Hadoop
简介
大数据
大数据(BigData):指无法在一定时间范围内用常规软件工具进行捕捉,管理和处理的数据集合
大数据主要解决海量数据的采集,存储和分析计算问题
特点
- volume 大量
- Velocity:高速
- Variety 多样
- value 低价值密度
hadoop
hadoop是一个由apache基金会开发的分布式系统基础架构
主要解决海量数据的存储和分析计算问题
广义上来说,hadoop通常指的是更广泛的概念 hadoop生态圈
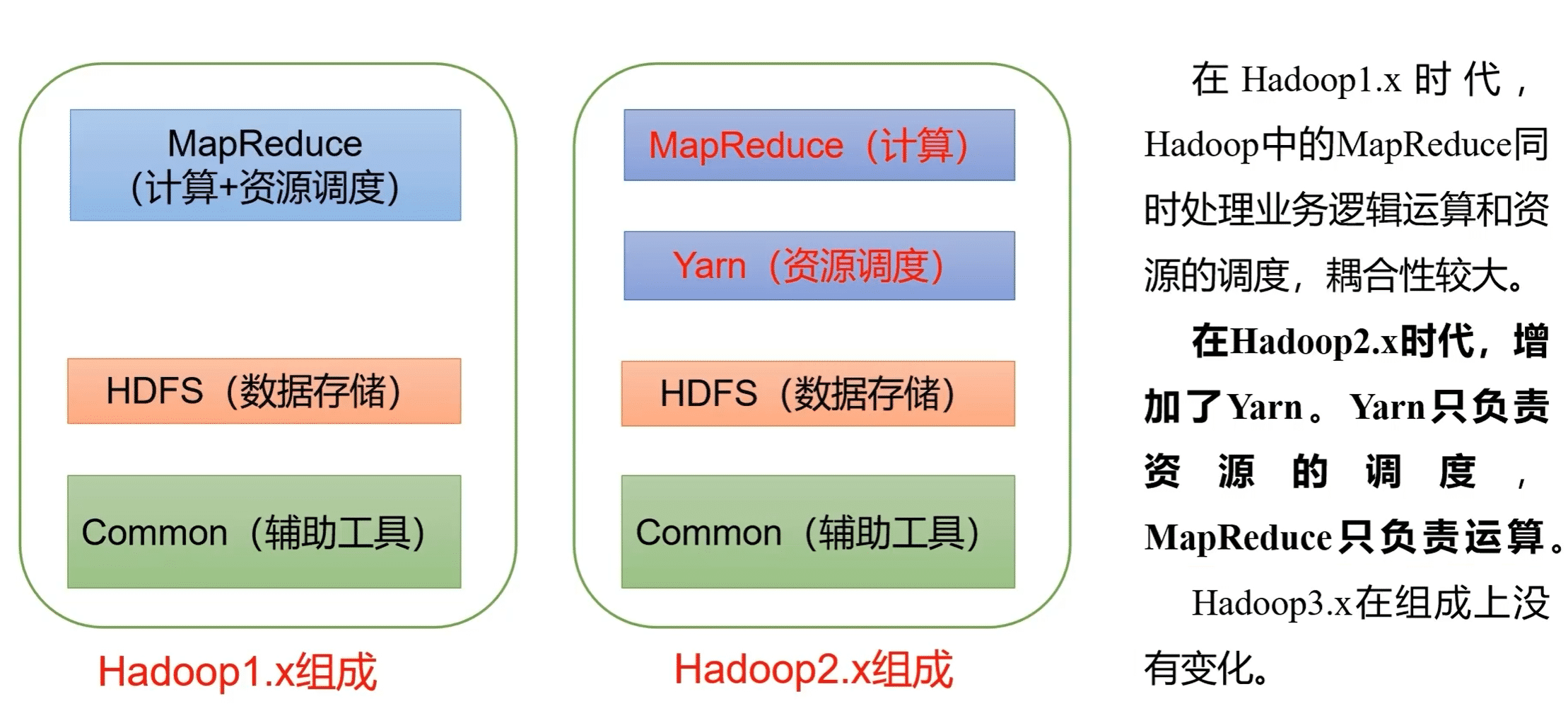
hadoop中有三大发新版本
- apche:最基础的版本对入门学习最好
- Cloudera:内部集成了许多大数据框架,对应产品CDH
- hortnworks:文档较好,对应产品HDP
Hortonworks,现在已经被Cloudera公司收购,退出新的品牌CDP
优势
- 高可靠性:Hadoop底层维护多个数据副本,所以即使某个Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失
- 高扩展性:在集群间分配任务数据,可以方便的扩展数以千计的节点
- 高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度
- 高容错性:能够自动将失败的任务重新分配
组成
HDFS
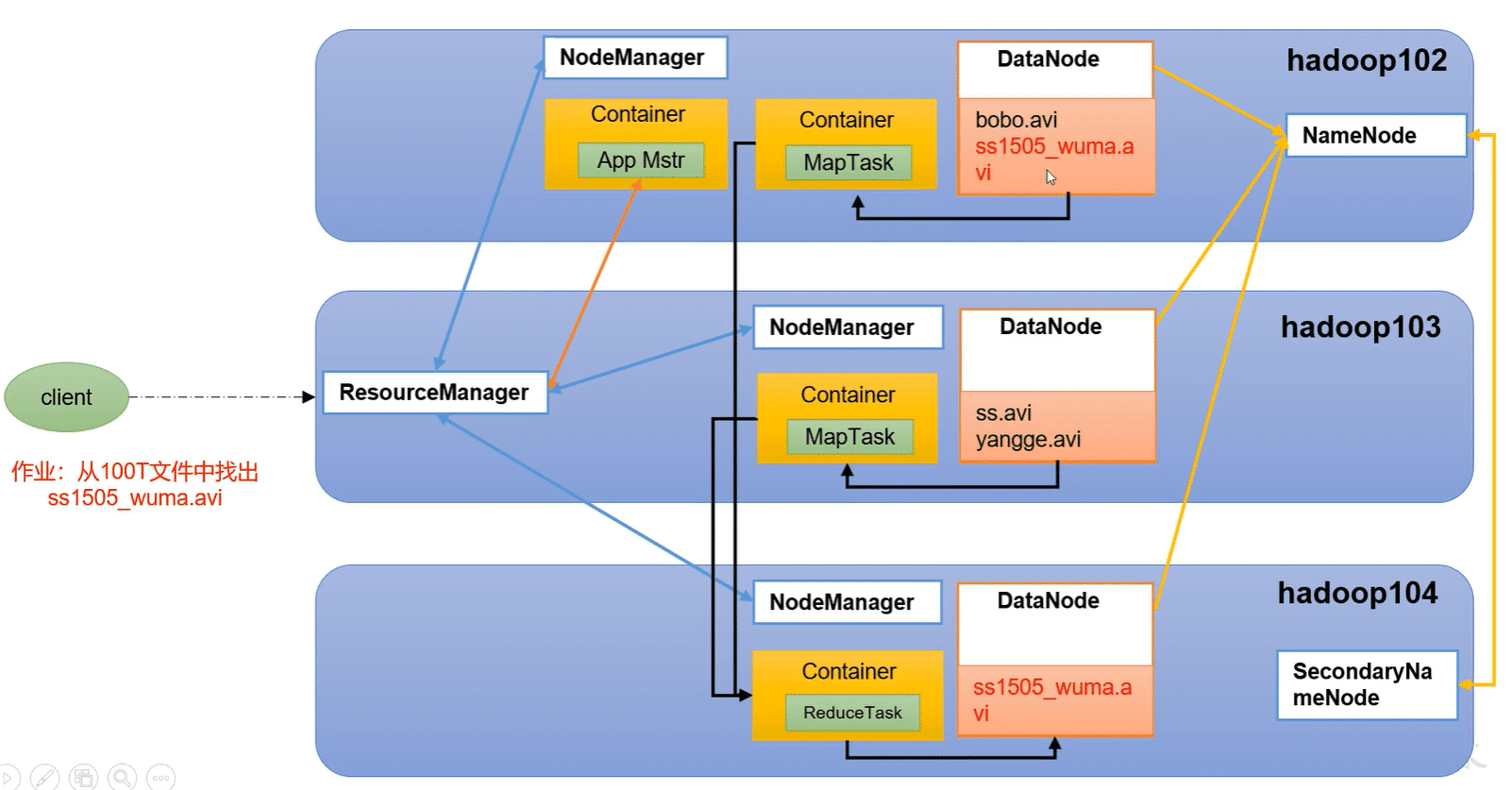
简称HDFS(Hadoop Distributed file System),是一个分布式文件系统
NameNode:存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在的dataname等
DataNode:在本地文件系统存储文件块数据,以及块数据的校验和
Secondary NameNode每隔一段时间对NameNode元数据备份
Yarn概述
ResourceManager(RM):整个集群资源(内存,cpu等)的管理者
nodeManager(NM):单节点服务器资源老大
ApplicationMaster(AM):单个运行任务的管理者
Container:容器,相当一台独立的服务器,里面封装了任务运行所需要的资源,如内存CPU磁盘网络等
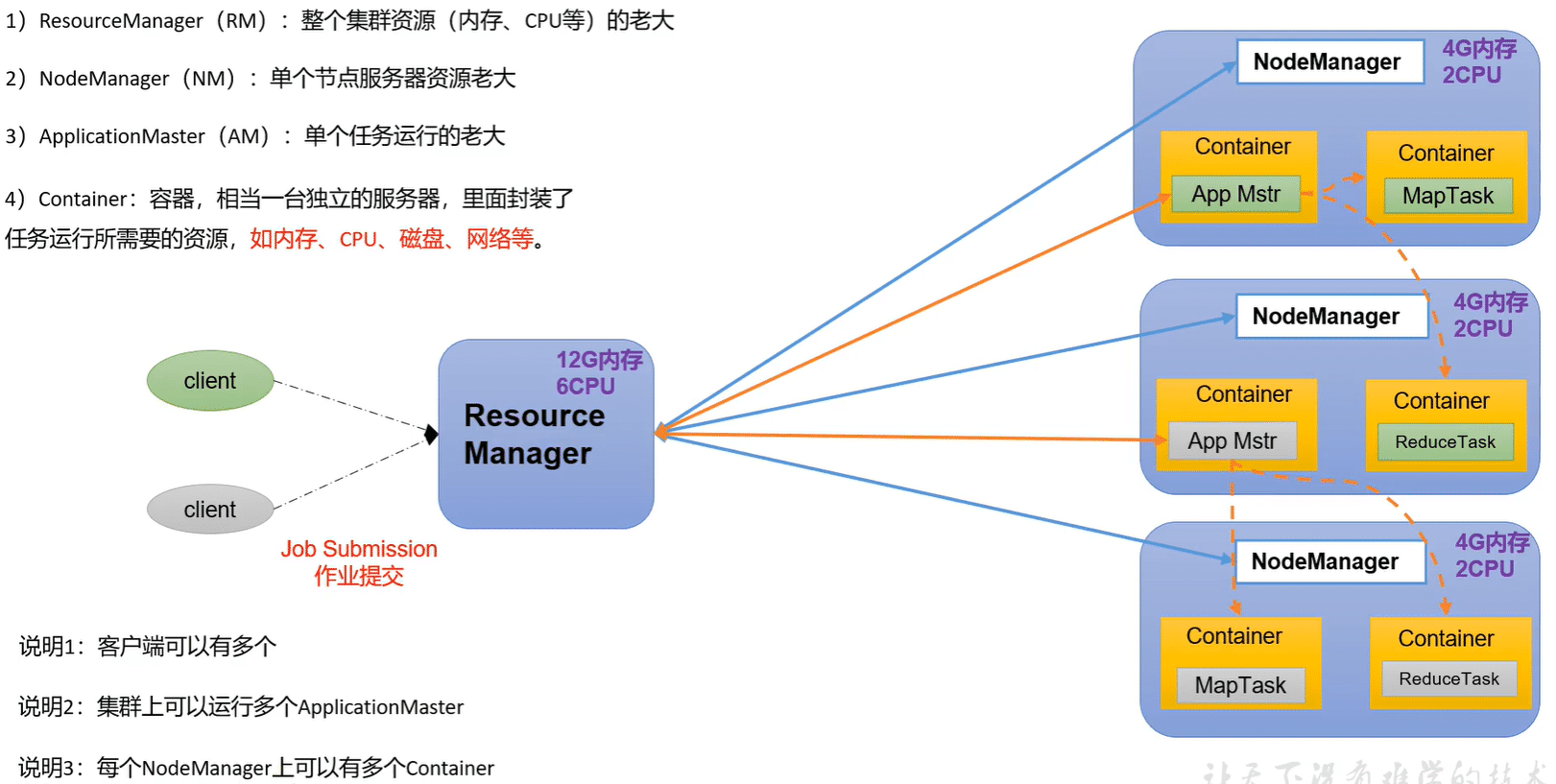
一个Container默认的内存是1-8g
MapReduce
MapReduce将计算阶段分为俩个阶段Map和Reduce
- map阶段并行处理数据
- Reduce阶段对map结果进行汇总
体系
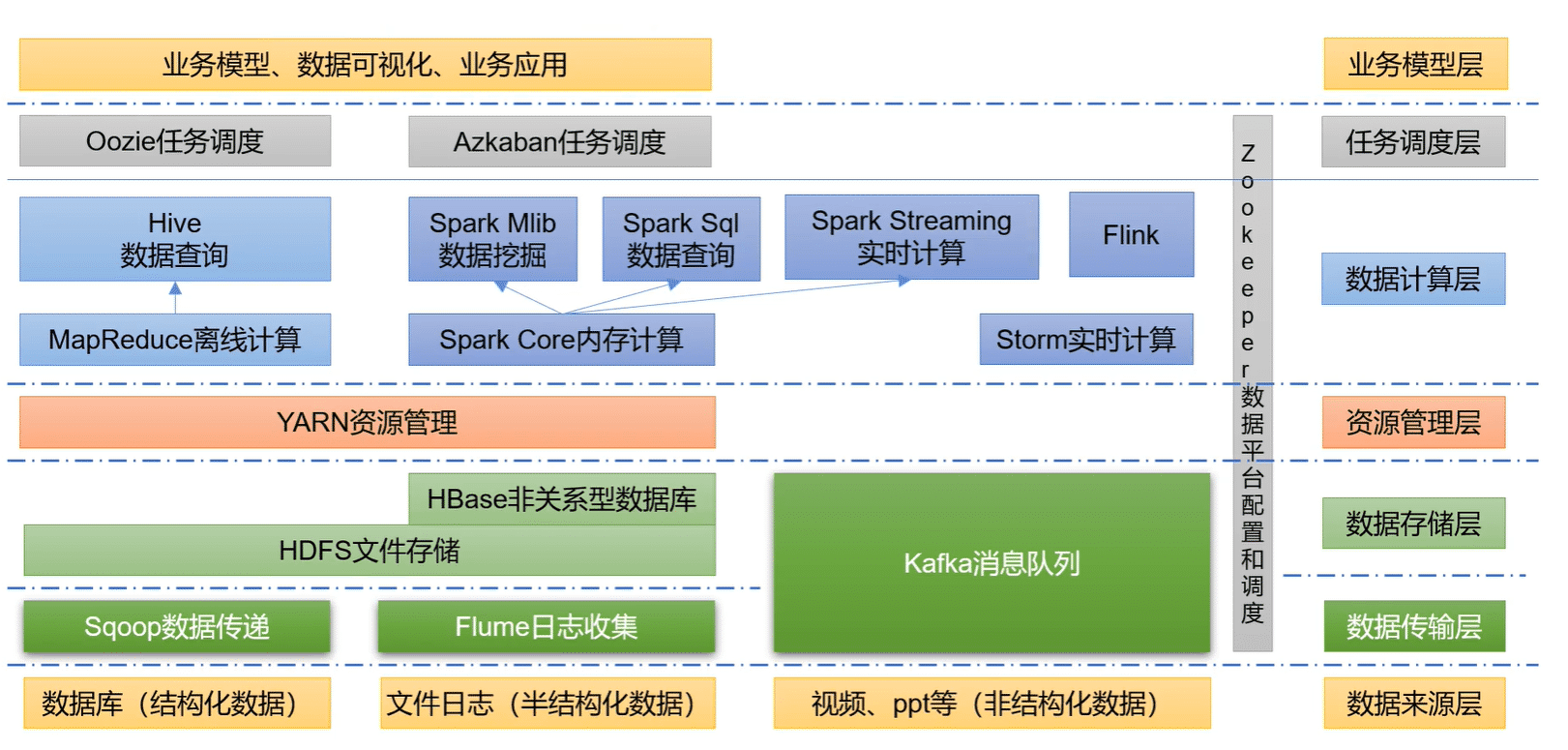
大数据生态体系