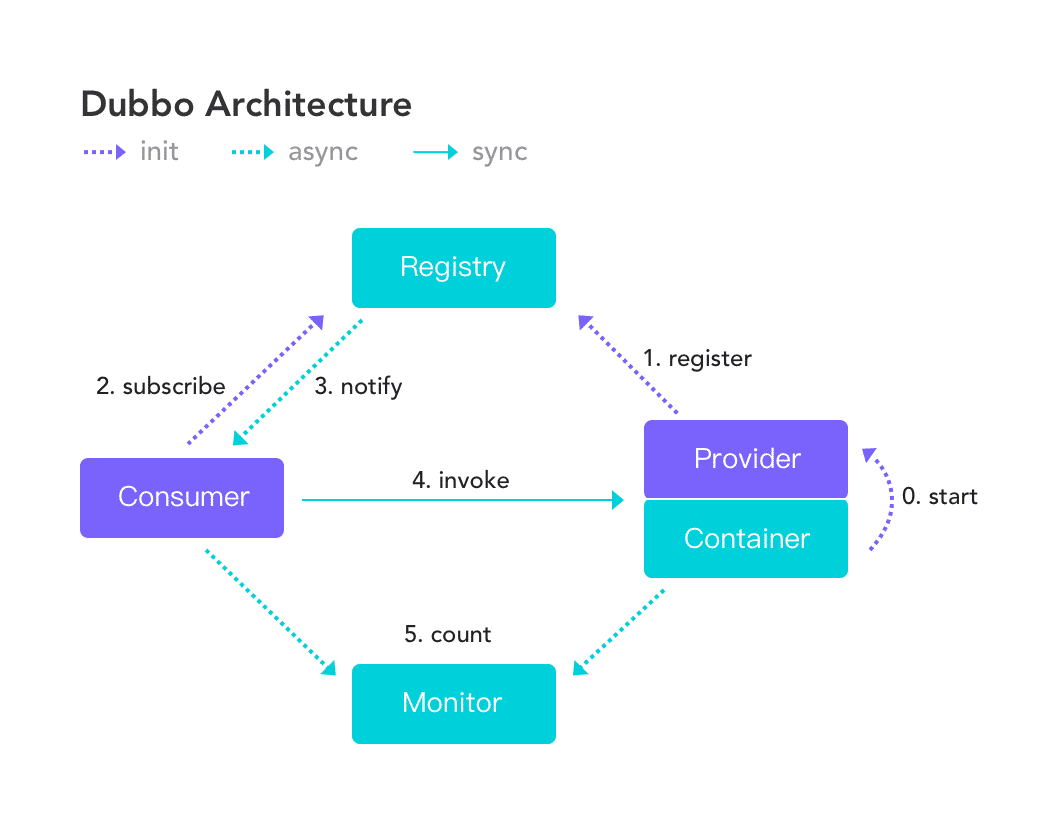
在传统的部署架构下,服务发现涉及提供者、消费者和注册中心三个参与角色,其中,提供者注册 URL 地址到注册中心,注册中心负责对数据进行聚合,消费者从注册中心订阅 URL 地址更新。 在云原生背景下,比如当应用部署在 Kubernetes 等平台,由于平台自身维护了应用/服务与实例间的映射关系,因此注册中心与注册动作在一定程度上被下沉到了基础设施层,因此框架自身的注册动作有时并不是必须的。
Dubbo3 提供了全新的应用级服务发现模型,该模型在设计与实现上区别于 Dubbo2 的接口级服务发现模型
元数据中心
元数据中心是dubbo2.7版本之后的新功能,主要是为了减轻注册中心的压力,将部分存储在注册中心的内容放到元数据中心.元数据中心的数据只是给自己使用的,改动不需要告知对端,比如服务端修改了元数据,不需要通知消费端.这样注册中心存储的数据减少,同时大大降低了因为配置修改导致注册中心频繁通知监听者,从而大大减轻注册中心压力
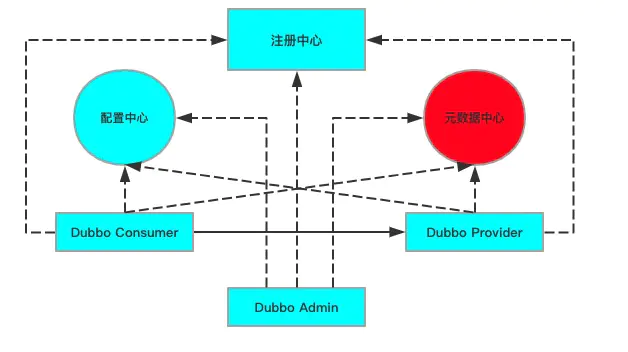
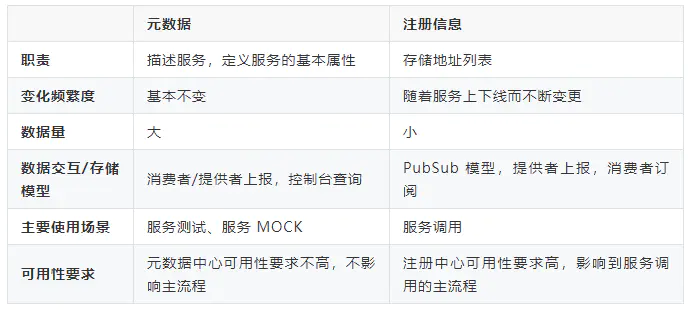
服务治理中的元数据(Metadata)指的是服务分组、服务版本、服务名、方法列表、方法参数列表、超时时间等,这些信息将会存储在元数据中心之中。与元数据平起平坐的一个概念是服务的注册信息,即:服务分组、服务版本、服务名、地址列表等,这些信息将会存储在注册中心中。元数据中心和注册中心存储了一部分共同的服务信息,例如服务名。两者也有差异性,元数据中心还会存储方法列表即参数列表,注册中心存储了服务地址
配置中心
配置中心与其他两大中心不同,它无关于接口级还是应用级,它与接口没有对应关系,它仅仅与配置数据有关,技师没有部署注册中心和元数据中心,配置中心也能直接接入到dubbo应用服务中.在整个部署架构中,整个集群的实例(无论是provider还是consumer)都会共享该配置中心集群中的配置
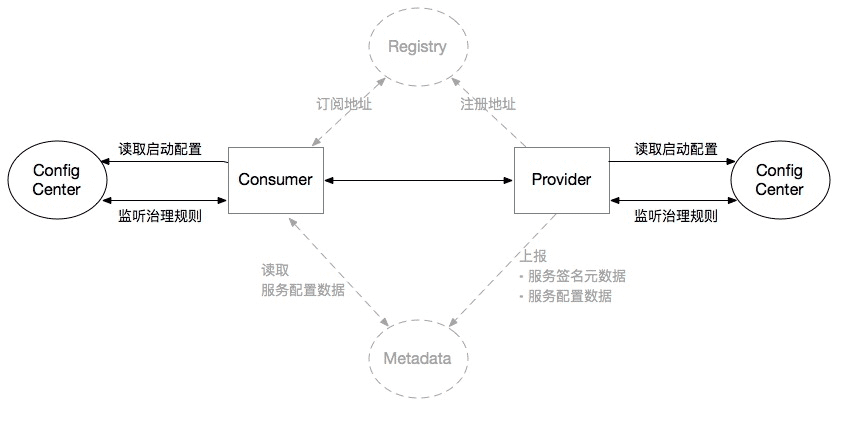
该图中不配备注册中心,意味着可能采用了Dubbo mesh的方案,也可能不需要进行服务注册,仅仅接收直连模式的服务调用。
该图中不配备元数据中心,意味着Consumer可以从Provider暴露的MetadataService获取服务元数据,从而实现RPC调用
高可用
虽然三大中心不再是dubbo应用服务所必须的,但是在真实的生产环境中,一旦已经集成并部署了该三大中心,三大中心还是会面临可用性问题.Dubbo需要支持三大中心的高可用方案.
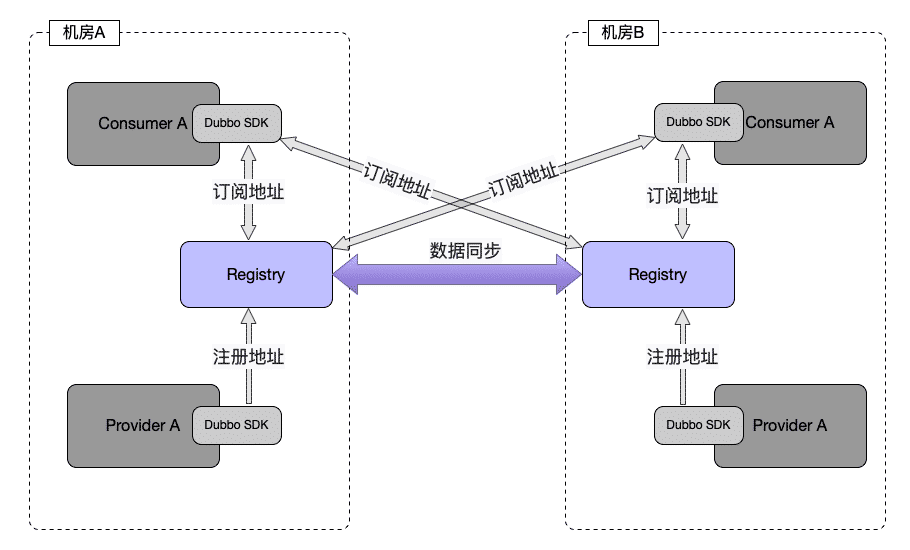
多元数据中心、多配置中心,来满足同城多活、两地三中心、异地多活等部署架构模式的需求。
Dubbo SDK对三大中心都支持了Multiple模式。
- 多注册中心:Dubbo 支持多注册中心,即一个接口或者一个应用可以被注册到多个注册中心中,比如可以注册到ZK集群和Nacos集群中,Consumer也能够从多个注册中心中进行订阅相关服务的地址信息,从而进行服务发现。通过支持多注册中心的方式来保证其中一个注册中心集群出现不可用时能够切换到另一个注册中心集群,保证能够正常提供服务以及发起服务调用。这也能够满足注册中心在部署上适应各类高可用的部署架构模式。
- 多配置中心:Dubbo支持多配置中心,来保证其中一个配置中心集群出现不可用时能够切换到另一个配置中心集群,保证能够正常从配置中心获取全局的配置、路由规则等信息。这也能够满足配置中心在部署上适应各类高可用的部署架构模式。
- 多元数据中心:Dubbo 支持多元数据中心:用于应对容灾等情况导致某个元数据中心集群不可用,此时可以切换到另一个元数据中心集群,保证元数据中心能够正常提供有关服务元数据的管理能力。
拿注册中心举例,下面是一个多活场景的部署架构示意图: