常见的查找
查找表
静态表查找
只作查找操作的查找表.它的主要操作有:
- 查询某个特定的数据元素是否在查找表中
- 检索某个特定的数据和各种属性
动态查找表
Dynamic search table
在查找过程中同时插入查找表中不存在的数据元素,或者从查找表中删除已经存在的某个元素.显然动态表的操作就俩个
- 查找时插入元素
- 查找时删除元素
为了提高查找效率我们需要专门为查找操作设置数据结构,这种面向查找操作的数据结构称为查找结构
从逻辑上来说,查找所基于的数据结构是集合,集合中的记录之间没有本质关系.可是想要获得较高的查找性能,我们就不能不改变数据元素之间的关系,在存储时可以查找集合组织成表树等结构
例入,对于静态查找表来说,我们不妨用线性表结构来组织数据,这样可以使用顺序查找算法,如果再对关键词排序,则可以应用折半查找等技术进行高效的查询
如果是需要动态的查找,则会复杂一些,可以考虑二叉树的查找技术
另外,还可以用散列表结构来解决一些查找问题
顺序表查找
顺序表查找(sequential search)又叫线性查找,是最基本的查找基础:从表中第一个或者最后一个记录开始,逐个进行记录和关键字和给定值的比较,若某个记录的关键字和给定值相等,则查找成功,找到所查的记录,如果到最后一个记录,和关键字比较都不等时,则表中没有所查的记录
对于这种顺序查找算法来说,时间复杂度为O(n)
很显然顺序查找技术缺点很大,n很大的时候,查找效率极为低下,不过优点也有,这个算法非常简单,对静态表的记录没有任何要求,在一些小型数据查找时,是可以适用的.
另外,也正有余查找概率的不同,我们完全可以将容易找到的记录放在前面,不常用的记录放在后面,效率就可以大幅度提高
有序表查找
我们如果仅仅是把书整理在书架上,找到一本书还是比较困难的,也就是刚才将的需要诸葛顺序查找.但如果我们在整理书架时,将图书按照书名的拼音排序放置那么找到一本书就相对容易了.说白了,对图书做了个有序的排列,一个线性表有序是,对于查找总是很有帮助的
折半查找
binary search技术,又称为二分查找.它的前提是线性表中的记录有序
基本思想:去中间记录作为比较对象,弱给定值与中间记录的关键字相等,则查找成功;弱给定值小于中间记录关键字,则中间记录的左半区继续查找,若给定值大于中间记录关键字,则在中间记录右边区继续查找,不断重复上述过程
不过折半查找的前提条件是有序表存储,对于静态查找表,一次排序后不再变化,这样的算法已经比较好了.但是需要频繁插入或删除操作的数据集来说,维护有序的排序会带来不小的工作量,不建议使用
差值查找
为什么一定要折半,而不是三分之一或者更多呢,比如在英语字典里查A开头的词和D开头的词真的会有人从中间找吗
同样的,比如要在取值范围0-10000之间100个元素从小到大均匀分布的数组中查找5,我们自然会考虑从下标较小的开始查找
那就是插值查找(Interpolation search)是根据关键词key与查找表中最大最小记录的关键字比较后的查找方法,其核心就在于插值的计算公式
low是最低下标为记录的首位,high是最高下标记录的末尾
mid=low+(high-low)*(key-a[low])/(a[high]-a[low]); //插值其核心在与插值计算公式key-a[low]/a[high]-a[low]
对于表比较大,而关键字分布比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好的多,反之,如果数组中分布极端不均衡的数据,用插值查找未必是很合适的选择
斐波那契查找
那还有没有其他办法,这办法查找和插值查找都未必是最合适的做法,我们在介绍一种有序查找,斐波那契查找(fibonacci search),它是利用了黄金分割的原理来实现的
斐波那契查找技术在二分查找的基础上根据斐波那契数列进行分割的,仅仅改变了mid的位置
F代表的是斐波那契数列F[K]=F[k-1]+F[k-2]的性质,可以得到F[k-1]=(F[k-1]-1)+(F[k-2]-1)+1
所以说,只要顺序表的长度为F[k]-1,则可以将该表分为F[k-1]-1和F[k-2]俩段,如上图所示,中间的位置为midlow+F[k-1]-1
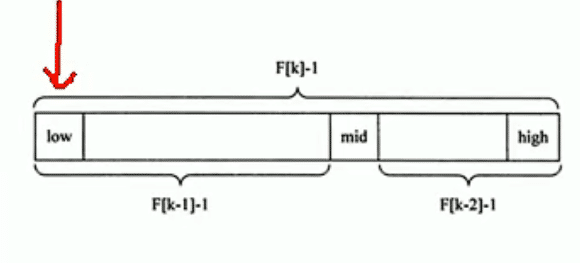
类似的,每一字段也可以用相同方式分割
线性索引查找
我们前面讲的几种比较高效的查找方法都是基于有序的基础上的,但事实上,数据集可能增长的非常快,例如,例如大型网站帖子和回复总数也可能是海量的数据,这种记录全部是按照当中某个关键字有序,其时间代价也是非常高昂的,所以这种数据通常都是按先后顺序存储
稠密索引
稠密索引指在线性索引中,将数据集中每个记录对应一个索引项
因为可能会存在成千上万的数据,因此对于稠密索引来说,索引一定是按照关键码有序的排列
可以用折半,插值,斐波那契数列去查询结果
但是如果数据集非常大,比如上亿,那就意味着索引也得同样的数据集长度规模,对于内存有限的计算机来说,可能就需要反复去访问磁盘
查找性能反而大大下降了
分块索引
想一想图书馆是如何藏书的。显然不会是顺序拜访后,给我们一个稠密索引表去查,如何找到书再给你
稠密索引因为索引项与数据的记录个数相同,所以空间代价很大。为了减少索引的个数,我们可以对索引进行分块,使其分块有序,如何再对每一块简历一个索引项,从而减少索引个数
分块有序,是把数据的记录分成了若干块,并且这些块需要满足俩个条件
块内无序,每一块的内存记录不需要有序,当然如果能让快内有序对于查找来说更为理想,不过这就要付出大量的时间空间的代价,因此我们通常不要求快内有序
块间有序,例如,要求第二块所有记录的关键字均要大于第一块中的所有记录,因为只有快间有序,才有可能再查找时带来的效率
对于有序的数据集,将每块对应一个索引项,这种索引项方法叫做分块索引,我们定义的分块索引项结构分三个数据项
- 最大关键码,存储每一块中最大的关键字,这样的好处就是可以使得在它只会的下一块中的最小关键字也能比这一块最大的关键字要大
- 存储了块中的记录个数,以便于循环使用
- 用于指向块首数据元素的指针,便于开始堆这一块中的记录进行遍历
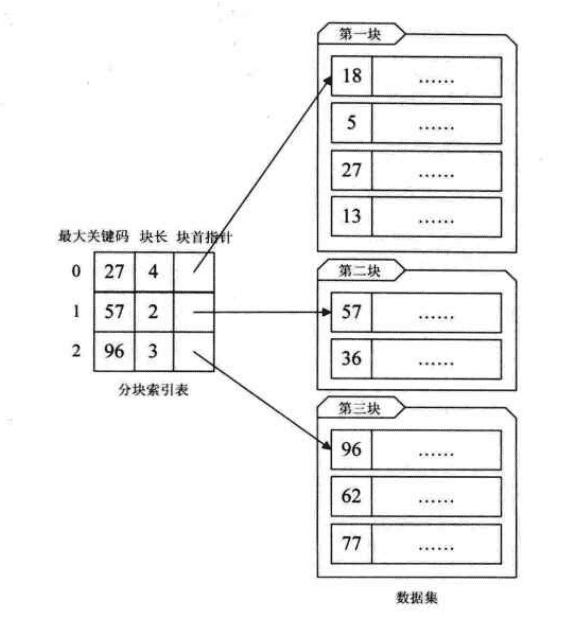
在分块索引表中查找,就是分俩步进行
- 在分块索引表中查找要差的关键字所在的块,由于分块索引表是块箭有序的,因此可以用提到过的算法,很快得到结果
- 根据首指针找到相应的块,并在块中顺序查找关键码。因为块中可以是无序的,因此只能顺序查找
查找表
静态表查找
只作查找操作的查找表.它的主要操作有:
- 查询某个特定的数据元素是否在查找表中
- 检索某个特定的数据和各种属性
动态查找表
Dynamic search table
在查找过程中同时插入查找表中不存在的数据元素,或者从查找表中删除已经存在的某个元素.显然动态表的操作就俩个
- 查找时插入元素
- 查找时删除元素
为了提高查找效率我们需要专门为查找操作设置数据结构,这种面向查找操作的数据结构称为查找结构
从逻辑上来说,查找所基于的数据结构是集合,集合中的记录之间没有本质关系.可是想要获得较高的查找性能,我们就不能不改变数据元素之间的关系,在存储时可以查找集合组织成表树等结构
例入,对于静态查找表来说,我们不妨用线性表结构来组织数据,这样可以使用顺序查找算法,如果再对关键词排序,则可以应用折半查找等技术进行高效的查询
如果是需要动态的查找,则会复杂一些,可以考虑二叉树的查找技术
另外,还可以用散列表结构来解决一些查找问题
顺序表查找
顺序表查找(sequential search)又叫线性查找,是最基本的查找基础:从表中第一个或者最后一个记录开始,逐个进行记录和关键字和给定值的比较,若某个记录的关键字和给定值相等,则查找成功,找到所查的记录,如果到最后一个记录,和关键字比较都不等时,则表中没有所查的记录
对于这种顺序查找算法来说,时间复杂度为O(n)最坏
树
B树
b树(B-tree)是一种平衡多路查找树,2-3树和2-3-4树都是b树的特例.节点最大的孩子数目为B树的阶(order)因此,2-3树是3阶B树,2-3-4树是4阶B树
一个m阶的B树具有如下特性
- 如果根结点不是叶,则至少有俩颗字数
- 每一个非根的分支结点都有k-1个元素和k个孩子,其中[m/2]<=k<=m. 每一个叶子节点n都有k-1个元素其中[m/2]<=k<=m
- 所有的叶子节点都在同一层
b树的插入和删除方式与2-3树和2-3-4树相似,只不过阶数可能会很大而已
那么b树结构如何减少内寸和外村的交换次数呢?
我们的外存,比如硬盘,是将所有信息分割成大小相等的页面,每次硬盘的读写都是一个或多个完整的页面,对于一个硬盘来说,一页的长度可能是211-214个字节
在同一个典型的B树应用中,要处理的硬盘数据量可能很大,因此无法一次全部装入内存.因此我们会对b树进行调整,使得B树的阶数(活节点的元素)与硬盘存储页面大小相匹配.比如说一颗B树的阶为1001(即1个节点包含10000个关键字,高度为2,它可以存储超过10亿个关键字)我们只需要让根节点持久保留在内存中,那么在这棵树上,寻找某一个关键字至多需要俩次硬盘的读取即可.
通过这种方式,在有限的内存的情况下,每一次磁盘访问我们都可以获得最大数量的数据.由于B树节点可以具有B二叉树多得多的元素,所以与二叉树的操作不同,它们减少了必须访问节点和数据块的数量,从而提高了性能.可以说b树的数据结构是为内外存的数据交互准备的
B+树
尽管前面我们已经讲了B树的诸多好处,但其实它还是有缺陷的,对于数据结构来说,我们都可以通过中序遍历来顺序查找树中的元素,这一切都是在内存中进行
可是在B树结构中,我们往返于每个节点之间也就意味着,我们必须在硬盘之间进行多次访问,
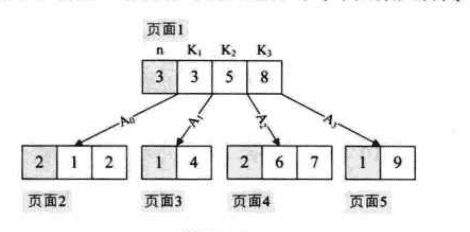
如图所示,我们如果要中序遍历这颗B树,假设每个节点都属于磁盘不同的页面,我们为了中序遍历所有元素,页面2->页面1->页面3->页面1->页面4->页面1->页面5
而且我们每次经过节点遍历是,都会对节点中的元素进行一次遍历,这就非常糟糕。有没有可能让遍历时每个元素只访问一次呢
B+树是应文件系统所需而出的一种b树的变形
在B树中,每一个元素在该树中只出现一次,有可能在叶子节点上,也有可能在分支节点上。而在B树中,出现在分支节点中的元素会被当做它们在改分支节点位置的中序后继者(叶子节点)中再次列出。另外,每一个叶子节点都会保存一个指向后叶子节点的指针
一颗m阶的B+树和m阶的B树差异在于
- 有n颗字数的节点中包含有n个关键字
- 所有的子节点包含全部关键信息及指向含这些关键字记录指针,叶子节点本身依关键字的大小自小而大顺序链接
- 所有分支节点可以看成索引,节点中仅含有其字数中最大(或最小)的关键字
这样的数据结构最大的好处在于,如果是随机查找,我们就从根节点出发,与B树的查找方式不同,只不过即使在分支节点找到了待查找的关键字,它也只是用来索引的,不能提供实际记录的访问,还是需要达到包含此关键字的终端节点
如果我们是需要从最小关键字进行从小到大的顺序查找,就可以从最左侧的叶子节点出发,不经过分支节点,而是沿着向峡一叶子的指针就可以遍历所有关键字。
B+树的结构特别适合带有范围的查找,B+树的插入,删除过程也都与B树类似,只不过插入和删除的元素都是在叶子节点上进行而已