Logstash
简介
简介
logStash与flume非常类似也是做日志数据采集的工作
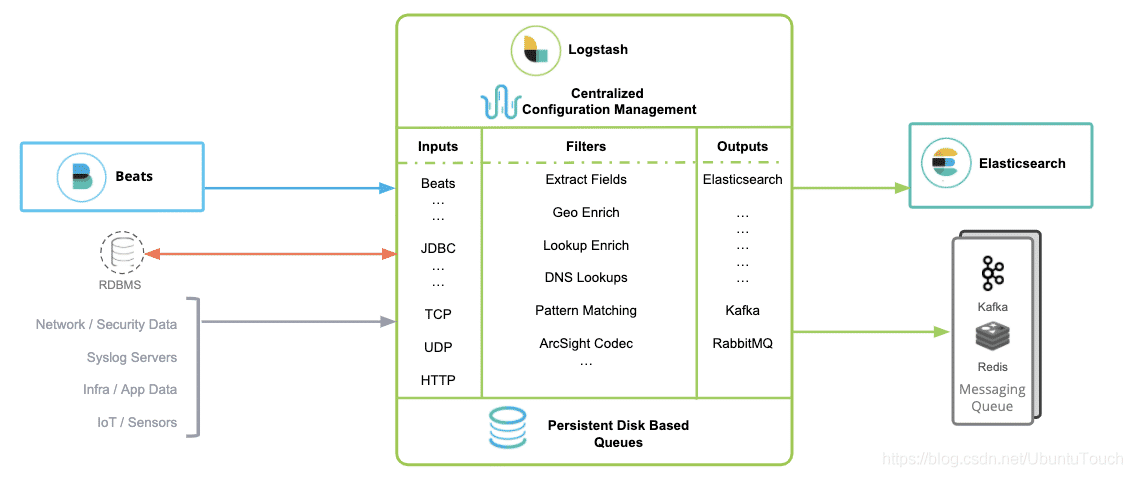
logstash有三个主要的组件
- input-plugins:主要用于定义哪些地方可以采集数据 类似于flume中的sourc组件
- output-plugins:主要定义采集好的数据保存到哪里去。类似于flume当中的sink组件
- filter-plugin:主要对采集的数据做加工和格式转换等一些工作。类似于flime中的拦截器
logstash是一个功能强大的工具,可与各种部署集成。 它提供了大量插件,可帮助你解析,丰富,转换和缓冲来自各种来源的数据。 如果你的数据需要 Beats 中没有的其他处理,则需要将 Logstash 添加到部署中。
最后,它可以把自己的数据输出到各种需要的数据储存地,这其中包括 Elasticsearch。
尽管logstash不仅仅处理log,但是如果我们以log为例来描述在Elastic Stack中的工作流,它可以用如下一张图来进行描述
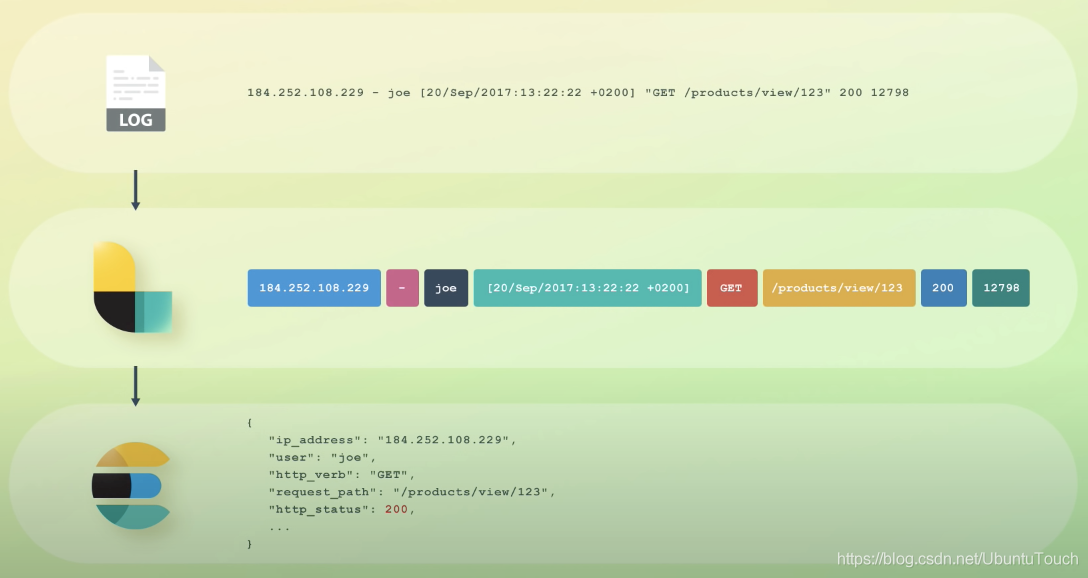
在上面最原始的log数据,经过logstash的处理,可以把非结构化的数据变成结构化的数据。我们甚至可以使用logstash强大的filter来对数据进行加工
比如在上面,我们甚至可以使用GeoIP过滤丰富的IP地址字段,从而得到具体的位置信息。我们可以结合外部数据库对数据转换等等
“ELK” 是三个开源项目的缩写:Elasticsearch,Logstash 和 Kibana。 Elasticsearch 是搜索和分析引擎。Elasticsearch 是整个 Elastic Stack 的核心组件。 Logstash 是一个服务器端数据处理管道,它同时从多个源中提取数据,进行转换,然后将其发送到类似 Elasticsearch 的 “存储” 中。Beats 是一些轻量级的数据摄入器的组合,用于将数据发送到 Elasticsearch 或发向 Logstash 做进一步的处理,并最后导入到 Elasticsearch。 Kibana 允许用户在 Elasticsearch 中使用图表将数据可视化。Kibana 也在不断地完善。它可以对 Elastic Stack 进行监控,管理。同时它也集成了许多应用。这些应用包括 Logs, Metrics,机器学习,Maps 等等。
用处
- 它是用于数据物流的开源流式ETL(Extract-Transform-Load)引擎
- 在几分钟内简历数据流管道
- 具有水平可扩展即任性具有自适应缓冲
- 不可知的数据源
- 具有200多个集成处理器的插件生态系统
- 使用ElasticStack监视和管理部署
logStash几乎开源摄入各种类别的数据
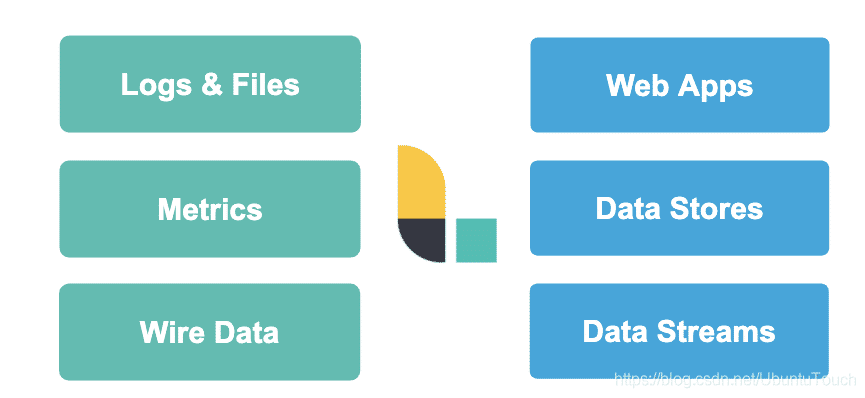
开源摄入日志,文件,指标或者网络的真实数据。经过Logstash的处理,变为开源使用的WebApps开源消耗的数据,也可以存储于数据中心,或者变为其他流式数据。
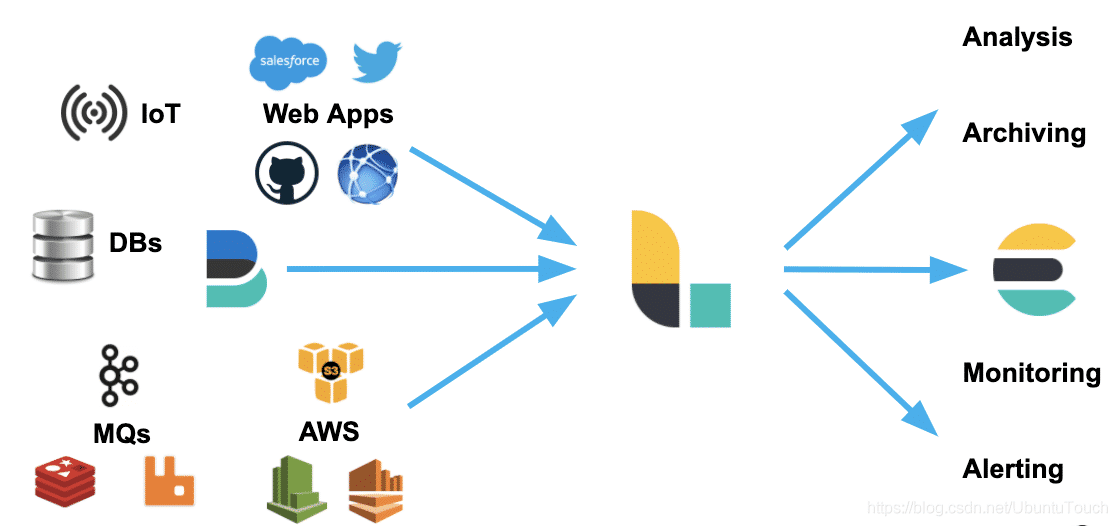
- Logstash 可以很方便地和 Beats一起合作,这也是被推荐的方法
- Logstash 也可以和那些著名的云厂商的服务一起合作处理它们的数据
- 它也可以和最为同样的信息消息队列,比如 redis 或 kafka 一起协作
- Logstash 也可以使用 JDBC 来访问 RDMS 数据
- 它也可以和 IoT 设备一起处理它们的数据
- Logstash 不仅仅可以把数据传送到 Elasticsearch,而且它还可以把数据发送至很多其它的目的地,并作为它们的输入源做进一步的处理
导入数据
目前位置有三种方式把我们感兴趣的数据导入到ElasticSearch中
- eats:我们可以通过 Beats 把数据导入到 Elasticsearch中
- Logstash:我们可以 Logstash 把数据导入。Logstash 的数据来源也可以是 Beats
- REST API:我们可以通过 Elastic 所提供的丰富的 API 来把数据导入到 Elasticsearch 中。
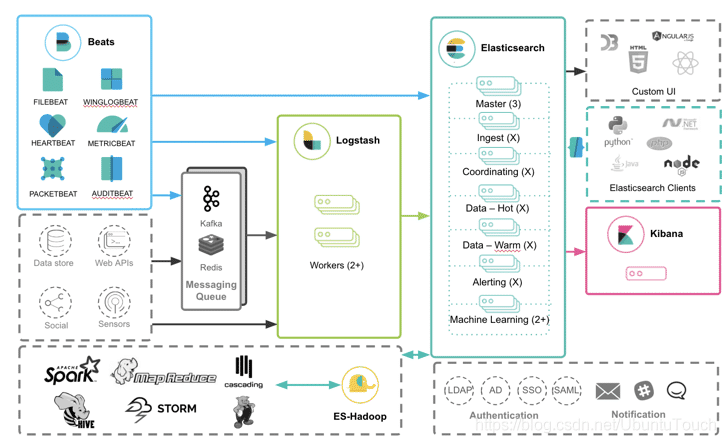
我们可以直接把 Beats 的数据传入到 Elasticsearch 中,甚至在现在的很多情况中,这也是一种比较受欢迎的一种方案。它甚至可以结合 Elasticsearch 所提供的 pipeline 一起完成更为强大的组合。
我们可以利用 Logstash 所提供的强大的 filter 组合对数据流进行处理:解析,丰富,转换,删除,添加等等。你可以参阅我之前的文章 “Data转换,分析,提取,丰富及核心操作”
针对有些情况,如果我们的数据流具有不确定性,比如可能在某个时刻生产大量的数据,从而导致 Logstash 不能及时处理,我们可以通过 Kafka 来做一个缓存。你可以参考我的文章 “使用 Kafka 部署 Elastic Stack”。
工作方式
logstash是如何工作的
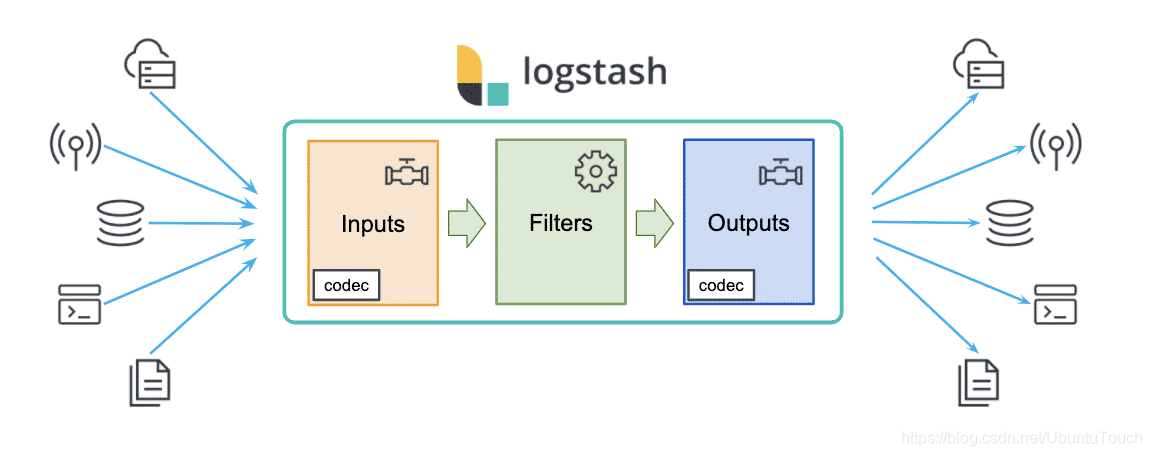
Logstash 旨在作为独立组件运行,以将数据加载到 Elasticsearch(以及其他目标系统)。 Logstash 是一个基于插件的组件,这意味着它可以高度扩展它支持的源/目标系统类型以及它可以进行的转换。Logstash 不是集群组件,无法感知其他 Logstash 实例。 通过跨实例负载平衡数据,可以使用多个 Logstash 实例来满足高可用性和扩展需求。
- logstash实例是一个正在运行logstash进程。建议在Elasticsearch的单独主机上运行Logstash,以确保俩个组件有足够的计算资源可用
- 管道(pipeline)是配置为处理给定工作负载的插件集合。一个logstash实例可以运行多个管道(彼此独立)
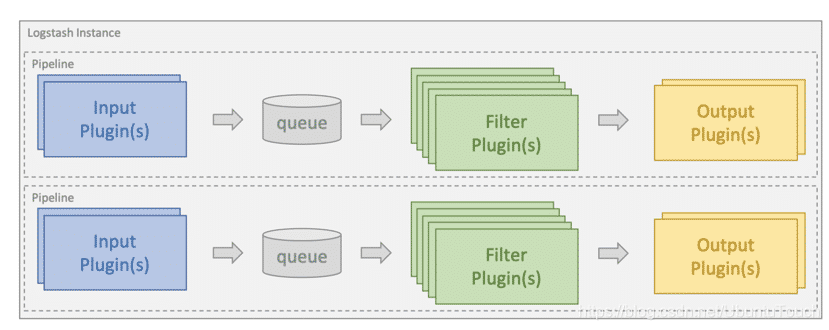
- 输入插件(input plugins)用于从给定的源系统中提取或接收数据。
- 过滤器插件(filter plugin)用于对传入事件应用转换和丰富。
- 输出插件(output plugin)用于将数据加载或发送到给定的目标系统。
Logstash 通过运行一个或多个 Logstash 管道作为 Logstash 实例的一部分来处理 ETL 工作负载。
Logstash 包含3个主要部分: 输入(inputs),过滤器(filters)和输出(outputs)。 你必须定义这些过程的配置才能使用 Logstash,尽管不是每一个都必须的。在有些情况下,我们可以甚至没有过滤器。在过滤器的部分,它可以对数据源的数据进行分析,丰富,处理等等。
在输出的部分,我们甚至可以有多于一个以上的输出。
在下面的图中,我们可以看到一些常见的 inputs, filters 及 outputs:
beats
简介
beats主要用于采集数据
Beats 平台其实是一个轻量性数据采集器,通过集合多种单一用途的采集器,从成百上千台机器中向 Logstash 或 ElasticSearch 中发送数据。
通过 Beats 包含以下的数据采集功能
- Filebeat:采集日志文件
- Metricbeat:采集指标
- Packetbeat:采集网络数据
如果使用 Beats 收集的数据不需要任何处理,那么就可以直接发送到 ElasticSearch 中。但是,如果们的数据需要经过一些处理的话,那么就可以发送到 Logstash 中,然后处理完成后,在发送到 ElasticSearch,最后在通过 Kibana 对我们的数据进行一系列的可视化展示。
filebeat
Filebeat 是一个轻量级的日志采集器
当你面对成百上千、甚至成千上万的服务器、虚拟机和容器生成的日志时,请告别SSH吧!Filebeat 将为你提供一种轻量型方法,用于转发和汇总日志与文件,让简单的事情不再繁华,关于 Filebeat 的记住以下两点:
- 轻量级日志采集器
- 输送至 ElasticSearch 或者 Logstash,在 Kibana 中实现可视化
用于监控、收集服务器日志文件
流程如下
- 首先是 input 输入,我们可以指定多个数据输入源,然后通过通配符进行日志文件的匹配
- 匹配到日志后,就会使用 Harvester(收割机),将日志源源不断的读取到来
- 然后收割机收割到的日志,就传递到 Spooler(卷轴),然后卷轴就在将他们传到对应的地方
Filebeat主要由下面几个组件组成:harvester、prospector 、input
harvester
- 负责读取单个文件的内容
- harvester 逐行读取每个文件(一行一行读取),并把这些内容发送到输出
- 每个文件启动一个 harvester,并且 harvester 负责打开和关闭这些文件,这就意味着 harvester 运行时文件描述符保持着打开的状态。
- 在 harvester 正在读取文件内容的时候,文件被删除或者重命名了,那么 Filebeat 就会续读这个文件,这就会造成一个问题,就是只要负责这个文件的 harvester 没用关闭,那么磁盘空间就不会被释放。
prospector
- prospector 负责管理 harvester 并找到所有要读取的文件来源
- 如果输入类型为日志,则查找器将查找路径匹配的所有文件,并为每个文件启动一个 harvester
- Filebeat 目前支持两种 prospector 类型:log 和 stdin
- Filebeat 如何保持文件的状态
- Filebeat 保存每个文件的状态并经常将状态刷新到磁盘上的注册文件中
- 该状态用于记住 harvester 正在读取的最后偏移量,并确保发送所有日志行。
- 如果输出(例如 ElasticSearch 或 Logstash )无法访问,Filebeat 会跟踪最后发送的行,并在输出再次可以用时继续读取文件。
- 在 Filebeat 运行时,每个 prospector 内存中也会保存的文件状态信息,当重新启动 Filebat 时,将使用注册文件的数量来重建文件状态,Filebeat将每个harvester在从保存的最后偏移量继续读取
- 文件状态记录在data/registry文件中
input
- 一个 input 负责管理 harvester,并找到所有要读取的源
- 如果 input 类型是 log,则 input 查找驱动器上与已定义的 glob 路径匹配的所有文件,并为每个文件启动一个 harvester
- 每个 input 都在自己的 Go 例程中运行
- 下面的例子配置Filebeat从所有匹配指定的glob模式的文件中读取行
filebeat.inputs: - type: log
paths: - /var/log/*.log
- /var/path2/*.log
Module
前面要想实现日志数据的读取以及处理都是自己手动配置的,其实,在 Filebeat 中,有大量的 Module,可以简化我们的配置,直接就可以使用,如下:
./filebeat modules list可以看到,内置了很多的 module,但是都没有启用,如果需要启用需要进行 enable 操作:
#启动
./filebeat modules enable nginx
#禁用
./filebeat modules disable nginx 可以发现,nginx的module已经被启用。
Metricbeat
Metricbeat 是一个轻量性指标采集器,用于从系统和服务收集指标。Metricbeat 能够以一种轻量型的方式,输送各种系统和服务统计数据,从 CPU 到内存,从 Redis 到 Nginx,不一而足。
- 定期收集操作系统或应用服务的指标数据
- 存储到 Elasticsearch 中,进行实时分析
Metricbeat组成
Metricbeat 有2部分组成,一部分是 Module,另一个部分为 Metricset
- Module:收集的对象:如 MySQL、Redis、Nginx、操作系统等
- Metricset:收集指标的集合:如 cpu、memory,network等
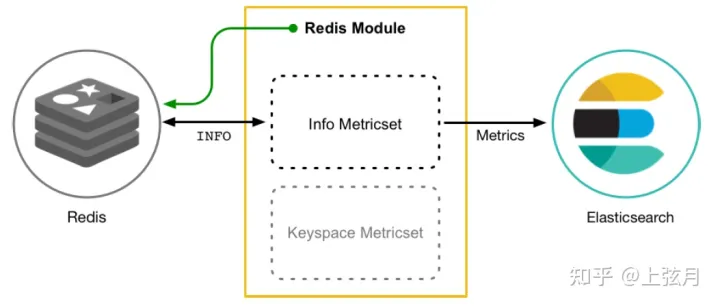
以 Redis Module为例,我们查看一下它的组成结构如下所示:
一文带你了解轻量性日志采集器Beats的使用 - 知乎 (zhihu.com)
Logstash:Logstash 入门教程 (一)_Elastic 中国社区官方博客的博客-CSDN博客_logstash教程