机器学习绪论
绪论
绪论
机器学习正是这样一门学科,它致力于研究如何通过计算的首选,利用经验来改善系统自身的性能,在计算机系统中,经验通常以数据形式存在,因此机器学习所研究的主要内容,是关于计算机数据中产生模型(model)的算法,即学习算法(learning algorithm),有了学习算法我们把经验数据提供给它,它就能基于这些数据产生模型;在面对新的情况时(例如一个没抛开的西瓜)模型会给我们提供相应的判断,
基本术语
要进行机器学习先要有数据,假定我们收集了一批西瓜的数据例如(色泽=千百,根蒂=硬挺)每对括号是一个记录=的意思是取值为
这组记录合成一个数据集,每条记录都是关于对象的描述,属性上的取值例如乌黑,青绿,属性的张成空间称为属性空间,样本空间或输入空间
例如我们把色泽根蒂敲声作为三个坐标轴,则它们张成一个用与描述西瓜的三维空间,每个膝盖都可以在这个空间中找到自己的坐标位置,犹豫空间中的每一个点对应一个坐标向量,因此我们也把一个实例称为一个特征向量
一般地,另D={x1,x2,。。。xm}表示包含m个实例的数据集每个式例由d个属性描述,则每个师列是d维样本空间x中的一个向量,d称为样本xi的维数(dimensinality)
从提高数据中学得模型的过程称为学习或训练,这个过程通过执行某个学习算法来完成,训练过程中使用的数据称为训练数据,其中每个样本称为,训练数据
其中每个样本称为一个训练样本,训练样本组成的集合称为训练集。学得模型对应了关于数据的某种潜在的规律因此称为假设,这种潜在概率自身则称为真想或真实,学习过程就是为了找出或者逼近真相。
如果希望学得一个有帮助我们判断没剖开的瓜是不是好瓜的模型,仅有前面的示例数据显然是不够的,要建立这样的预测模型,我们需获得训练样本的结果信息,例如好瓜一般色泽青绿,声音浊响。拥有了标记信息的示例,则称为样例。一般地,用(xi,yi)表示第i个样例,yi属于Y,Y是所有标记的集合,亦称标记空间或输出空间
若我们预测的是离散值,例如好瓜,坏瓜,此类学习任务称为分类classification若预测的是连续值,例如西瓜成熟度0.95,0.37此类学习任务被称为回归regression。只涉及俩个类别的二分类任务,通常成其中一个类为正类另一个类为分类,设计多个类别的时,则称为多分类任务。一般地预测任务是希望通过训练集进行学习,建立一个输出空间x到输出空间y的映射f:X->Y,对二分类任务,通常令Y={-1,+1}或{0,1}对多分类任务|y|>2;对于回归任务,Y=R,R为实数集
学习模型后,使用其预测的过程称为测试,被预测的样本称为测试样本,例如在学得f后,对测试例x,看得到预测标记y=f(x)
我们还可以对西瓜做聚类(clustering),即将训练集中的西瓜分成若干组,每个组称为一个簇(cluster)这些自动形成的簇可能对应一些潜在的概念
根据训练数据是否有标记信息,学习任务大致分为俩大类,监督学习和无监督学习,分类和回归是监督学习代表,聚类则是后者的代表
需注意的是机器学习的目标是使学得的模型能够很好的适用于新样本,而不是仅仅在训练的样本上工作的很好,即便对于聚类这样的无监督学习,我们也希望学得的簇划分能够使用与没在数据集中出现的样本。学得模型适用于新样本的能力,称为泛化能力。具有很强泛化能力的模型能很好地适用于整个样本空间,于是尽管训练集通常知识样本空间很小的采样,我们仍希望它能够很好地反映出样本空间的特性,否则就很难期望在训练集上学得的模型能再整个样本空间中都工作的很好,通常假设样本空间中全体样本服从一个未知分布D,我们获得的每个样本都是独立地从这个分布上采样获得的,即独立同分布,一般而言,训练样本越多,我们得到关于D的信息越多,这样就越可能通过学习获得具有强泛化能力的模型
假设空间
归纳与演绎是科学推理的俩大基本手段。前者是从特殊到一般的泛化过程,即从具体的事实归结出一般性规律,后者则是从一般到特殊化的过程,即从基础原理推演出具体情况。例如在数学公里系统中,基于一组公理和推理规则推到出的相洽的订立,这是演绎,而从样例中学习显然是一个归纳的过程,因此被称为归纳学习
归纳学习有狭义与广义之分,广义的归纳学习大题相当于从样例中学习,而狭义的归纳学习则要求从训练数据中学得概念,因此概念学习或概念形成概念学习技术目前研究应用的都比较少,因为要学得泛化性能好且语义明确的概念实在是太困难了,现实常用的技术大多是黑箱模型。
如果仅仅把训练集中的瓜记住,今后再见到一模一样的瓜当然可以判断,但是对没见过的瓜,怎么办呢
我们可以把学习过程看做一个在所有假设组成的空间进行搜索的过程,搜索目标是找到与训练集匹配的假设,即能够将训练集的瓜判断正确的假设。假设的表示一旦确定,假设空间及其规模大小就能确定了。这里我们的假设空间由形如色泽根蒂,敲声可能的取值所形成的假设组成。
归纳偏好
同一个数据集中训练除了不同的模型,如何选择,机器学习算法过程中某种类型假设的偏好称为归纳偏好
任何一个有效的学习算法毕有其归纳偏好,否则它将被空间中看似在训练集上等效的假设缩迷惑,无法产生确定的学习结果。可以想象,如果没有偏好,我们西瓜学习算法产生的模型每次在尽显预测的时候随机抽选训练集上的等效假设,那么对于这个新瓜,学得模型时而高速我们它是好的时而高速我们它是不好的,这样的学习显然没有意义
归纳偏好可以看做学习算法自身在一个可能很庞大的假设空间对假设进行选择的启发式或价值观。那么也没用一般性的原则来引导算法确立正确的偏好吗。奥卡姆提到是一种常用的,自然科学研究中最基本的原则,即,若有多个假设与观察一致,则选最简单的那个
事实上,归纳偏好对应了学习算法本身缩做出的什么样的模型更好的假设,在具体的现实问题中,这个假设是否成立,即算法的归纳偏好是否与问题本身匹配,大多数时候直接决定了算法能否取得更好的性能
根据天下没有免费的午餐定理,无论算法多好在没有实际背景情况下都不优于随机胡猜。
所以,NFL定理最重要意义是,在脱离实际意义情况下,空泛地谈论哪种算法好毫无意义,要谈论算法优劣必须针对具体学习问题
模型的评估与选择
经验误差与过拟合
我们把样本数站总数的比例称为错误率,如果在m个样本中有个样本分类错误,则错误率E=a/m,相应的1-a/m称为精度,即精度=1-错误率一般我们把机器学习的实际预测输出与样本的真实输出之间的差异称为训练误差或经验误差。显然我们希望得到泛化误差较小的学习器。然而我们实现并不知道新样本是什么样,实际能做的是努力使经验误差最小化。很多情况下我们可以学得一个经验误差很小,在训练集上表现很好的学习器,例如对所有样本都分类正确,即分类错误率为0,分类精度百分百,但这并不是我们想要的学习器。
我们实际上希望的,是在新样本上表现良好的学习器。为了达到这个目的,应该从训练样本中尽可能学出使用与所有潜在样本的普遍规律,这样才能在遇到新样本的时做出正确的判别。然而机器学习把训练样本学得太好了的时候,可能把训练样本自身的一些特点当做了所有潜在样本都会有的一般性质,导致泛化能力下降,这种现象在机器学习中称为过拟合,与过拟合相对的是欠拟合。
在现实任务重,我们往往有多重学习算法可以选择,甚至对同一个学习算法,当使用不同的参数配置时,也会产生不同的模型。那么我们应该选用哪一种或参数配置呢?这就是机器学习中的模型选择问题。理想的解决方案当然是对候选模型的泛化误差进行评估,然后选择泛化误差最小的那个模型,然而如在上面讨论的,我们无法直接获得泛化误差,而寻俩内务差又犹豫过拟合存在不适合作为标准,那么在现实中如何进行模型评估呢?
评估方法
通常我们可以通过实验测试来对机器学习的泛化性能进行评估并进而做出选择,为此我们需要使用一个测试集,来学习机器学习对新样本的判别能力,然后一测试集上的测试误差,作为泛化误差的近似,通常我们假设测试样本也是从样本真实分布中独立同分布采样而得,但需注意的是,测试集应该尽可能与训练集互斥,即测试样本尽量不在训练集中出现,未在训练过程中使用过
就比如老师用10道题给同学练习,考试时又用10道题作为试卷,很明显不能判断同学学习情况
希望得到泛化性能强的模型,好比是希望同学们对课程学的很好,对知识获得了举一反三的能力
可是我们只有一个包含了m个样例的数据集,即要训练又要测试,怎么杨才能做到呢?答案啊是通过对数据进行适当的处理,从中产生训练集和S和测试集T
留出法
很简单的三七分
但是要注意训练集与测试集的同分布
或者进行随机划分,训练出多个模型,最后去平均值
k折交叉验证
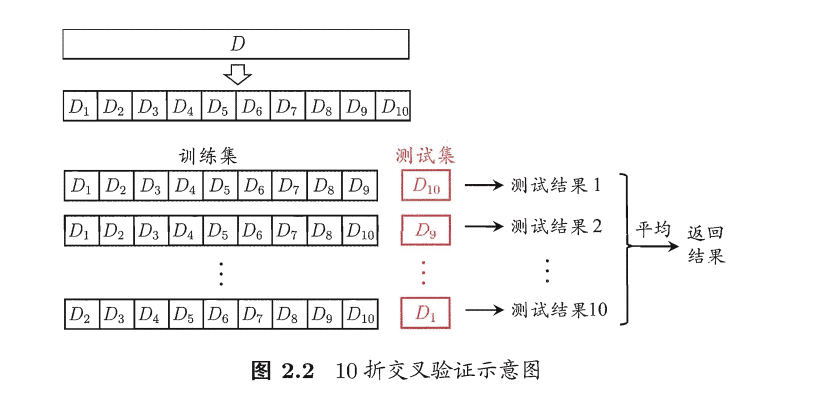
把训练集测试集氛围若干份,得到测试结果后,把所有的测试结果平均值返回
缺点:数据量较大的时候,对算力要求高
自助法
它直接一自主采样法为基础,给定包含m个样本的数据集,D',每次从D中挑选一个样本拷贝到D',然后再将该样本放回初始数据集D中,使得该样本再下次采样时仍有可能被采到,重复执行m次之后,就得到了包含m个样本的数据集D',这就是自主采样的结果,D中有一部分样本会在D'中多次出现,有一部份不出现,
即通过自主采样初始数据集中约有百分之6.8的样本未出现在采样数据集D'中。于是我们可以将D'用作训练集,DD'用作测试集这样实际评估的模型与期望评估的模型都是用m个训练样本,而我们仍有数据总量约1/3的没在训练集中出现的样本用于测试,这样的测试结果亦称,包外估计
自主算法在数据集较小,难以有效划分测试集,训练集时很有用,自助算法能从初始数据集中产生多个不同的训练集,这对集成学习方法有很大的好处,然而自主法产生的数据集改变了初始数据集的分布,这会引入估计偏差,因此,在初始数据量足够时,留出法和交叉验证法更常用一些。
调参与最终模型
大多数学习算法都有写参数需要设定,参数配置不同,学得模型的性能往往有显著区别,因此在尽显模型评估与选择时,除了要对使用学习算法进行选择,还需对算法参数进行设定,这就是我们通常说的参数调节或简称调参
调参和算法选择没有什么本质区别:对每种参数配置都训练出模型,然后把最好的模型的参数作为结果,这样的考虑基本是正确的。但是有一点需要注意i:学习算法的很多参数是在实数范围内取值,因此对每种参数配置都训练出来的模型是不可形的,现实中常用的做法是,对每个参数选一个范围和变化步长,。
例如在[0,0.2]范围内一0.05为步长,实际要评估的候选参数值有5个,最终是这5个后悬置中产生选定值,显然这样的选定的参数往往不是最佳值,但这是在计算开销和性能估计之间进行这种的结果,通过这个折中,学习过程才变得可行。事实上即便是在尽显这样的这种后,调参往往仍很困难。假定算法有3个参数,每个参数考虑5个后悬值,这样对每一组训练、测试集就有5的三次方=125个模型需要考察,很多强大的学习算法有大量参数需要设定,这导致最终模型性能有关键性影响。
给定包含m个样本的数据集D,在模型评估与选择中,犹豫需要留出一部分数据进行评估测试,事实上我们只使用了一部分数据训练模型。因此在模型选择完成后,学习算法和参数配置已选定,此时应该用数据集D重新训练模型,这个模型在训练过程中使用了m个样本,这才是我们最终提交给用户的模型
另外需要注意的是,我们通常把学得模型在实际使用中遇到的数据称为测试数据,为了甲乙区分,模型评估与选择用于评估测试的数据称为验证集,例如,在研究比对不同算法的泛化性能时,我们用测试集来判别效果来估计模型在实际使用时的泛化能力,而把训练数据另外划分为训练集和验证集,基于验证集上的性能来进行模型选择和调参。
简单来说验证集就是用来调参的
性能度量
对机器学习的泛化性能进行评估,不仅需要有效可行的实验估计方法,还需要有很亮模型泛化性能的标准,这就是性能度量。性能度量反应了任务的需求;这意味着模型的好坏是相对的,什么样的模型是好的,不仅取决于算法和数据,还决定于任务的需求
在预测任务重要评估学习器f的性能,就要把学习器预测结果与真实标记y进行比较,回归任务最常用的性能度量是均方误差。
错误率与精度
错误率与精度是,这是分类任务中最常用俩种性能度量,即适用于二分类任务,也适用于多分类任务。错误率是分类错误的样本数占样本总数的比例,精度则是分类正确的样本占样本总数的比例。

查准率,查全率与F1
错误率和精度虽然常用,但不能满足所有需求,例如,西瓜问题为例,家庭瓜农一车瓜,我们训练好的模型对这个西瓜有多少不是好瓜。或者所有好瓜中有多少比例被挑了出来,那么错误率显然就不够用了
类似的需求在信息检索web搜索等应用中经常出现,例如在信息检索中,我们经常会关心检索出的信息中有多少比例是用户感兴趣的,用户感兴趣的星系中有多少被检索出来了。查准率与查全率是更适合此类需求的性能度量
对于二分类问题,可将样例根据其真实类别与学习器预测类别组合划分为,真正比,假正比,真反比,假反比四种情况
查准率和查全率是一对矛盾的度量。一般来说,查准率高时,查全率往往偏低,差全率高时,查准率往往偏低。例如若希望将好瓜尽可能的多选出来,则可通过增加选瓜的数量来实现。如果将所有西瓜都选上,那么所有的好瓜必然都被选上了,但这样查准率就会较低,若希望选出西瓜中好瓜比例尽可能高,则可只挑选最有把握的瓜,这样就难免会漏掉不少好瓜,让查全率较低。通常只有在简单任务中,才能使得查全率和查准率都很高
平衡点就是这样一个度量(BEP),它是查准率=查全率时的取值
在一些应用中,对查准率和查全率的重视程度不同,例如在商品推荐系统重,为了尽可能减少打扰用户,更希望推荐内容确定是用户感兴趣的,此时查准率更加重要,在讨饭信息检索系统重,希望能尽可能少漏掉逃犯,此时查全率更加重要
BEP还是过于简化了一些,更常用的是F1度量

roc与auc
下面的太多了懒得记了ORZ