hotSpot的算法细节实现
3.4.1根节点 枚举
我们可以从可达性分析算法中从GC Roots集合找引用链这个操作作为介绍虚拟机高效实现的第一个例子.固定可以作为GC Roots的节点主要在全局性的引用(例如常量或者静态属性)与执行上下文(列入栈帧中的本地变量表)中,监管目标明确,但查找过程中要做到高效并非一件容易的事情,现在java应用越做越庞大,光是方法区的大小就长有数百上千兆,厘米哦按的类,常量等更是恒河沙数,若要诸葛检查以这里为起源的引用肯定得消耗不少时间.
迄今为止,所有收集器在根节点枚举这一步骤都是必须暂停用户线程的,因此毫无疑问所有收集器在根节点枚举的时候都是必须暂停用户线程的,因此毫无疑问根节点枚举与之前体积的内存碎片整理一样会面临STW的困扰.现在可达性分析算法耗时最长的查找因用力按的过程已经可以做到与用户线程一起并发,但根节点枚举始终还是必须在有个能保障一致性的快照中才得以进行,这里一致性的意思就是整个枚举期间执行子系统看起来就像被冻结在某个时间点上,不会出现分析过程中,根节点集合的对象还在不断变化的情况,若这点不能满足的话,分析结果准确性也就无法保证.这是桃枝垃圾收集过程必须停顿所有用户线程的其中一个重要原因,即便是号称停顿时间可控,或者几乎不会发生停顿的CMS,G1,ZGC等收集器,枚举更根节点也是必须要停顿的.
由目前主流的java虚拟机使用的都是准确式垃圾收集,所有当用户线程停顿下来了之后,其实并不需要一个不漏的检查完所有执行上下文和全局引用位置,虚拟机应当是有办法直接得到哪些地方存放着对象引用的.在hotspot的解决方案里,是使用一组称为oopMap的数据结构来达到这个目的.一旦类加载动作完成的时候,hotspot就会把对象内什么偏移量上是什么类型数据计算出来,在即时编译过程中,也会在特定的位置记录下栈里和寄存器里哪些位置是引用.这样收集器扫描的时候可以直接得知这些信息了,并不需要真正一个不漏的从方法区等GCRoots开始查找.
3.4.2安全点
在OopMap的协助下,hotspot可以快速正确地完成GC Roots枚举,但是一个很现实的问题随之而来:可能导致引用关系的变化,或者说导致OopMap内容变化的指令非常多,如果每一天指令都声称对应的OopMap,那将会需要大量的额外存储空间,这样垃圾手机伴随而来的空间成本就会变得无法忍受的高昂.实际上hotSpot也的确没有为每条指令都声称OopMap,前面已经提到,只是在特定的位置记录了这些信息,这些位置被称为安全点.有了安全点的设定,也就决定了用户程序执行时并非在代码流的任意位置都能够停顿下来开始垃圾收集,而是强制要求必须到安全点后才能暂停.因此安全点的选定既不能太少让垃圾收集器等待时间过长,也不能太过分以至于过跑分以至于过分增大运行时的内存负荷.安全点位置的选举基本上是以,是否具有让程序长时间执行的特性而标准进行选定的,因为每条指令执行的时间都非常短暂,程序不太可能因为质量长度太长这样的原因而长时间执行,长时间执行的最明显特点就是指令序列的复用,列入方法调用,循环跳转,异常跳转都属于指令序列复用,所以只有这些功能的指令才会产生安全点.
对于安全点,另外一个需要考虑的问题是,如何在垃圾收集发生时让所有线程都跑到最近的安全点,然后停顿下来.这里有俩种方案可供选择
- 抢先式中断:不需要线程的执行代码主动去配合,在垃圾收集器发生时,系统首先把所有用户线程全部中断,如果又发现中断的地方不在安全点上,就恢复这条线程让它一会再重新中断,直到跑到安全点上.(现在几乎没有虚拟机使用)
- 主动式中断:的思想是当垃圾收集需要中断线程的时候,不直接对线程操作,仅仅简单地设置一个标志位,各个线程执行过程中会不停地主动去轮询这个标志,一旦发现中断标志为真时就自己再最近的安全点上主动中断挂起.轮询标志的地方和安全点是重合的,另外还有加上所有创建对象和其他需要在java堆中分配内存的地方,这是为了检查是否将要发生垃圾收集,避免没有足够内存重新分配对象
3.4.3安全区域
使用安全点的设计似乎完美解决如何停顿用户线程,让虚拟机进入垃圾回收状态的问题了,但实际情况却不一定.安全点机制保证了程序执行时,在不太长的时间内就会遇到可进入垃圾收集过程的安全点.但是,程序不执行的时候呢?但是,程序"不执行"的时候呢,所谓的程序不在线就是没有分配处理器时间,电线场景就是用户线程处于sleep状态或者clocked状态,这时候线程无法响应虚拟机的中断请求,不能再走到安全的地方去中断或挂起自己,虚拟机也显然不可能程序等待线程重新被激活分配处理器时间.对于这种情况,就必须引入安全区域(Safe Region)来解决.
安全区域是指能够确保在某一段代码片段中,引用关系不会发生变化,因此,在这个区域中任意地方开始垃圾收集都是安全的.我们也可以吧安全区域看作是被扩展拉伸了的安全点。
当用户线程执行到安全区域里面的代码时,首先会标识自己已经进入了安全区域,那样当这段时间里虚拟机要发起垃圾收集时,就不必去管这些生命在自己安全区域内的线程了。当线程要离开安全区域时,它要检查虚拟机是否已经完成了根节点的枚举(或者垃圾收集过程中其他需要暂停用户线程的阶段),如果完成了,那线程就当做没事发生过,继续执行;否则它就必须一直等待,直到收到可以离开安全区域的信号为止。
3.4.4记忆集与卡表
讲解分代收集理论的时候,提到了未解决对象跨带引用所带来的问题,垃圾收集器在新生代中简历了名为记忆集(remembered Set)的数据结构,用以避免吧整个老年代加进GC Roots扫描范围。事实上并不只是新生代,老年代之间才有跨带引用的问题,所有涉及部分区域手机行为的垃圾收集器,典型的如G1,ZGC和Shenandoah收集器都会面临同样的问题 ,因此我们有必要进一步清理记忆集的原理和实现方式,以便在后续章节里介绍几款最新的收集器相关知识时能更好的理解。
记忆集是一种用于记录非手机区域指向收集区域的指针集合的抽象数据结构。如果我们不考虑效率和成本的话,最简单的实现可以用非收集区域中所含有的跨带引用的对象数组来实现这个数据结构
这种记录全部喊跨带引用对象的实现方案,无论是 空间占用还是维护成本都相当高昂。而在垃圾收集的场景中,收集器秩序要通过记忆集判断出一块飞收集区域是否有指向收集区域的指针就可以了,并不需要料及这些跨带指针的全部细节。那设计这在实现记忆集的时候,便可以选择更为粗犷的力度来节省记忆集的存储和维护成本,下面举了一些可供选择的记录精度
- 字长精度:每个记录精确到一个机器字长该字包含了跨带指针。
- 对象精度:每个记录精度精确到一个对象,该对象里有字段含有跨带指针。
- 卡精度:没记录精确到一块内存区域,该区域内含有对象的跨带指针
其中,第三种卡精度所指的是用一种称为(Card Table)的方式去实现记忆集,这也是目前最常用的 一种记忆集实现形式,一些资料中甚至直接把它和记忆集混为一谈。前面定义中提到记忆集其实是一种抽象的数据结构,,之定义了记忆集的行为意图,并没有定义其行为的具体实现。卡表就是记忆集的具体实现,它定义了记忆集的精度,与堆内存的关系映射等。关于卡表与记忆集的关系,读者不妨按照java语言中hashmap与map的关系来类比理解
卡表最简单的形式可以只是一个字节数组,该数组的每一个元素都对应着其标识的内存区域中一块特定大小的内存块,这个内存块被称作“卡页”。一般来说,卡页大小都是以2的N次幂的字节数,HotSpot中使用的卡页是2的9次幂,即512字节(之所以使用byte数组而不是bit数组主要是速度上的考量,现代计算机硬件都是最小按字节寻址的,没有直接存储一个bit的指令,所以要用bit的话就不得不多消耗几条shift+mask指令。
一个卡页的内存中通常包含不止一个对象,只要卡页内有一个(或更多)对象的字段存在着跨代指针,那就将对应卡表的数组元素的值标识为1,称为这个元素变脏(Dirty),没有则标识为0。在垃圾收集发生时,只要筛选出卡表中变脏的元素,就能轻易得出哪些卡页内存块中包含跨代指针,把它们加入GC Roots中一并扫描。
3.4.5写屏障
我们已经解决了如何使用记忆集来缩减GCRoots扫描范围的问题,但还没有 解决卡表元素如何维护的问题,列入他们何时变脏,谁来把它们变脏等。
卡表元素何时变脏的答案是很明确的,有其他分代区域中对象引用了本区域对象时,其对应的卡表就应该变脏,变脏的时间点原则上应该发生在引用类型字段赋值的那一刻但问题是如何变脏,即如何在对象赋值的那一刻去更新维护卡表呢?加入是解释执行的字节码,那相对好处理,虚拟机负责每条字节码的执行,有充分的介入空间;但在编译执行的场景中呢? 经过编译后的代码已经是纯粹的机器指令流了,这就必须找到一个在机器码层面的手段,把维护卡表的动作放到每一个赋值操作之中。
在hotspot虚拟机里是通过写屏障技术维护卡表状态的。在引用对象赋值的时候会产生一个环形的通知, 供程序执行额外的动作,也就是说赋值的前后都在写屏障的覆盖范畴内。在敷之前的部分的写屏障叫做写前屏障,在赋值之后的则叫做写后屏障。hotspot虚拟机的许多收集器都有使用到写屏障,但直至G1收集器出现之前,其他收集器都只用到了写后屏障。
应用写后屏障后,虚拟机就会为所有赋值操作生成相应的指令,一旦收集器在写屏障中增加了更新卡表操作,无论更新的是不是老年代对新生代对象引用,每次只要对引用进行更新,就会产生额外的开销,不过这个开销与Minor GC时扫描 整个老年代的代价相比还是低得多的。
除了写屏障的开销外,卡表在高并发场景还面临着“伪共享”问题。伪共享是处理办法底层细节时一直经常要考虑的问题,现代中央处理器的缓存系统中是以缓存行为单位存储的,当多线程修改互相独立的变量时,如果这些变量恰好共享同一个缓存行,就会彼此影响而导致性能降低,这就是伪共享的问题。
假设处理器的缓存大小为64字节,由于一个卡表元素占一个字节,64个卡表的元素将共享同一个缓存行。这64个卡表对应的卡页总的内存为32kb(64*512字节),也就是说如果不同线程更新的对象正海处于这32kb的内存区域,就会导致更新卡表时正好写入同一个缓存而影响性能。为了避免伪共享问题,一种简单的解决方案是不采用无条件的写屏障,而是先检查卡表标记,当只有该卡表元素未被标记过时才将其标记为变脏。
在JDK7之后,hotspot虚拟机增加了一个新参数-XX:+UseCondCardMark,用来决定是否开启卡表更新的条件判断。开启会增加一次额外判断的开销,但能避免伪共享问题,是否打开要根据应用实际运行情况来运行测试权衡。
3.4.6并发的可达性分析
在3.2届中曾提到了当前主流编程语言的垃圾收集器基本上都是依靠可达性分析算法来确定对象是否存活的,可达性分析算法理论上要求全过程都给予一个能保障一致性的快照中才能够进行分析,我这意味着必须冻结用户线程的运行。在根节点枚举这个步骤中,由于GcRoots相比起整个java堆中全部的对象毕竟还算极少数,切在各种优化技巧如OopMao的加持下,它带来的停顿已经是非常短暂且相对固定(不随堆容量增长而增长)的了。可从GcRoots再继续往下遍历对象图,这一步骤的时间就笔挺会与java堆容量直接成正比关系了:堆越大,存储的对象越多,对象图结构越复杂,要编辑更多对象而产生的停顿时间自然就更长,这听起来是理所当然的事情。
要解决并发扫描时对象小时的问题,有俩种解决方案:增量更新和原始快照
- 白色:表示对象没被收集器访问过
- 黑色,代表对象以及被收集器访问过,切这个对象所有的引用都扫描过
- 灰色:表示对象呗收集器访问过,但这个对象至少还存在一个引用没有被扫描过
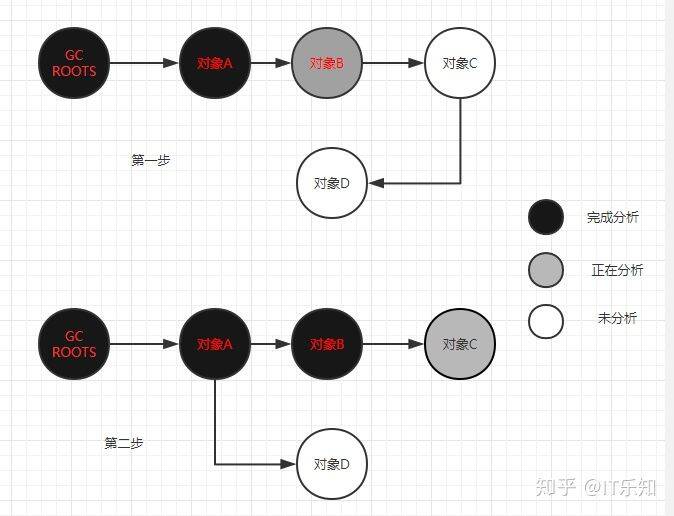
以上无论是对于引用关系记录的插入还是删除,虚拟机的记录操作都是通过写屏障实现的。在hotspot虚拟机中,增量更新和原始快照都有实际的应用,譬如CMS是基于增量更新来做并发标记的,G1,SHeanandoah则是用原始快照来实现。
- 增量更新:档黑色对象插入新的指向白色对象的引用关系时,就将这个新插入的引用记录下来,等并发扫描结束后,再将这些记录过的引用关系中的黑色对象为跟,重新扫描一次。这可以简化理解为,黑色对象 一旦插入了白色对象的引用后,它就变回灰色对象了。
- 原始快照:当灰色对象要删除指向白色对象的引用关系时,就将这个要删除的引用记录下来,在并发扫描结束后,再将浙西诶记录过的引用关系中的灰色对象重新为跟,重新扫描一次。这也可以简化理解为,无论引用关系删除与否,都会按照开始扫描那一刻 的对象图快照进行搜索。
以上无论是对引用关系的插入还是删除,都是通过写屏障来实现的。